Python2和 Python3都有哪些区别?
很多新同学在学习Python的过程当中,都会犹豫是学Python2还是Python3呢,小编这里给大家整理了一下关于Python2和Python3都有哪些区别,一起看看吧,希望对迷茫的同学有所帮助~
1.性能
Py3.0 运行 pystone benchmark 的速度比 Py2.5 慢 30%。Guido 认为 Py3.0 有极大的优化空间,在字符串和整形操作上可以取得很好的优化结果。Py3.1 性能比 Py2.5 慢 15%,还有很大的提升空间。
2.编码
Py3.X 源码文件默认使用 utf-8 编码
3. 语法
1)去除了<>,全部改用!=
2)去除``,全部改用 repr()
3)关键词加入 as 和 with,还有 True,False,None
4)整型除法返回浮点数,要得到整型结果,请使用//
5)加入 nonlocal 语句。使用 noclocal x 可以直接指派外围(非全局)变量
6)去除 print 语句,加入 print()函数实现相同的功能。同样的还有 exec 语句,已经改为exec()函数
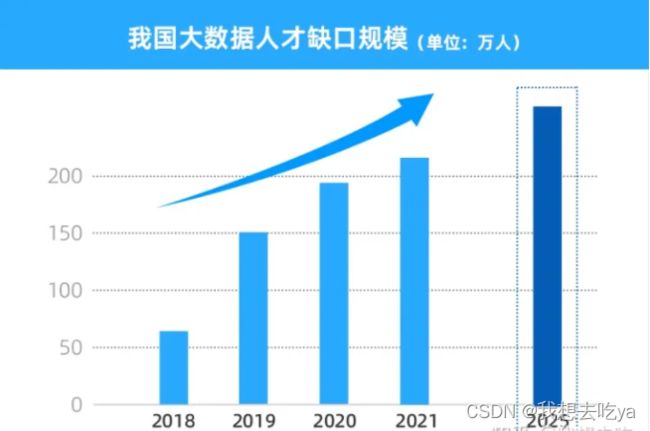
7)改变了顺序操作符的行为,例如 x 8)输入函数改变了,删除了 raw_input,用 input 代替: 2.X:guess = int(raw_input('Enter an integer : ')) # 读取键盘输入的方法 3.X:guess = int(input('Enter an integer : ')) 9)去除元组参数解包。不能 def(a, (b, c)):pass 这样定义函数了 10)新式的 8 进制字变量,相应地修改了 oct()函数。 11)增加了 2 进制字面量和 bin()函数 12)扩展的可迭代解包。在 Py3.X 里,a, b, *rest = seq 和 *rest, a = seq 都是合法的,只要求两点:rest 是 list,对象和 seq 是可迭代的。 13)新的 super(),可以不再给 super()传参数, 14)新的 metaclass 语法: class Foo(*bases, **kwds): 15)支持 class decorator。用法与函数 decorator 一样: 4. 字符串和字节串 1)现在字符串只有 str 一种类型,但它跟 2.x 版本的 unicode 几乎一样。 2)关于字节串,请参阅“数据类型”的第 2 条目 5.数据类型 1)Py3.X 去除了 long 类型,现在只有一种整型——int,但它的行为就像 2.X 版本的 long 2)新增了 bytes 类型,对应于 2.X 版本的八位串,定义一个 bytes 字面量的方法如下: str 对象和 bytes 对象可以使用.encode() (str -> bytes) or .decode() (bytes ->str)方法相互转化。 3)dict 的.keys()、.items 和.values()方法返回迭代器,而之前的 iterkeys()等函数都被废弃。同时去掉的还有dict.has_key(),用 in 替代它吧 6.面向对象 1)引入抽象基类(Abstraact Base Classes,ABCs)。 2)容器类和迭代器类被 ABCs 化。 3)迭代器的 next()方法改名为__next__(),并增加内置函数 next(),用以调用迭代器的__next__()方法 4)增加了@abstractmethod 和 @abstractproperty 两个 decorator,编写抽象方法(属性)更加方便。 7.异常 1)所以异常都从 BaseException 继承,并删除了 StardardError 2)去除了异常类的序列行为和.message 属性 3)用 raise Exception(args)代替 raise Exception, args 语法 4)捕获异常的语法改变,引入了 as 关键字来标识异常实例 5)异常链,因为__context__在 3.0a1 版本中没有实现 8.模块变动 1)移除了cPickle模块,可以使用pickle模块代替。最终我们将会有一个透明高效的模块。 2)移除了 imageop 模块 3)移除了 audiodev, Bastion, bsddb185, exceptions, linuxaudiodev, md5, MimeWriter,mimify, popen2,rexec, sets, sha, stringold, strop, sunaudiodev, timing 和 xmllib 模块 4)移除了 bsddb 模块(单独发布,可以从 http://www.jcea.es/programacion/pybsddb.htm获取) 5)移除了 new 模块 6)os.tmpnam()和 os.tmpfile()函数被移动到 tmpfile 模块下 7)tokenize 模块现在使用 bytes 工作。主要的入口点不再是 generate_tokens,而是tokenize.tokenize() 9.其它 1)xrange() 改名为 range(),要想使用 range()获得一个 list,必须显式调用: list(range(10)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 2)bytes 对象不能 hash,也不支持 b.lower()、b.strip()和 b.split()方法,但对于后两者可以使用 b.strip(b’ \n\t\r \f’)和 b.split(b’ ‘)来达到相同目的 3)zip()、map()和 filter()都返回迭代器。而 apply()、 callable()、coerce()、execfile()、reduce()和 reload ()函数都被去除了现在可以使用 hasattr()来替换callable(). hasattr()的语法如:hasattr(string, ‘name’) 4) string.letters 和 相 关 的 .lowercase 和 .uppercase 被去除 , 请改用string.ascii_letters 等 5)如果 x < y 的不能比较,抛出 TypeError 异常。