mindspore两日集训营202209-自定义算子 数据处理
作业一:基于pyfunc模式定义sin算子
写一个基于numpy的计算正弦函数的python原生函数。
定义两个函数,一个是张量形状的推导函数(infer_shape),另一个是张量数据类型的推导函数(infer_dtype)。
使用作业模板提供的测试代码测试基于上面函数的pyfunc类型自定义算子,并与MindSpore自带的Sin算子作为比较。
作业二:利用hybrid类型的自定义算子实现三维张量的加法函数
要修改的地方非常简单
def sin_by_numpy(x):
# 在这里书写你的计算逻辑
# 提示:使用np.sin函数
return np.sin(x)
def infer_shape(x):
# 在这里书写你的计算逻辑
# 提示:
# 1. 这里的输入x是算子输入张量的形状
# 2. sin函数是逐元素计算,输入的形状和输出的一样
return x.shape
# 然后我们要定义两个函数,一个是张量形状的推导函数(infer_shape),另一个是张量数据类型的推导函数(infer_dtype)。这里我们要注意:
# - 张量形状的推导函数是输入张量的形状;
# - 张量数据类型的推导函数是输入张量的数据类型。
def infer_dtype(x):
# 在这里书写你的计算逻辑
# 提示:
# 1. 这里的输入x是算子输入张量的数据类型
# 2. sin函数输入的数据类型和输出的一样
return x.dtype
@ms_kernel
def tensor_add_3d(x, y):
result = output_tensor(x.shape, x.dtype)
# 在这里书写你的计算逻辑
# 提示:
# 1. 你需要一个三层循环
# 2. 第i层循环的上界可以用x.shape[i]获得
# 3. 你需要基于每个元素表达计算,例如加法为 x[i, j, k] + y[i, j, k]
for i in range(x.shape[0]):
for j in range(x.shape[1]):
for k in range(x.shape[2]):
result[i,j,k] = x[i, j, k] + y[i, j, k]
return result

list没有shape
稍微修改一下,最后的结果
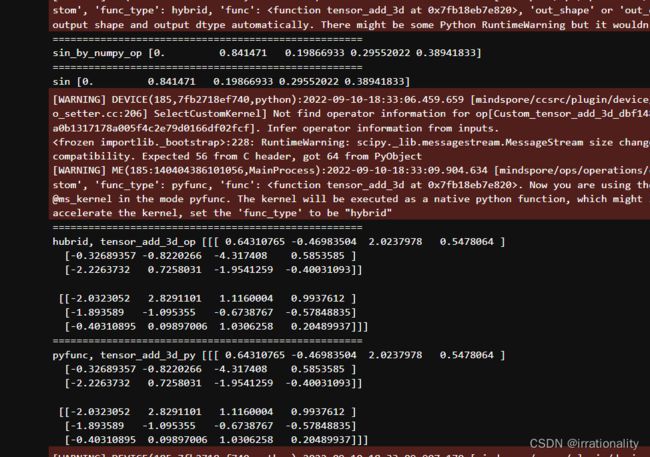
结果出来了,非常顺利,验证的结果和自己创建的结果完全相同。
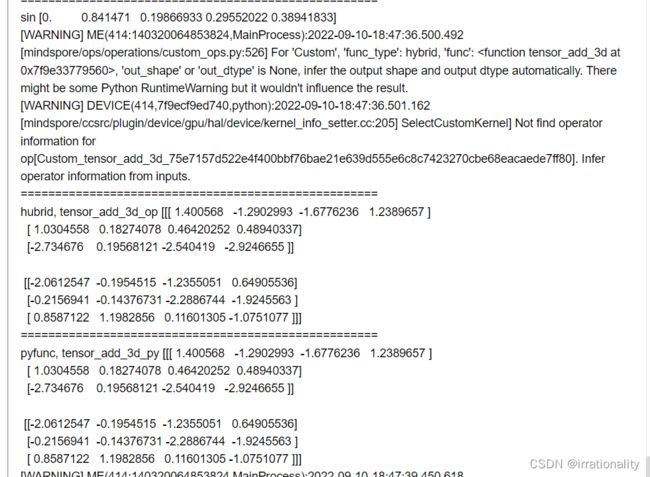
最终的代码
import numpy as np
import mindspore as ms
from mindspore import ops
from mindspore.ops import ms_kernel
from mindspore.nn import Cell
########################################
# 这里选用你使用的平台类型:CPU或者GPU #
########################################
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU")
## 作业一:基于pyfunc模式定义sin算子
# 首先,我们写一个基于numpy的计算正弦函数的python原生函数。
def sin_by_numpy(x):
# 在这里书写你的计算逻辑
# 提示:使用np.sin函数
return np.sin(x)
def infer_shape(x):
# 在这里书写你的计算逻辑
# 提示:
# 1. 这里的输入x是算子输入张量的形状
# 2. sin函数是逐元素计算,输入的形状和输出的一样
return x
