机器学习基础知识点⑤数据增强、类别不平衡
一、F1、P、R、ROC
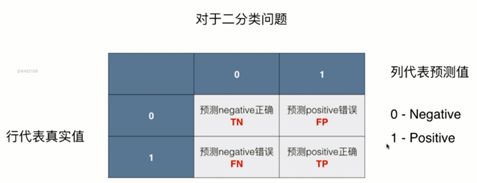
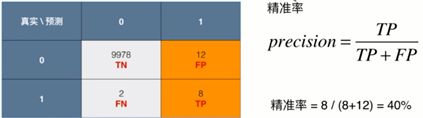
P= 分类正确的正样本数 / 分类器预测正样本的个数
P:预测20人患癌,其中有8人真实患癌

R = 分类正确的正样本数 / 真正的正样本个数
R:真实发生了,10人真实患癌,预测出8人
- 股票预测,注重精准率:预测20个股票会升(标记1),其中有8个真实升了,投钱入股时更重要
- 病人诊断,注重召回率:本来本人得病,没有预测出来,造成病情恶化,10人真实患癌,预测出8人
F1两者的调和平均值


ROC和AUC
threshold 的调整,不是随便调的,设的越高,灵敏度就越低,设的越低,假阳性就越多。希望 TPR 越大越好而 FPR 越小越好
- 纵坐标:灵敏度(真阳性)TPR: the true positive rate (TP / (TP + FN)) 就是前面说的 recall
- 横坐标:假阳性FPR:the false positive rate (FP / (FP + TN)) 就是所有本来是阴性其中有多少被错判成了阳性,可以理解成成本。
ROC (Receiver Operating Characteristic)曲线下面的面积越大,模型就越好。
这个曲线下面积就称为 AUC(Area Under the Curve),AUC取值一般在0.5-1之间,AUC越大,分类器越可能把真正的正样本排在前面,分类性能越好。
ROC曲线的特点:vs PRC
当正负样本的分布发生变化时,形状能够基本保持不变。P-R曲线形状会剧烈变化。
相对来讲ROC曲线会稳定很多,在正负样本量都足够的情况下,ROC曲线足够反映模型的判断能力。
因此,对于同一模型,PRC和ROC曲线都可以说明一定的问题,而且二者有一定的相关性,如果想评测模型效果,也可以把两条曲线都画出来综合评价。
- 对于有监督的二分类问题,在正负样本都足够的情况下,可以直接用ROC曲线、AUC评价模型效果。在确定阈值过程中,可以根据Precision、Recall或者F1来评价模型的分类效果。
- 对于多分类问题,可以对每一类分别计算Precision、Recall和F1,综合作为模型评价指标。
二、交叉熵
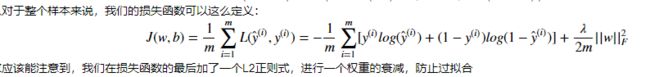
Tensorflow四种交叉熵函数计算公式:tf.nn.cross_entropy
TensorFlow交叉熵函数(cross_entropy)·理解 - 简书
tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
def calculate_loss(self, predict, target):
"""
predict是未经过sigmoid的值
"""
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=target, logits=predict))
return losscross_entropy = -tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(labels=label, logits=y))最小化交叉熵损失函数的过程也是最大化正确类别的预测概率的过程
softmax_cross_entropy_with_logits
-
计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
-
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用。
def softmax(x):
return (np.exp(x).T / np.exp(x).sum(axis=-1))交叉熵和softmax区别
在实际操作中,会在神经网络的最后一层再加一个softmax层,很多论文里都会将softmax loss写成以下形式: n为batch size,C为类的数目,xi为第i个样本的特征,yi为xi对应的类标签,Wj和bj为类j的权重及偏置。
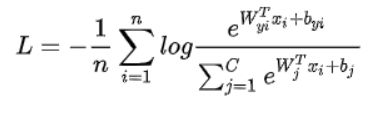
softmax loss简单来说,就是将神经网络的logit用softmax包裹起来,再丢到交叉熵里面去。看到很多人说什么softmax loss是不严谨的说法。实际上,我看了很多顶会论文,大佬们都是用softmax loss作为softmax function+cross entropy loss的简称。
总结一下,softmax是激活函数,交叉熵是损失函数,softmax loss是使用了softmax funciton的交叉熵损失。
三、BN和LN
LayerNorm和BatchNorm的区别
batchNormalization与layerNormalization的区别 - 知乎
作用:
- 经过归一化再输入激活函数,得到的值大部分会落入非线性函数的线性区,导数远离导数饱和区,避免了梯度消失,这样来加速训练收敛过程。
- BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。
LayerNorm和BatchNorm的区别:主要是做规范化的维度不同
batchNormalization与layerNormalization的区别 - 知乎
- Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。
- Batch Normalization 是对这批样本的同一维度特征(一个中间层的单个神经元)做归一化, Layer Normalization 是对这单个样本的所有维度特征(一个中间层的所有神经元)做归一化。
- BN(每一行进行归一化)、LN(每一列进行归一化)可以看作横向和纵向的区别。
- BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。LayerNorm则是通过对Hidden size这个维度归一。
- BN一般而言选择,LN当小批量样本数量比较小时选择。
- BatchNorm针对一个batch里面的数据进行规范化,针对单个神经元进行,比如batch里面有64个样本,那么规范化输入的这64个样本各自经过这个神经元后的值(64维)
- LayerNorm则是针对单个样本,不依赖于其他数据,常被用于小mini-batch场景、动态网络场景和 RNN,特别是NLP领域,
- 就bert来说就是对每层输出的隐层向量(768维)做规范化,图像领域用BN比较多的原因是因为每一个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被一起规范化。
Normalization 通用公式



①Batch Normalization(纵向规范化)M是mini-batch 的大小。比较适用的场景是:每个 mini-batch 比较大,数据分布比较接近。在进行训练之前,要做好充分的 shuffle. 否则效果会差很多。
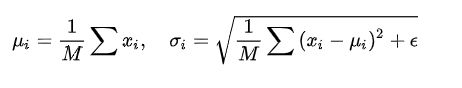
②Layer Normalization(横向规范化) LN 针对单个训练样本进行,不依赖于其他数据,因此可以避免 BN 中受 mini-batch 数据分布影响的问题,可以用于 小mini-batch场景、动态网络场景和 RNN,特别是NLP领域。此外,LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。
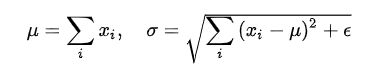
第一步已得到标准分布,第二步怎么又给变走了? (过激活函数前规范化,之后还原)
答案是:为了保证模型的表达能力不因为规范化而下降。我们可以看到
- 第一步的变换将输入数据限制到了一个全局统一的确定范围(均值为 0、方差为 1)。下层神经元可能很努力地在学习,但不论其如何变化,其输出的结果在交给上层神经元进行处理之前,将被粗暴地重新调整到这一固定范围。
- 为了尊重底层神经网络的学习结果,我们将规范化后的数据进行再平移和再缩放,使得每个神经元对应的输入范围是针对该神经元量身定制的一个确定范围(均值为 b,方差为 g^2)
https://www.zhihu.com/search?type=content&q=batchnorm和layernorm
实战代码
① 帖一个LayerNorm的实现
class BertLayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-5):
super(BertLayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias- 帖一个LayerNorm的实现,可以看到module中有weight和bias参数,以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域, 只包含线性变换,破坏了之前学习到的特征分布。
- 为了恢复原始数据分布,具体实现中引入了变换重构以及可学习参数w和b ,也就是上面的weight和bias,简而言之,规范化后的隐层表示将输入数据限制到了一个全局统一的确定范围,为了保证模型的表达能力不因为规范化而下降,引入了是b是再平移参数,w是再缩放参数。(过激活函数前规范化,之后还原)
② 帖一个BatchNorm的实现
self.batch_norm_is_training = tf.placeholder(tf.bool, name='batch_norm_is_training')
# conv1
conv1 = tf.nn.conv2d(self.input_x_expanded, W1, strides=[1, 5, 5, 1], padding="SAME", name="conv1")
conv1 = tf.contrib.layers.batch_norm(conv1, is_training=self.batch_norm_is_training, scope='bn1') # BN归一化
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, b1), name="relu1")- 训练中:使用当前小批量的均值和标准方差,batch_norm_is_training: True
- 测试中:使用运行平均值,batch_norm_is_training: False
def batch_norm(self, x, n_out, phase_train, batch_norm_decay, scope='bn'):
"""
Batch normalization on convolutional maps.
