基于Transformer的车辆多模态轨迹预测方法
1.引言
轨迹预测是自动驾驶领域关注的热点。对周围车辆轨迹的精确预测可以辅助自动驾驶车辆做出合理的决策规划,进而实现车辆在异构高动态复杂多变环境中安全驾驶。在车辆交互场景中,由于驾驶员意图与环境的不确定性,车辆轨迹将呈现多模态属性,即在相同历史轨迹条件下,车辆的未来轨迹具有多种可能性。对车辆的多模态轨迹预测并保证预测的准确性与多样性是当前自动驾驶领域研究的重点与难点。
近年来,Transformer在多模态预测领域取得突破性进展,其特有的完全基于注意力机制模块能够充分挖掘高动态场景下车辆之间的交互关系并有效建模轨迹的多模态分布。在近年来的一些研究中,基于Transformer的多模态轨迹预测显示出比CNN,RNN等多模态预测模型更优的准确性与多样性。本文以基于Transformer的多模态车辆轨迹预测为主线,回顾近年来代表性的基Transformer的多模态轨迹预测的算法,最后对基于Transformer的多模态轨迹预测做出总结与展望。
2.Transformer框架
2017年,Waswani等人提出Transformer[1],这是一种完全基于注意力机制的模型。注意力机制是一种捕捉向量之间相关性的方法,既可以考虑全局又可以聚焦重点,其在捕获车辆之间交互信息有非常好的性能。
基于注意力机制的Transformer比经典的深度学习模型CNN[12]和RNN[2]具备如下优势。注意力机制可以解决基于CNN方法中可解释性差以及无法建模智能体间交互关系的问题。注意力机制可以解决基于RNN[2]方法中长距离依赖问题,可以有更好的记忆力,可以获取更长距离的信息。相较于基于 RNN的方法在第t时间步的隐藏状态Ht需要前一个时间步t-1的隐藏状态输出后才能处理,难以并行,Transformer模型可以实现并行计算, Transformer可以同时提取上下文信息,并且在信息传递过程中规避梯度爆炸或梯度遗忘问题。
Transformer框架主要包含编码器、解码器、注意力机制三个重要部分,以下具体介绍。

图 1:Transformer框架[1]缩进点积注意力机制,多头注意力机制
2.1编码器-解码器
编码器用于将历史轨迹和环境信息嵌入到上下文信息中并输入到Transformer中,其输入为车道信息,历史轨迹,车辆交互信息等,输出为具有这些信息的特征。编码器由N=6个独立层组成,每层有两个子层,分别是多头注意力和全连接前馈网络,子层通过残差结构连接后进行归一化输出,每层维度d_model=512确保输入输出维度不变。
解码器用于生成预测轨迹,其输入为编码器的输出,输出为预测轨迹。解码器由N=6个独立层组成,每层有三个子层,除了多头注意力和全连接前馈网络,还插入第三个子层,掩码多头注意力(Masked Multi-head attention),用于对编码器堆栈的输出执行多头注意,掩码用于未来时刻进行掩码处理,确保当前位置的预测不会依赖于未来位置。
2.2注意力机制
注意力机制用于建模车辆间交互关系。注意力机制将查询向量Q和一组键值对向量K-V映射到输出,输出值的加权和,权重则是通过Q和K相似度计算。Transformer框架主要由缩放点积注意力机制和多头注意力机制组成,缩放点积注意力机制中输入由向量query(dk),key(dk)以及value(dv)组成,如图2,QK向量通过点积处理计算相似度,通过比例因子sqrt(dk)(用来求dk的平方根)处理避免QK内积方差太大导致难以学习的情况,应用softmax函数获取权重来获得value的权重。掩码(Mask)处理避免解码器在训练是获取未来的信息影响预测。
