focal loss softmax cross entropy sigmoid mse loss及其求导
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) , p t = p i f y = 1 , e l s e ( 1 − p ) FL(p_t) = - \alpha_t (1-p_t)^{\gamma} \log{(p_t)}, p_t=p \ if \ y=1,else \ (1-p) FL(pt)=−αt(1−pt)γlog(pt),pt=p if y=1,else (1−p)
论文中 α = 0.25 \alpha=0.25 α=0.25, γ = 2 \gamma =2 γ=2时表现最好。
为什么一阶段比二阶段表现不好
1,数量上,正负样本不均衡
2,难易上,梯度被易样本主导
正负样本的定义
备选框中与ground truth的iou大于等于某个人为设定的阈值的为正样本,否则为负样本
原始的cross entropy
C E ( p t ) = − log p t , p t = p i f y = 1 , e l s e ( 1 − p ) CE(p_t)=-\log{p_t}, p_t=p \ if \ y=1,else \ (1-p) CE(pt)=−logpt,pt=p if y=1,else (1−p)
解决办法
1, − α log p t -\alpha \log {p_t} −αlogpt解决正负样本不均衡问题
原理是对正负样本取不同的权值
2, − ( 1 − p t ) γ log p t -(1-p_t)^{\gamma} \log{p_t} −(1−pt)γlogpt解决梯度被易样本主导问题
(1)当 p t p_t pt很小,最小到0, ( 1 − p t ) (1-p_t) (1−pt)趋近于1,跟原始的cross entropy很接近,正常学习,对loss的贡献正常,是分类分得不对时的情况(misclassified),到训练后期一般是困难样本导致的。
(2)当 p t p_t pt很大,最大到1, ( 1 − p t ) (1-p_t) (1−pt)趋近于0,权值很小,对loss的贡献很少,是易样本导致的。
(3) γ \gamma γ作为幂进一步减少易样本对loss的贡献,因为 ( 1 − p t ) (1-p_t) (1−pt)趋近于0,当它的幂大于0时, ( 1 − p t ) (1-p_t) (1−pt)更加趋近于0。
(4) − ( 1 − p t ) γ -(1-p_t)^{\gamma} −(1−pt)γ作为一个整体,扩大了小的loss的范围,比如当 p t = 0.9 p_t=0.9 pt=0.9, γ = 2 \gamma=2 γ=2, ( 1 − 0.9 ) 2 = 0.01 (1-0.9)^2=0.01 (1−0.9)2=0.01,比单纯的corss entropy的loss小了100倍。
softmax及其求导,softmax和cross entropy结合的求导

sigmoid求导
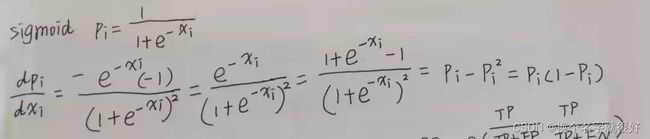
mse 求导
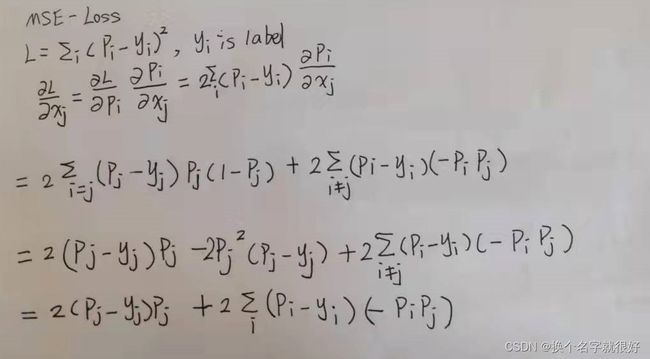
p t p_t pt的实现
用torch.where(target==1, input_, 1-input_),其中target和input_的shape一样。
import torch
input_ = [[0.2, 0.1, 0.7],
[0.1, 0.3, 0.6]]
target = [[0, 0, 1],
[0, 0, 1]]
input_ = torch.tensor(input_, dtype=torch.float32)
target = torch.tensor(target, dtype=torch.float32)
pt = torch.where(target==1, input_, 1-input_)
print(pt)
output:
tensor([[0.8000, 0.9000, 0.7000],
[0.9000, 0.7000, 0.6000]])
focal loss 实现
以下代码仅适用于图像分割的多分类场景。
图像分割是对每个像素进行分类,一张图,有h乘w个像素,一个mini-batch有n张图,
需要对n乘h乘w个像素进行分类。
多分类的交叉熵和二分类的交叉熵公式上是不同的,focal loss 只是在交叉熵的基础上增加了