# 然后我们要定义两个函数,一个是张量形状的推导函数(infer_shape),另一个是张量数据类型的推导函数(infer_dtype)。这里我们要注意:
# - 张量形状的推导函数是输入张量的形状;
# - 张量数据类型的推导函数是输入张量的数据类型。
def infer_dtype(x):
# 在这里书写你的计算逻辑
# 提示:
# 1. 这里的输入x是算子输入张量的数据类型
# 2. sin函数输入的数据类型和输出的一样
return x
# 下面我们用上面的函数自定义一个算子,其输入包括
# - func:自定义算子的函数表达,这里我们用`sin_by_numpy`函数;
# - out_shape: 输出形状的推导函数,这里我们用`infer_shape`函数;
# - out_dtype: 输出数据类型的推导函数,这里我们用`infer_dtype`函数;
# - func_type: 自定义算子类型,这里我们用`"pyfunc"`。
sin_by_numpy_op = ops.Custom(func = sin_by_numpy, # 这里填入自定义算子的函数表达
out_shape = infer_shape, # 这里填入输出形状的推导函数
out_dtype = infer_dtype, # 这里填入输出数据类型的推导函数
func_type = "pyfunc" # 这里填入自定义算子类型
)
# 然后我们调用算子计算结果,直接运行下面的代码块获取结果,验证上面定义的正确性。
input_tensor = ms.Tensor([0,1, 0.2, 0.3, 0.4], dtype=ms.float32)
result_cus = sin_by_numpy_op(input_tensor)
print("====================================================")
print("sin_by_numpy_op", result_cus)
# 作为比较,我们用MindSpore自带的Sin算子作为比较。运行下面的代码块,并且比较输出结果和上面的结果,验证上面计算的正确性。
sin_ms = ops.Sin()
result = sin_ms(input_tensor)
print("====================================================")
print("sin", result)
## 作业二:利用hybrid类型的自定义算子实现三维张量的加法函数
# 首先,我们写一个基于MindSpore Hybrid DSL书写一个计算三维张量相加的函数。
# 注意:
# - 对于输出张量使用 `output_tensor`,用法为:`output_tensor(shape, dtype)`;
# - 所有的计算需要基于标量计算,如果是Tensor对象那么写清楚所有index;
# - 基本循环的写法和Python一样,循环维度的表达可以使用 `range`。
@ms_kernel
def tensor_add_3d(x, y):
result = output_tensor(x.shape, x.dtype)
# 在这里书写你的计算逻辑
# 提示:
# 1. 你需要一个三层循环
# 2. 第i层循环的上界可以用x.shape[i]获得
# 3. 你需要基于每个元素表达计算,例如加法为 x[i, j, k] + y[i, j, k]
for i in range(x.shape[0]):
for j in range(x.shape[1]):
for k in range(x.shape[2]):
result[i,j,k] = x[i, j, k] + y[i, j, k]
return result