"""
with tf.variable_scope(scope):
beta = tf.Variable(tf.constant(0.0, shape=[n_out]),
name='beta', trainable=True)
gamma = tf.Variable(tf.constant(1.0, shape=[n_out]),
name='gamma', trainable=True)
# 计算x的均值和方差
batch_mean, batch_var = tf.nn.moments(x, [0,1,2], name='moments')
# 采用滑动平均的方法更新参数。函数初始化需要衰减速率(decay),用于控制模型的更新速度
ema = tf.train.ExponentialMovingAverage(decay=batch_norm_decay, name='ema')
def mean_var_with_update():
ema_apply_op = ema.apply([batch_mean, batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean), tf.identity(batch_var)
mean, var = tf.cond(phase_train,
mean_var_with_update,
lambda: (ema.average(batch_mean), ema.average(batch_var)))
normed = tf.nn.batch_normalization(x, mean, var,
beta, gamma, 1e-3, name = 'normed') # variance_epsilon是为了避免分母为0,添加的一个极小值1e-3
return normedBatchNorm的背景
内部协变量偏移,给神经网络训练带来的问题:
- 网络每一层需不断适应输入数据的分布变化,影响学习效率
- 网络前几层参数的更新,很可能使得后几层的输入数据变得过大或过小,从而掉进激活函数的饱和区,导致学习过程的过早停止
- 旧的解决方法:relu非饱和型激活函数、参数初始化、保守的学习率
新的解决方法 BN(百面深度学习)
四、NLP数据增强技术
集合啦,NLP数据增强技术!超全资源汇总 - 知乎
CV领域的标配,比如对图像的旋转、镜像、高斯白噪声等。
(1)文本替代
文本替代主要是针对在不改变句子含义的情况下,替换文本中的单词,比如,同义词替换、词嵌入替换等等。
同义词替换:在文本中随机抽取一个单词,然后再同义词库里将其替换为同义词。比如,使用WordNet数据库,将「awesome」替换为「amazing」。
词嵌入替换:采取已经预训练好的单词嵌入,如Word2Vec、GloVe、FastText、Sent2Vec等,并将嵌入空间中最近的邻接词作为句子中某些单词的替换。awesome替换成临近的amazing、prefect、fantastic
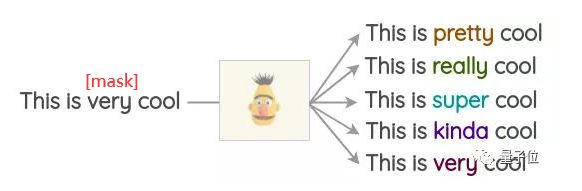
掩码语言模型(MLM)
类似于BERT、ROBERTA、ALBERT,Transformer模型已经在大量的文本训练过,使用掩码语言模型的前置任务。
在这个任务中,模型必须依照上下文来预测掩码的单词。此外,还可以利用这一点,对文本进行扩容。
基于TF-IDF的单词替换:基本思路在于TF-IDF得分低的单词是没有信息量的的词,因此可以替换,而不影响句子的原本含义。(This -> A)
(2)回译
就是先将句子翻译成另一种语言,比如,英语翻译成法语。然后再翻译回原来的语言,也就是将法语翻译回英语。检查两个句子之间的不同之处,由此将新的句子作为增强文本。
(3)随机噪声注入
在文本中注入噪声,来训练模型对扰动的鲁棒性。拼写错误、句子与句子交换顺序等
(4)生成方法
此工作尝试在保留标签类别的同时生成其他训练数据。 将类别标签附加到训练数据中的每个文本。 在修改后的训练数据上微调一个大型的预训练语言模型(BERT / GPT2 / BART)。对于GPT2,微调任务是生成,而对于BERT,目标将是屏蔽token预测。
使用微调的语言模型,可以通过使用类标签和少量的初始单词作为模型提示来生成新样本。本文使用每个训练文本的3个初始单词,并为训练数据中的每个点生成一个综合示例。
自然语言处理中数据增强(Data Augmentation)技术最全盘点
五、数据不平衡(Focal loss)
解决思想 如何解决NLP分类任务的11个关键问题:类别不平衡&低耗时计算&小样本&鲁棒性&测试检验&长文本分类 - 知乎
不平衡问题不仅仅是分类标签下样本数量的不平衡,其本质上更是难易样本的不平衡:即使样本数量是平衡的,有的hard example还是很难学习。
(1)重采样(re-sampling)
- 欠采样&过采样&SMOTE
- 欠采样:抛弃大量case,可能导致偏差加大;