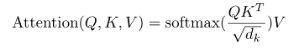
多头注意机制通过将Q,K,V分别线性投影到缩放点积注意机制中,投影h次后做h次注意力函数运算,通过并行计算,生成dv维输出value,将每一个输出值链接后再做一次投影得到最终value。通过多头注意机制,Transformer模型可以联合注意来自不同位置的不同子空间信息。
2.3 小结
在这一节中主要介绍了Transformer框架中三个主要部分,编码器,解码器,注意力机制的输入输出及其在轨迹预测中的用途。下一节中将对基于Transformer的多模态轨迹方法介绍。
3.基于Transformer的多模态轨迹预测方法
上一部分介绍了Transformer中编码器解码器结构,缩放点积注意机制,多头注意机制。这一部分中,将介绍近年来基于Transformer框架的可随场景变化的自适应调整的多模态方法。多模态轨迹预测旨在为处于异构复杂高动态环境中的目标车辆生成多条可能的且具有安全性的轨迹,由于不确定性的存在,目标车辆即使在相同场景下也有可能表现不同,因此这也是多模态轨迹预测面临的挑战。实现多模态预测的另一个挑战在于如何用有限的训练样本覆盖给定场景中所有可能的结果。多智能体轨迹预测需要在两个关键维度建模:(1)时间维度:将历史信息对智能体未来状态的影响建模 (2)社会维度:对每个智能体之间的交互关系建模。在时间维度层面,现有基于经典深度学习的模型CNN,RNN无法建模长时间序列,会导致时间信息丢失问题,基于Transformer可以通过将位置编码通过时间编码的形式保存长历史轨迹的信息。在社会维度层面,Transformer模型可以通过注意力机制建模人-车,车-车,车-环境之间的交互关系,可以通过分配权重的方式选择影响力最大的交互,以此为基础,Transformer可扩展到多智能体交互环境中。
现有基于概率的方法[3]和基于建议的启发式[4]的方法虽然可以通过添加规则的方式输出概率分布或通过添加具有强约束的锚点实现多模态轨迹预测,但是基于概率的方法过度依赖于先验分布和损失函数,容易出现优化不稳定或模式崩溃现象,基于建议的启发式方法过度依赖于锚点质量,不能保证生成多模态情况。基于Transformer的方法可以避免在设计先验分布和损失函数过程中大量的人工工作,同时可以更好的捕捉到轨迹预测的多模态性质,实现多模态轨迹预测。
Liu[5]等针对如何实现多模态轨迹预测,提出mmTransformer框架,该方法在Argoverse基准排行榜排名第一名,框架由三个独立的堆叠式的Transformer模型组成,分别聚合历史轨迹,道路信息以及交互信息。如图2所示,mmTransformer整体框架可由两部分组成,第一部分仅由运动提取器和地图聚合器分别对车辆的信息及环境信息进行性编码,不考虑交互信息,第二部分通过社会构造函数对临近信息进行聚合,并对车辆之间的依赖关系进行建模,整个过程是依照逻辑顺序,即社会关系是基于每个车辆特征构建的。该方法还提出基于区域的训练策略(RTS),在初始化建议后,将建议路径分为空间群组,通过路径分配计算路径回归损失和分类损失,以确保生成预测轨迹的多样性。
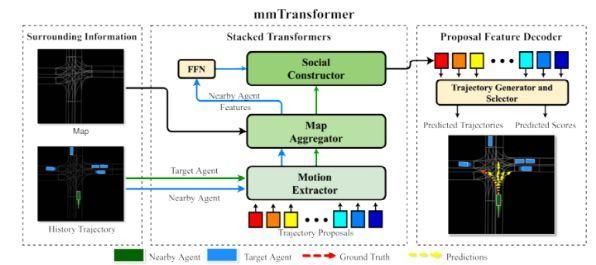
图2:mmTransformer模型框架
Yuan等针对时间和社会维度上独立特征编码信息丢失问题,提出AgentFormer[6]允许一个智能体在某个时间的状态直接影响另一个智能体未来的状态,而不是通过在一个维度上编码的中间特征,AgentFormer(图3)可以同时学习时序信息和交互关系,智能体当前时刻的关系可以通过不同时刻关系体现,解决了传统Transformer注意力中各个输入元素权重平等造成的时间和智能体信息损失,该模型采用时间编码减少时间信息损失,通过独特的Agent-aware注意力机制编码智能体和时间的关系,采用CVAE形式,以概率形式描述,确保了生成轨迹的多模态性。