# 下面我们用上面的函数自定义一个算子。
# 注意到基于`ms_kernel`的`hybrid`函数时,我们可以使用自动的形状和数据类型推导。
# 因此我们只用给一个`func`输入(`func_type`的默认值为`"hybrid"`)。
tensor_add_3d_op = ops.Custom(func = tensor_add_3d)
# 然后我们调用算子计算结果,直接运行下面的代码块获取结果,验证上面定义的正确性。
input_tensor_x = ms.Tensor(np.random.normal(0, 1, [2, 3, 4]).astype(np.float32))
input_tensor_y = ms.Tensor(np.random.normal(0, 1, [2, 3, 4]).astype(np.float32))
result_cus = tensor_add_3d_op(input_tensor_x, input_tensor_y)
print("====================================================")
print("hubrid, tensor_add_3d_op", result_cus)
# 同时我们可以使用`pyfunc`模式验证上面定义的正确性。
# 这里我们不需要重新定义算子计算函数`tensor_add_3d`,直接将`func_type`改为`"pyfunc"`即可。
# 注意`pyfunc`模式时我们需要手写类型推导函数。
def infer_shape_py(x, y):
return x
def infer_dtype_py(x, y):
return x
tensor_add_3d_py_func = ops.Custom(func = tensor_add_3d,
out_shape = infer_shape_py,
out_dtype = infer_dtype_py,
func_type = "pyfunc")
result_pyfunc = tensor_add_3d_py_func(input_tensor_x, input_tensor_y)
print("====================================================")
print("pyfunc, tensor_add_3d_py", result_pyfunc)
MindSpore 数据增强API统一
作业1
题目:使用MindSpore定义Cifar10数据预处理流程,并输入真实Cifar10数据集完成预处理,获得预处理的结果
说明:参考#I5O5X5:MindSpore 数据增强API统一小作业 第一部分

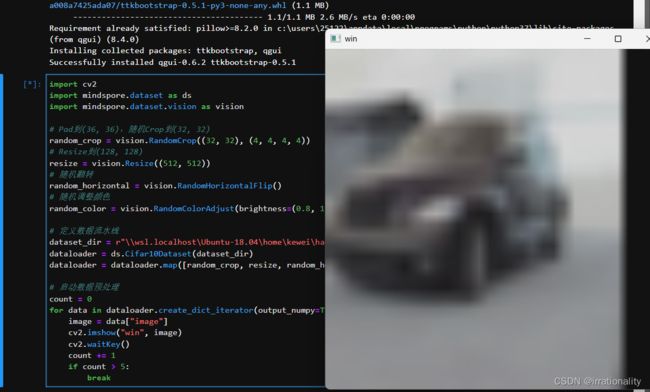
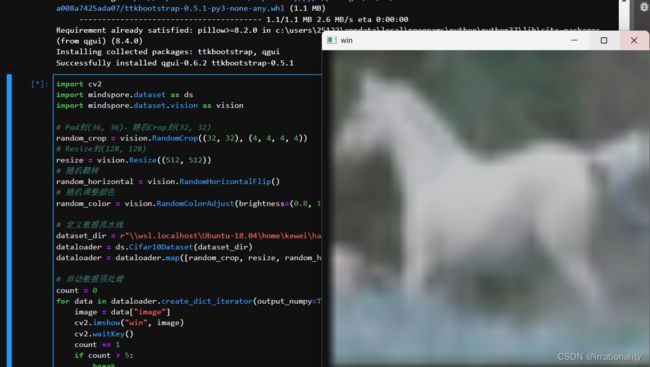
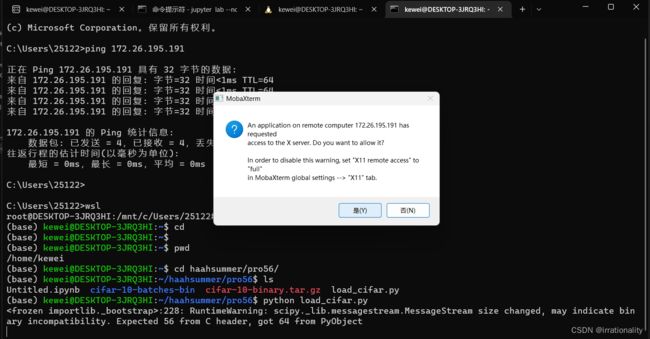
如果用wsl,会遇到如下的错误
qt.qpa.xcb: could not connect to display 172.26.192.1:0
qt.qpa.plugin: Could not load the Qt platform plugin “xcb” in “/home/kewei/.local/lib/python3.9/site-packages/cv2/qt/plugins” even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Available platform plugins are: xcb, eglfs, minimal, minimalegl, offscreen, vnc, webgl.