- 过采样:可能会导致过拟合;
- SMOTE:一种近邻插值,降低过拟合风险,但不能直接应用于NLP任务的离散空间插值。
- 数据增强:文本增强技术更适合于替代上述过采样和SMOTE。
(2)重加权(re-weighting)
重加权就是改变分类loss。相较于重采样,重加权loss更加灵活和方便。其常用方法有:
- loss类别加权:通常根据类别数量进行加权,加权系数与类别数量成反比。

- Focal Loss:上述loss类别加权主要关注正负样本数量的不平衡,并没有关注难易不平衡。Focal Loss主要关注难易样本的不平衡问题,可根据对高置信度(p)样本进行降权:
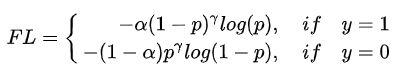
TensorFlow/Keras的一个解决数据不平衡问题的机制
分类数据集极度不平衡(99.82%负样本 vs 0.18%正样本)。
统计每种类别包含的样本数量,并基于此计算类别权重。
# 计算每种类别数据的数量
counts = np.bincount(train_targets[:, 0])
# 基于数量计算类别权重
weight_for_0 = 1. / counts[0]
weight_for_1 = 1. / counts[1]
class_weight = {0: weight_for_0, 1: weight_for_1}在训练时,加上一行代码设置类别权重即可。
model.fit(train_features, train_targets,
batch_size=2048,
epochs=50,
verbose=2,
callbacks=callbacks,
validation_data=(val_features, val_targets),
# 设置类别权重
class_weight=class_weight)一行TensorFlow/Keras代码解决真实场景中数据不平衡(imbalanced)问题
(3)Focal Loss
(精:代码+CE缺点) Focal Loss --- 从直觉到实现 - 知乎
引入两个额外的变量来区分对待每个样本,以复习考试知识点为例子

- CE不会划重点,对所有知识点 “一视同仁”
- FL不再平均用力
【分科复习/类别权重】:每个【科目】的难度是不同的; 你要花 30%的精力在简单科目,70%的精力在困难科目。
- 针对每个类别赋予不同的权重
【刷题战术/难度权重】:每道【题目】的难度是不同的; 你要根据以往刷类似题时候的正确率来合理分配精力。
- CE中 p 反映了模型对这个样本的识别能力(这个知识点掌握得有多好)对于p越大的样本,越要打压它对loss的贡献。
- 超参数γ越大 打压越重
拓:苏神(含FL多分类形式) 从loss的硬截断、软化到focal loss - 科学空间|Scientific Spaces
六、L1和L2
降低过拟合程度:
- 正则化是结构风险最小化的一种策略实现。
- 给loss function加上正则化项,能使得新得到的优化目标函数h = 原函数f+正则化项normal,需要在f和normal中做一个权衡(trade-off),如果还像原来只优化f的情况下,那可能得到一组解比较复杂,使得正则项normal比较大,那么h就不是最优的,
- 因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论,同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。
L1正则化和L2正则化:
L1(模型参数服从零均值拉普拉斯分布)和L2(模型参数服从零均值正态分布)
- L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。
- L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
L1正则化与L2正则化 - 知乎
七、防止过拟合

机器学习中用来防止过拟合的方法有哪些? - 知乎
八、激活函数(优缺点)
温故知新——激活函数及其各自的优缺点 - 知乎
九、深度学习早停法
所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。
在 FastText 中使用 early_stopping :
monitor: 需要监视的量,val_acc() (模型准确率model accuracy)
patience: 当early stop被激活(如发现 loss 相比上一个 epoch 训练没有下降),则经过 patience 个 epoch 后停止训练
verbose: 信息展示模式
mode: ‘auto’,‘min’,'max’之一,在min模式训练,如果检测值停止下降则终止训练。在max模式下,当检测值不再上升的时候则停止训练。
[nlp] 深度学习技巧(防止过拟合)——Early Stopping 早停法_跳墙网