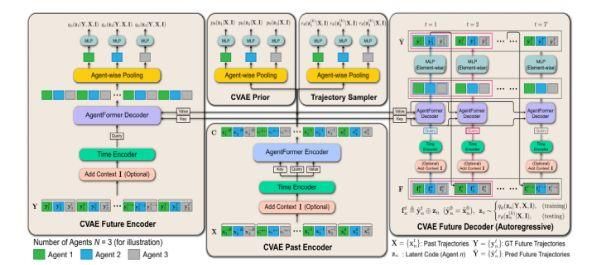
图 3:AgentFormer模型框架
Huang[10]等针对如何编码多智能体交互问题,使用TF编码器(图4)建模智能体与周围车辆的交互关系,多头注意机制可以帮助提取智能体交互的不同信息。通过矢量地图表示和基于地车道集的地图结构提取地图和目标智能体之间的关系。
Zhao等针对传统注意力机制无法捕获多智能体之间交互的问题,提出Spatial-Channel Transformer[9]在基于Transformer框架的基础上,插入了一个通道注意力(Channel-wise attention)模块(图5),即挤压激励网络(SE)[8],并将SE网络用于轨迹前途,以捕获相邻通道之间的相互作用。Zhang等针对多智能体轨迹预测问题,提出的Gatformer[11]相较于GNN,采用灵活的图结构,相比基于图神经网络的方法,降低了全连通图造成的计算复杂性。基于稀疏图,Gatformer可以预测多智能体未来的轨迹,同时考虑智能体之间相互作用。目前基于GAN和CVAE方法导致模型存在可解释性差的问题,Gatformer注意机制通过对交互权重分配可以提高性能并提高模型的可解释性,该模型对模型在多环境下验证了模型的鲁棒性。
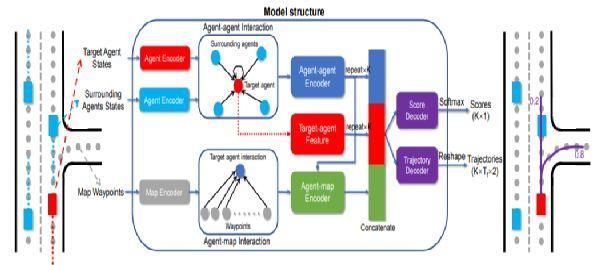
图 4:Motion Prediction Model模型框架
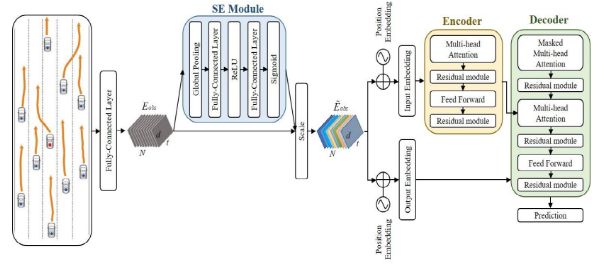
图5:Spatial-Channel Transformer框架
复杂的驾驶环境通常是静态动态混合形式作为输入信息,针对如何表示融合有关道路几何形状,车道连通性,时变交通信号灯状态,其他交通参与者状态以及交互的历史信息,并将其编码,现有方法为了对多样特征建模而设计的具有不同特定模块集的复杂TF模型,由于注意对输入序列长度是二次方,且位置前馈网络是昂贵的自网络因此导致TF难以规模化,质量和效率无法同时保证。针对此问题,Waymo提出WayFormer[7](图6) 在Transformer框架的基础上,研究了三种输入模式:前融合,后融合和分层融合的利弊,对于每种融合类型,探索通过分解注意或潜在query注意来权衡效率和质量的策略。后融合中每种特征都有与之相对应的编码器,前融合不是将注意编码器专用于每个模态,而是减少特定模态的参数到投影层,分层融合是前融合,后融合折中的模型,将场景信息分别通过注意编码器编码后聚合,将聚合特征输入到最终的注意机制交叉模型中,有效的将场景编码器的深度在模态特定编码器和跨模态编码器之间平均。本文还对如何将Transformer扩展到大型多维序列中提供了解决方案,减少了每个块的注意分量和位置前馈网络的计算成本。
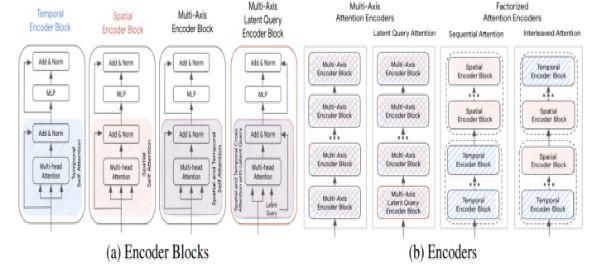
图6:Wayformer对编码器结构的改进
4.总结与展望
综上所述,现阶段在多模态轨迹预测领域的整体框架已经成型,都是由编码器+交互+解码器组成,针对多模态轨迹预测目前具有的挑战性问题,基于Transformer轨迹预测在Argoverse数据集的平均位移误差(ADE)和最终位移误差(FDE)性能指标上取得了最优水平。Transformer框架在交互部分,特别是对障碍物周围信息交互效果相比CNN与RNN方法有明显的提升,Transformer可以解决长历史轨迹信息丢失问题,同时依靠注意力机制捕获车辆之间交互信息。