Aborted
解决办法
这和IDE不能直接回传图形界面相关,比如一份代码中添加cv.imshow()后报上述错误
如果有cv2show的,就在命令行运行。同时打开mobaxterm就可以了。

然后自行参考dataset API列表 做更多样的数据增强操作,并将预处理结果保存到本地。
作业2
题目:实现更丰富的数据预处理策略,穿插MindSpore预定义的数据增强API、以及自定义的python function操作
说明:参考#I5O5X5:MindSpore 数据增强API统一小作业 第二部分
这个很简单,直接套进去就可以了
比如

修改后如图
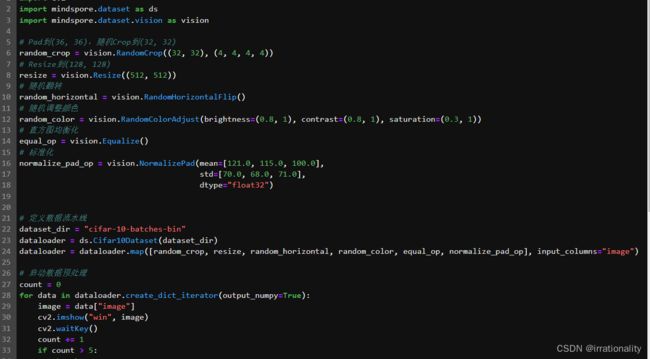
只要在上面定义增强算子,然后map中调用即可。
效果如下

那我们自定义一个pyfunc,叫做阈值化处理吧
阈值化的思路在图像处理也经常用到,思路是
x = { 0 x < a 255 x ≥ a x = \begin{cases} 0 & x < a \\ 255 \ & x \geq a \end{cases} x={0255 x<ax≥a
找到fast-rcnn代码
加入如下内容
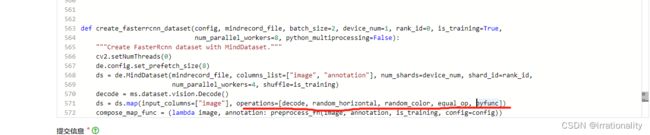
包括了3个库函数
# Copyright 2020-2022 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
"""FasterRcnn dataset"""
from __future__ import division
import os
import numpy as np
from numpy import random
import cv2
import mindspore as ms
import mindspore.dataset as de
from mindspore.mindrecord import FileWriter
def bbox_overlaps(bboxes1, bboxes2, mode='iou'):
"""Calculate the ious between each bbox of bboxes1 and bboxes2.
Args:
bboxes1(ndarray): shape (n, 4)
bboxes2(ndarray): shape (k, 4)
mode(str): iou (intersection over union) or iof (intersection
over foreground)
Returns:
ious(ndarray): shape (n, k)
"""
assert mode in ['iou', 'iof']
bboxes1 = bboxes1.astype(np.float32)
bboxes2 = bboxes2.astype(np.float32)
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
ious = np.zeros((rows, cols), dtype=np.float32)
if rows * cols == 0:
return ious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
ious = np.zeros((cols, rows), dtype=np.float32)
exchange = True
area1 = (bboxes1[:, 2] - bboxes1[:, 0] + 1) * (bboxes1[:, 3] - bboxes1[:, 1] + 1)
area2 = (bboxes2[:, 2] - bboxes2[:, 0] + 1) * (bboxes2[:, 3] - bboxes2[:, 1] + 1)
for i in range(bboxes1.shape[0]):
x_start = np.maximum(bboxes1[i, 0], bboxes2[:, 0])
y_start = np.maximum(bboxes1[i, 1], bboxes2[:, 1])
x_end = np.minimum(bboxes1[i, 2], bboxes2[:, 2])
y_end = np.minimum(bboxes1[i, 3], bboxes2[:, 3])
overlap = np.maximum(x_end - x_start + 1, 0) * np.maximum(
y_end - y_start + 1, 0)
if mode == 'iou':
union = area1[i] + area2 - overlap
else:
union = area1[i] if not exchange else area2
ious[i, :] = overlap / union
if exchange:
ious = ious.T
return ious
class PhotoMetricDistortion:
"""Photo Metric Distortion"""
def __init__(self,
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18):
self.brightness_delta = brightness_delta
self.contrast_lower, self.contrast_upper = contrast_range
self.saturation_lower, self.saturation_upper = saturation_range
self.hue_delta = hue_delta
def __call__(self, img, boxes, labels):
# random brightness
img = img.astype('float32')
if random.randint(2):
delta = random.uniform(-self.brightness_delta,
self.brightness_delta)
img += delta
# mode == 0 --> do random contrast first
# mode == 1 --> do random contrast last
mode = random.randint(2)
if mode == 1:
if random.randint(2):
alpha = random.uniform(self.contrast_lower,
self.contrast_upper)
img *= alpha
# convert color from BGR to HSV
img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# random saturation
if random.randint(2):
img[..., 1] *= random.uniform(self.saturation_lower,
self.saturation_upper)
# random hue
if random.randint(2):
img[..., 0] += random.uniform(-self.hue_delta, self.hue_delta)
img[..., 0][img[..., 0] > 360] -= 360
img[..., 0][img[..., 0] < 0] += 360
# convert color from HSV to BGR
img = cv2.cvtColor(img, cv2.COLOR_HSV2BGR)
# random contrast
if mode == 0:
if random.randint(2):
alpha = random.uniform(self.contrast_lower,
self.contrast_upper)
img *= alpha
# randomly swap channels
if random.randint(2):
img = img[..., random.permutation(3)]
return img, boxes, labels
class Expand:
"""expand image"""