类别平衡参数和专注困难样本学习这两个因素,所以二分类focal loss 和多分类的focal loss在实现上
会不同。
多分类时,alpha_t取的是各个类别频率的倒数。二分类时,正样本是alpha,负样本是1-alpha。
数据集不同,类别数和各个类别的频率也不同,需要按实际情况修改类的init函数传入的cnts值。
我的做法是,随机从训练集抽取1000个样本,统计这些样本中各个类的数目,把这些数目按顺序
填入cnts列表中。
class MyFocalLoss(nn.Module):
def __init__(self, nbclasses, cnts=[381155699, 4830287, 861159, 440608, 37987, 4061447, 1235420, 593393], gamma=2):
'''
cnts: [num_class0, num_class1, ..., num_classn]
'''
super(MyFocalLoss, self).__init__()
self.nbclasses = nbclasses
cnts = np.array(cnts, dtype=np.float64)
cnts[:] = 1./(cnts[:]/cnts.sum()) # Reciprocal of frequency
alpha_t = torch.from_numpy(cnts).cuda()
self.alpha_t = alpha_t # shape: nbclass
self.gamma = gamma
def one_hot(self, targets, nbclasses):
"""Convert an iterable of indices to one-hot encoded labels."""
targets = targets.reshape(-1)
return torch.eye(nbclasses)[targets]
def forward(self, inputs, targets): # target long dtype
# print("inputs.shape:{}, targets.shape:{}".format(inputs.shape, targets.shape)) # N 张图
# inputs.shape:torch.Size([8, 8, 384, 1024]), targets.shape:torch.Size([8, 384, 1024]) inputs: N,nbclasses,h,w targets: N,h,w
loss = 0.0
if inputs.dim() > 2:
one_hot_targets = self.one_hot(targets, self.nbclasses).cuda() # one_hot_targets: N*h*w, nbclasses
inputs = inputs.permute(0, 2, 3, 1).contiguous().view(-1, self.nbclasses).sigmoid().cuda() # inputs n, c, h, w ==> n*h*w, c
pt = torch.where(one_hot_targets==1, inputs, 1-inputs).cuda()
loss = -self.alpha_t*(1-pt)**self.gamma*torch.log(pt)*one_hot_targets
return loss.sum()/pt.size(0) # scaler
总结
1,focal loss解决了正负样本不均衡以及梯度被易样本主导的问题。
2,softmax求导当i等于j时是 p i ( 1 − p i ) p_i(1-p_i) pi(1−pi),不等时是 − p i p j -p_ip_j −pipj。
3,cross entropy和softmax结合求导结果为 p j − y j p_j-y_j pj−yj,过程是链式求导,先求loss对 p j p_j pj的导数,再将这个导数和2中求出的softmax的分情况讨论的结果结合即可。
4,sigmoid导数为 p i ( 1 − p i ) p_i(1-p_i) pi(1−pi),跟softmax的i等于j时的结果一样。
5,mse导数为 2 ( p j − y j ) p j + 2 ∑ i ( p i − y i ) ( − p i p j ) 2(p_j-y_j)p_j+2\sum_i(p_i-y_i)(-p_ip_j) 2(pj−yj)pj+2∑i(pi−yi)(−pipj),过程和3类似。