然而Transformer模型虽然在自然语言处理及视觉领域均取得了非常显著的成果,但是在自动驾驶轨迹预测方向的研究还是较少。目前还无法确Transformer算法可以应用到更为复杂多变的环境中,因为在现实环境中,由于传感器限制,如果有其他交通参与者遮挡,或者出现缺失/过时/不准确的道路基础设施信息,以及感知范围有限,无法获得实验阶段的理想数据,会导致预测轨迹出现偏差。同时可解释性低也是基于Transformer模型面临的主要问题之一,现有方法中对于预测轨迹的置信度难以解释,因此导致模型解释性低。这些问题也将是未来使用Transformer做多模态轨迹预测的可继续深入的方向。其次现有方法对于多模态的研究还不充分,相信在未来的发展中,基于Transformer的多模态轨迹预测方法会更加完善,轨迹预测技术走进现实生活一定可以实现。
5.参考文献
[1]A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” CoRR, vol. abs/1706.03762, 2017.arXiv: 1706.03762. [Online]. Available: http://arxiv.org/abs/1706.03762.
[2]A. Graves, “Generating sequences with recurrent neural networks,” CoRR, vol. abs/1308.0850, 2013. arXiv: 1308 . 0850. [Online]. Available: http : / /arxiv.org/abs/1308.0850.
[3]N. Lee, W. Choi, P. Vernaza, C. B. Choy, P. H. S. Torr, and M. K. Chandraker, “DESIRE: distant future prediction in dynamic scenes with interacting agents,” CoRR, vol. abs/1704.04394, 2017. arXiv: 1704 . 04394. [Online]. Available: http://arxiv.org/abs/1704.04394.
[4]H. Zhao, J. Gao, T. Lan, C. Sun, B. Sapp, B. Varadarajan, Y. Shen, Y. Shen, Y. Chai, C. Schmid, C. Li, and D. Anguelov, “TNT: target-driven trajectory prediction,”CoRR, vol. abs/2008.08294, 2020. arXiv: 2008 . 08294. [Online]. Available:https://arxiv.org/abs/2008.08294.
[5]Y. Liu, J. Zhang, L. Fang, Q. Jiang, and B. Zhou, “Multimodal motion prediction with stacked transformers,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 7573–7582. DOI: 10.1109/CVPR46437.2021.00749.