def __init__(self, mean=(0, 0, 0), to_rgb=True, ratio_range=(1, 4)):
if to_rgb:
self.mean = mean[::-1]
else:
self.mean = mean
self.min_ratio, self.max_ratio = ratio_range
def __call__(self, img, boxes, labels):
if random.randint(2):
return img, boxes, labels
h, w, c = img.shape
ratio = random.uniform(self.min_ratio, self.max_ratio)
expand_img = np.full((int(h * ratio), int(w * ratio), c),
self.mean).astype(img.dtype)
left = int(random.uniform(0, w * ratio - w))
top = int(random.uniform(0, h * ratio - h))
expand_img[top:top + h, left:left + w] = img
img = expand_img
boxes += np.tile((left, top), 2)
return img, boxes, labels
def rescale_with_tuple(img, scale):
h, w = img.shape[:2]
scale_factor = min(max(scale) / max(h, w), min(scale) / min(h, w))
new_size = int(w * float(scale_factor) + 0.5), int(h * float(scale_factor) + 0.5)
rescaled_img = cv2.resize(img, new_size, interpolation=cv2.INTER_LINEAR)
return rescaled_img, scale_factor
def rescale_with_factor(img, scale_factor):
h, w = img.shape[:2]
new_size = int(w * float(scale_factor) + 0.5), int(h * float(scale_factor) + 0.5)
return cv2.resize(img, new_size, interpolation=cv2.INTER_NEAREST)
def rescale_column(img, img_shape, gt_bboxes, gt_label, gt_num, config):
"""rescale operation for image"""
img_data, scale_factor = rescale_with_tuple(img, (config.img_width, config.img_height))
if img_data.shape[0] > config.img_height:
img_data, scale_factor2 = rescale_with_tuple(img_data, (config.img_height, config.img_height))
scale_factor = scale_factor * scale_factor2
gt_bboxes = gt_bboxes * scale_factor
gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_data.shape[1] - 1)
gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_data.shape[0] - 1)
pad_h = config.img_height - img_data.shape[0]
pad_w = config.img_width - img_data.shape[1]
assert ((pad_h >= 0) and (pad_w >= 0))
pad_img_data = np.zeros((config.img_height, config.img_width, 3)).astype(img_data.dtype)
pad_img_data[0:img_data.shape[0], 0:img_data.shape[1], :] = img_data
img_shape = (config.img_height, config.img_width, 1.0)
img_shape = np.asarray(img_shape, dtype=np.float32)
return (pad_img_data, img_shape, gt_bboxes, gt_label, gt_num)
def rescale_column_test(img, img_shape, gt_bboxes, gt_label, gt_num, config):
"""rescale operation for image of eval"""
img_data, scale_factor = rescale_with_tuple(img, (config.img_width, config.img_height))
if img_data.shape[0] > config.img_height:
img_data, scale_factor2 = rescale_with_tuple(img_data, (config.img_height, config.img_height))
scale_factor = scale_factor * scale_factor2
pad_h = config.img_height - img_data.shape[0]
pad_w = config.img_width - img_data.shape[1]
assert ((pad_h >= 0) and (pad_w >= 0))
pad_img_data = np.zeros((config.img_height, config.img_width, 3)).astype(img_data.dtype)
pad_img_data[0:img_data.shape[0], 0:img_data.shape[1], :] = img_data
img_shape = np.append(img_shape, (scale_factor, scale_factor))
img_shape = np.asarray(img_shape, dtype=np.float32)
return (pad_img_data, img_shape, gt_bboxes, gt_label, gt_num)
def resize_column(img, img_shape, gt_bboxes, gt_label, gt_num, config):
"""resize operation for image"""
img_data = img
h, w = img_data.shape[:2]
img_data = cv2.resize(
img_data, (config.img_width, config.img_height), interpolation=cv2.INTER_LINEAR)
h_scale = config.img_height / h
w_scale = config.img_width / w
scale_factor = np.array(
[w_scale, h_scale, w_scale, h_scale], dtype=np.float32)
img_shape = (config.img_height, config.img_width, 1.0)
img_shape = np.asarray(img_shape, dtype=np.float32)
gt_bboxes = gt_bboxes * scale_factor
gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1)
gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1)
return (img_data, img_shape, gt_bboxes, gt_label, gt_num)
def resize_column_test(img, img_shape, gt_bboxes, gt_label, gt_num, config):
"""resize operation for image of eval"""
img_data = img
h, w = img_data.shape[:2]
img_data = cv2.resize(
img_data, (config.img_width, config.img_height), interpolation=cv2.INTER_LINEAR)
h_scale = config.img_height / h
w_scale = config.img_width / w
scale_factor = np.array(
[w_scale, h_scale, w_scale, h_scale], dtype=np.float32)
img_shape = np.append(img_shape, (h_scale, w_scale))
img_shape = np.asarray(img_shape, dtype=np.float32)
gt_bboxes = gt_bboxes * scale_factor
gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1)
gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1)
return (img_data, img_shape, gt_bboxes, gt_label, gt_num)
def impad_to_multiple_column(img, img_shape, gt_bboxes, gt_label, gt_num, config):
"""impad operation for image"""
img_data = cv2.copyMakeBorder(img,
0, config.img_height - img.shape[0], 0, config.img_width - img.shape[1],
cv2.BORDER_CONSTANT,
value=0)
img_data = img_data.astype(np.float32)
return (img_data, img_shape, gt_bboxes, gt_label, gt_num)
def imnormalize_column(img, img_shape, gt_bboxes, gt_label, gt_num):
"""imnormalize operation for image"""
# Computed from random subset of ImageNet training images
mean = np.asarray([123.675, 116.28, 103.53])
std = np.asarray([58.395, 57.12, 57.375])
img_data = img.copy().astype(np.float32)
cv2.cvtColor(img_data, cv2.COLOR_BGR2RGB, img_data) # inplace
cv2.subtract(img_data, np.float64(mean.reshape(1, -1)), img_data) # inplace
cv2.multiply(img_data, 1 / np.float64(std.reshape(1, -1)), img_data) # inplace
img_data = img_data.astype(np.float32)
return (img_data, img_shape, gt_bboxes, gt_label, gt_num)
def flip_column(img, img_shape, gt_bboxes, gt_label, gt_num):
"""flip operation for image"""
img_data = img
img_data = np.flip(img_data, axis=1)
flipped = gt_bboxes.copy()
_, w, _ = img_data.shape
flipped[..., 0::4] = w - gt_bboxes[..., 2::4] - 1
flipped[..., 2::4] = w - gt_bboxes[..., 0::4] - 1
return (img_data, img_shape, flipped, gt_label, gt_num)
def transpose_column(img, img_shape, gt_bboxes, gt_label, gt_num):
"""transpose operation for image"""
img_data = img.transpose(2, 0, 1).copy()
img_data = img_data.astype(np.float32)
img_shape = img_shape.astype(np.float32)
gt_bboxes = gt_bboxes.astype(np.float32)
gt_label = gt_label.astype(np.int32)
gt_num = gt_num.astype(np.bool)
return (img_data, img_shape, gt_bboxes, gt_label, gt_num)
def photo_crop_column(img, img_shape, gt_bboxes, gt_label, gt_num):
"""photo crop operation for image"""
random_photo = PhotoMetricDistortion()
img_data, gt_bboxes, gt_label = random_photo(img, gt_bboxes, gt_label)
return (img_data, img_shape, gt_bboxes, gt_label, gt_num)
def expand_column(img, img_shape, gt_bboxes, gt_label, gt_num):
"""expand operation for image"""
expand = Expand()
img, gt_bboxes, gt_label = expand(img, gt_bboxes, gt_label)
return (img, img_shape, gt_bboxes, gt_label, gt_num)
def preprocess_fn(image, box, is_training, config):
"""Preprocess function for dataset."""
def _infer_data(image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert):
image_shape = image_shape[:2]
input_data = image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert
if config.keep_ratio:
input_data = rescale_column_test(*input_data, config=config)
else:
input_data = resize_column_test(*input_data, config=config)
input_data = imnormalize_column(*input_data)
output_data = transpose_column(*input_data)
return output_data
def _data_aug(image, box, is_training):
"""Data augmentation function."""