2.x 版本是返回伪随机布尔值的 6)__getslice__系列成员被废弃。a[i:j]根据上下文转换为 a.getitem(slice(I, j))或 __setitem__和 __delitem__调用 7)file 类被废弃 Python近段时间一直涨势迅猛,在各大编程排行榜中崭露头角,得益于它多功能性和简单易上手的特性,让它可以在很多不同的工作中发挥重大作用。 正因如此,目前几乎所有大中型互联网企业都在使用 Python 完成各种各样的工作,比如Web应用开发、自动化运维、人工智能领域、网路爬虫、科学计算、游戏开发等领域均已离不开Python。 特别是在和数据相关的领域,比如数据科学、数据分析、机器学习等领域的首选语言都是Python! 我们可以看到,随着数字经济发展按下“快进键”,擅长Python的大数据人才越来越受企业青睐,不仅招聘需求量大,就业薪资也非常高! 据《新职业——大数据工程技术人员就业景气现状分析报告》显示,预计2025年前大数据人才需求仍保持 30%-40% 的增速,行业人才需求量达到 250 万 。 2022年春季,互联网行业的招聘规模虽然仍然保持增长,同比增速为 13% ,但处于 2019 年以来的低点,而求职激烈程度则高于往年。 整体上看,核心的技术和产品类岗位仍然保持着较为密集的人才需求,主要的互联网技术方向上人才需求均有增长,而运营和销售类岗位的求职者竞争则明显加剧。 猎聘发布的《2022未来人才就业趋势报告》也指出,大数据排名第四,年薪达到25万多,比2018年同期上涨4.87万。 大数据的处理技术迫在眉睫,近年来各国政府和全球学术界都掀起了一场大数据技术的革命,众人纷纷积极研究大数据的相关技术。很多国家都把大数据技术研究上升到了国家战略高度,提出了一系列的大数据技术研发计划,从而推动政府机构、学术界、相关行业和各类企业对大数据技术进行探索和研究。 可以说大数据是一种宝贵的战略资源,其潜在价值和增长速度正在改变着人类的工作、生活和思维方式。可以想象,在未来,各行各业都会积极拥抱大数据,积极探索数据挖掘和分析的新技术、新方法,从而更好地利用大数据。当然,大数据并不能主宰一切。大数据虽然能够发现“是什么”,却不能说明“为什么”;大数据提供的是些描述性的信息,而创新还是需要人类自己来实现。 根据《数据时代2025》白皮书预测:2025年,全球数据量将达到史无前例的163ZB 。 Kevin Kelly曾经这样预言:“大数据时代,没有人能够成为旁观者,数据将横扫一切。”。 随着大数据的不断普及,未来将会有更多的行业与之相结合,从而创造出更多的就业岗位,无论是比较火的金融、互联网等行业,还是像医疗、教育、城市规划等方面,都将需要大量的大数据人才。 薪资高、缺口大,自然成为职场人的“薪”选择! 任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关! Python+大数据学习路线图详细介绍 学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。 1.大数据数据开发基础MySQL8.0从入门到精通 MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。 2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程 学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。 2022版大数据Hadoop入门教程 2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程 学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。 数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程) 大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程) 学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。 1.python入门到精通(19天全) python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。 全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程 2.python编程进阶从零到搭建网站 学完本课程会掌握Python高级语法、多任务编程以及网络编程。 Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程 3.spark3.2从基础到精通 Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。 Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程 4.大数据Hive+Spark离线数仓工业项目实战 通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。 全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
pass
此前,BOSS直聘研究院发布的《 2022 年春季就业市场趋势观察》指出,受到 2021 年政策调控的影响,互联网行业的高速扩张开始降温。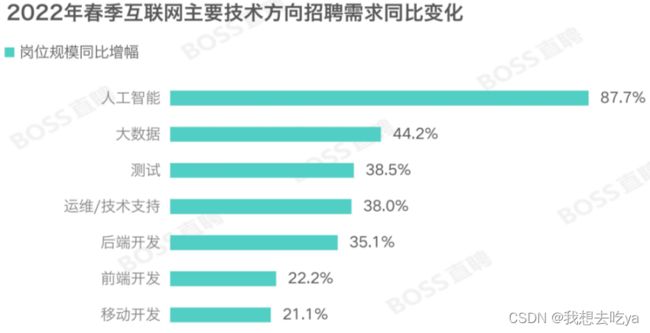
《报告》也指出,从岗位招聘和投递的供求对比来看,互联网核心的技术/测试/运维仍保持着较为密集的人才需求,主要体现在企业对以人工智能、数字孪生为代表的高技术岗位的需求,此类岗位同比保有两位数的高增长,相关从业者仍有较大的择业空间与机会。而产品/运营/策划、销售/商务/售前、客服/审核/售后等岗位的求职竞争随着互联网“降本增效”进一步加剧。第一阶段 大数据开发入门
第二阶段 大数据核心基础
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。第三阶段 千亿级数仓技术
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。第四阶段 PB内存计算