Mapreduce实例(三):数据去重
MR 实现 数据去重
- 实现思路
- 编写代码
-
- Mapper代码
- Reducer代码
- 完整代码
大家好,我是风云,欢迎大家关注我的博客 或者 微信公众号【笑看风云路】,在未来的日子里我们一起来学习大数据相关的技术,一起努力奋斗,遇见更好的自己!
实现思路
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。在MapReduce流程中,map的输出
MaprReduce去重流程如下图所示:
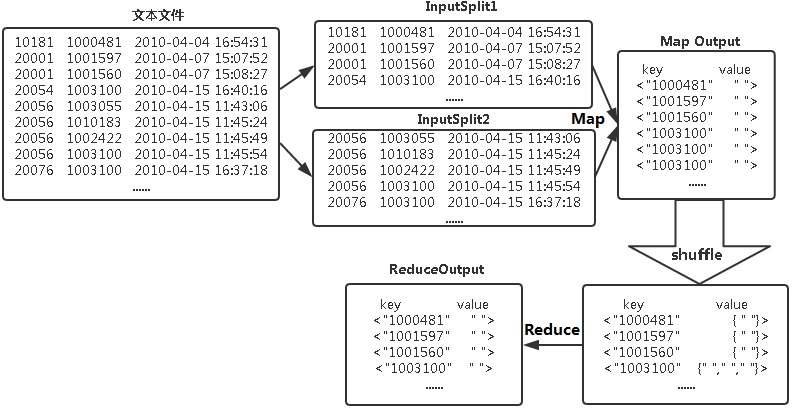
编写代码
Mapper代码
public static class Map extends Mapper<Object , Text , Text , NullWritable>
//map将输入中的value复制到输出数据的key上,并直接输出
{
private static Text newKey=new Text(); //从输入中得到的每行的数据的类型
public void map(Object key,Text value,Context context) throws IOException, InterruptedException
//实现map函数
{ //获取并输出每一次的处理过程
String line=value.toString();
System.out.println(line);
String arr[]=line.split("\t");
newKey.set(arr[1]);
context.write(newKey, NullWritable.get());
System.out.println(newKey);
}
}
Mapper阶段采用Hadoop的默认的作业输入方式,把输入的value用split()方法截取,截取出的商品id字段设置为key,设置value为空,然后直接输出
Reducer代码
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable>{
public void reduce(Text key,Iterable<NullWritable> values,Context context) throws IOException, InterruptedException
//实现reduce函数
{
context.write(key,NullWritable.get()); //获取并输出每一次的处理过程
}
}
map输出的
完整代码
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Filter{
public static class Map extends Mapper<Object , Text , Text , NullWritable>{
private static Text newKey=new Text();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
System.out.println(line);
String arr[]=line.split("\t");
newKey.set(arr[1]);
context.write(newKey, NullWritable.get());
System.out.println(newKey);
}
}
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable>{
public void reduce(Text key,Iterable<NullWritable> values,Context context) throws IOException, InterruptedException{
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
System.out.println("start");
Job job =new Job(conf,"filter");
job.setJarByClass(Filter.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in=new Path("hdfs://localhost:9000/mymapreduce2/in/buyer_favorite1");
Path out=new Path("hdfs://localhost:9000/mymapreduce2/out");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-------------- end ----------------
微信公众号:扫描下方二维码或 搜索 笑看风云路 关注