pad_max_number = config.num_gts
if pad_max_number < box.shape[0]:
box = box[:pad_max_number, :]
image_bgr = image.copy()
image_bgr[:, :, 0] = image[:, :, 2]
image_bgr[:, :, 1] = image[:, :, 1]
image_bgr[:, :, 2] = image[:, :, 0]
image_shape = image_bgr.shape[:2]
gt_box = box[:, :4]
gt_label = box[:, 4]
gt_iscrowd = box[:, 5]
gt_box_new = np.pad(gt_box, ((0, pad_max_number - box.shape[0]), (0, 0)), mode="constant", constant_values=0)
gt_label_new = np.pad(gt_label, ((0, pad_max_number - box.shape[0])), mode="constant", constant_values=-1)
gt_iscrowd_new = np.pad(gt_iscrowd, ((0, pad_max_number - box.shape[0])), mode="constant", constant_values=1)
gt_iscrowd_new_revert = (~(gt_iscrowd_new.astype(np.bool))).astype(np.int32)
if not is_training:
return _infer_data(image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert)
flip = (np.random.rand() < config.flip_ratio)
expand = (np.random.rand() < config.expand_ratio)
input_data = image_bgr, image_shape, gt_box_new, gt_label_new, gt_iscrowd_new_revert
if expand:
input_data = expand_column(*input_data)
if config.keep_ratio:
input_data = rescale_column(*input_data, config=config)
else:
input_data = resize_column(*input_data, config=config)
input_data = imnormalize_column(*input_data)
if flip:
input_data = flip_column(*input_data)
output_data = transpose_column(*input_data)
return output_data
return _data_aug(image, box, is_training)
def create_coco_label(is_training, config):
"""Get image path and annotation from COCO."""
from pycocotools.coco import COCO
coco_root = config.coco_root
data_type = config.val_data_type
if is_training:
data_type = config.train_data_type
# Classes need to train or test.
train_cls = config.coco_classes
train_cls_dict = {}
for i, cls in enumerate(train_cls):
train_cls_dict[cls] = i
anno_json = os.path.join(coco_root, config.instance_set.format(data_type))
if hasattr(config, 'train_set') and is_training:
anno_json = os.path.join(coco_root, config.train_set)
if hasattr(config, 'val_set') and not is_training:
anno_json = os.path.join(coco_root, config.val_set)
coco = COCO(anno_json)
classs_dict = {}
cat_ids = coco.loadCats(coco.getCatIds())
for cat in cat_ids:
classs_dict[cat["id"]] = cat["name"]
image_ids = coco.getImgIds()
image_files = []
image_anno_dict = {}
for img_id in image_ids:
image_info = coco.loadImgs(img_id)
file_name = image_info[0]["file_name"]
anno_ids = coco.getAnnIds(imgIds=img_id, iscrowd=None)
anno = coco.loadAnns(anno_ids)
image_path = os.path.join(coco_root, data_type, file_name)
annos = []
for label in anno:
bbox = label["bbox"]
class_name = classs_dict[label["category_id"]]
if class_name in train_cls:
x1, x2 = bbox[0], bbox[0] + bbox[2]
y1, y2 = bbox[1], bbox[1] + bbox[3]
annos.append([x1, y1, x2, y2] + [train_cls_dict[class_name]] + [int(label["iscrowd"])])
image_files.append(image_path)
if annos:
image_anno_dict[image_path] = np.array(annos)
else:
image_anno_dict[image_path] = np.array([0, 0, 0, 0, 0, 1])
return image_files, image_anno_dict
def parse_json_annos_from_txt(anno_file, config):
"""for user defined annotations text file, parse it to json format data"""
if not os.path.isfile(anno_file):
raise RuntimeError("Evaluation annotation file {} is not valid.".format(anno_file))
annos = {
"images": [],
"annotations": [],
"categories": []
}
# set categories field
for i, cls_name in enumerate(config.coco_classes):
annos["categories"].append({"id": i, "name": cls_name})
with open(anno_file, "rb") as f:
lines = f.readlines()
img_id = 1
anno_id = 1
for line in lines:
line_str = line.decode("utf-8").strip()
line_split = str(line_str).split(' ')
# set image field
file_name = line_split[0]
annos["images"].append({"file_name": file_name, "id": img_id})
# set annotations field
for anno_info in line_split[1:]:
anno = anno_info.split(",")
x = float(anno[0])
y = float(anno[1])
w = float(anno[2]) - float(anno[0])
h = float(anno[3]) - float(anno[1])
category_id = int(anno[4])
iscrowd = int(anno[5])
annos["annotations"].append({"bbox": [x, y, w, h],
"area": w * h,
"category_id": category_id,
"iscrowd": iscrowd,
"image_id": img_id,
"id": anno_id})
anno_id += 1
img_id += 1
return annos
def create_train_data_from_txt(image_dir, anno_path):
"""Filter valid image file, which both in image_dir and anno_path."""
def anno_parser(annos_str):
"""Parse annotation from string to list."""
annos = []
for anno_str in annos_str:
anno = anno_str.strip().split(",")
xmin, ymin, xmax, ymax = list(map(float, anno[:4]))
cls_id = int(anno[4])
iscrowd = int(anno[5])
annos.append([xmin, ymin, xmax, ymax, cls_id, iscrowd])
return annos
image_files = []
image_anno_dict = {}
if not os.path.isdir(image_dir):
raise RuntimeError("Path given is not valid.")
if not os.path.isfile(anno_path):
raise RuntimeError("Annotation file is not valid.")
with open(anno_path, "rb") as f:
lines = f.readlines()
for line in lines:
line_str = line.decode("utf-8").strip()
line_split = str(line_str).split(' ')
file_name = line_split[0]
image_path = os.path.join(image_dir, file_name)
if os.path.isfile(image_path):
image_anno_dict[image_path] = anno_parser(line_split[1:])
image_files.append(image_path)
return image_files, image_anno_dict
def data_to_mindrecord_byte_image(config, dataset="coco", is_training=True, prefix="fasterrcnn.mindrecord", file_num=8):
"""Create MindRecord file."""
mindrecord_dir = config.mindrecord_dir
mindrecord_path = os.path.join(mindrecord_dir, prefix)
writer = FileWriter(mindrecord_path, file_num)
if dataset == "coco":
image_files, image_anno_dict = create_coco_label(is_training, config=config)
else:
image_files, image_anno_dict = create_train_data_from_txt(config.image_dir, config.anno_path)
fasterrcnn_json = {
"image": {"type": "bytes"},
"annotation": {"type": "int32", "shape": [-1, 6]},
}
writer.add_schema(fasterrcnn_json, "fasterrcnn_json")
for image_name in image_files:
with open(image_name, 'rb') as f:
img = f.read()
annos = np.array(image_anno_dict[image_name], dtype=np.int32)
row = {"image": img, "annotation": annos}
writer.write_raw_data([row])
writer.commit()
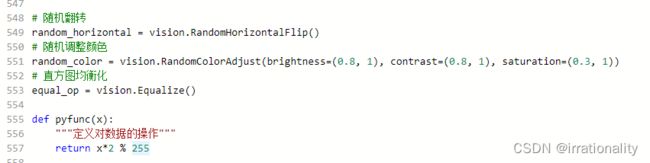
# 随机翻转
random_horizontal = vision.RandomHorizontalFlip()
# 随机调整颜色
random_color = vision.RandomColorAdjust(brightness=(0.8, 1), contrast=(0.8, 1), saturation=(0.3, 1))
# 直方图均衡化
equal_op = vision.Equalize()
def pyfunc(x):
"""定义对数据的操作"""
return x*2 % 255
def create_fasterrcnn_dataset(config, mindrecord_file, batch_size=2, device_num=1, rank_id=0, is_training=True,
num_parallel_workers=8, python_multiprocessing=False):
"""Create FasterRcnn dataset with MindDataset."""
cv2.setNumThreads(0)
de.config.set_prefetch_size(8)
ds = de.MindDataset(mindrecord_file, columns_list=["image", "annotation"], num_shards=device_num, shard_id=rank_id,
num_parallel_workers=4, shuffle=is_training)
decode = ms.dataset.vision.Decode()
ds = ds.map(input_columns=["image"], operations=[decode, random_horizontal, random_color, equal_op, pyfunc])
compose_map_func = (lambda image, annotation: preprocess_fn(image, annotation, is_training, config=config))
if is_training:
ds = ds.map(input_columns=["image", "annotation"],
output_columns=["image", "image_shape", "box", "label", "valid_num"],
column_order=["image", "image_shape", "box", "label", "valid_num"],
operations=compose_map_func, python_multiprocessing=python_multiprocessing,
num_parallel_workers=num_parallel_workers)
ds = ds.batch(batch_size, drop_remainder=True)
else:
ds = ds.map(input_columns=["image", "annotation"],
output_columns=["image", "image_shape", "box", "label", "valid_num"],
column_order=["image", "image_shape", "box", "label", "valid_num"],
operations=compose_map_func,
num_parallel_workers=num_parallel_workers)
ds = ds.batch(batch_size, drop_remainder=True)
return ds
效果如下

可见,我们的pyfunc起到了一定边缘提取的作用