基于时空双向注意力的乘车需求预测模型——以新冠肺炎期间北京市为例
1.文章信息
《A Spatiotemporal Bidirectional Attention Based Ride-hailing Demand Prediction Model: A Case Study in Beijing during COVID-19》在2021年11月发表在期刊IEEE Transactions on Intelligent Transportation Systems上的文章。
2.摘要
新冠肺炎疫情严重影响了城市交通模式,包括居民的出行方式。预测城市拼车需求对疫情期间居民健康出行、合理平台运营、交通管制具有重要意义。本文提出了一种基于多头空间注意机制和双向注意机制的深度学习模型MOS-BiAtten,用于打车需求预测。该模型遵循具有多步预测的多输出策略的编码器-解码器框架。将预测结果和历史需求数据提取为双向注意流的两个方面,从而进一步探索历史、现在和未来信息之间复杂的时空关联。在北京新冠肺炎的真实数据集上对该模型进行了测试,实验结果表明,MOS-BiAtten比其他方法具有更好的性能。同时,用另一个数据集验证了模型的泛化性能。
3.介绍
该文章面临的两个挑战:
1.在一定时期内,所有区域的时空相关性都是复杂的。乘客需求分布的变化形成了时空相关性。准确的客流需求预测需要提取不同时段不同区域的时空相关性。因此,重要的是从全局上确定哪些区域和时间段与预测区域和时间段的乘客需求更相关。
2.多步预测可以为流行病交通控制行动提供更多的响应时间。久而久之,由于缺乏真实值,将没有时空相关性可用于预测接下来的步骤。已知的历史乘客需求的最后一步不足以支持多步预测。因此,我们需要新的信息来弥补后续步骤缺失的时空相关性。
文章提出了一种基于双向注意机制的深度学习结构的预测方法MOS-BiAtten,用于短期乘车需求预测。主要贡献有三个方面:
1.模型中设计了两种注意机制层:头空间注意机制(MH-SA)层和双向注意机制(Bi-Atten)层。MH-SA层用来确定在空间域中应该重点关注的部分,并在某些时段对局部空间相关性进行建模。Bi-Atten接收更多信息以扩展感受野,并进一步从历史、现在和未来信息中学习全局时空相关性。
2.将预先预测的结果输入到模型中:LS-SVM模型用于计算预先预测的结果,该结果被输入到MOS-BiAtten模型中。预先预测的结果补偿了被用作未来乘客需求信息预测步骤的真实值的缺乏。它还支持多步输出。
3.为了评估MOS-BiAtten模型的有效性,基于新冠肺炎期间真实世界的乘客需求数据集进行了大量实验,并在另一个来自非流行病的数据集上验证了该模型的通用性。结果表明,该模型明显优于其他方法。
4.方法
MOS-BiAtten模型的架构如图1所示。首先,介绍了编码器-解码器的框架,并介绍了一种预测的方法来计算结果提供给解码器。其次,描述了注意机制层,包括多头空间注意层和双向注意层来捕捉时空相关性。最后,应用多输出策略得到多步预测结果。
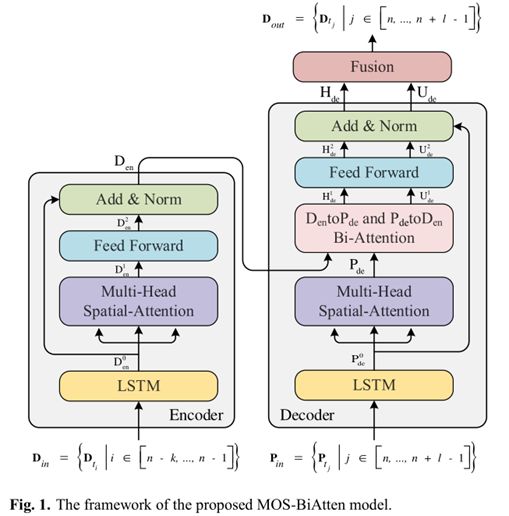
A.编码器和解码器
编码器由一个长短期记忆层(LSTM层)、一个多头空间注意机制层、全连接前馈网络层(FC-FF层)和具有层标准化的残差连接(规范层)。
LSTM的优势在于探索时间序列数据中的长期相关性。然而,LSTM通常在提取空间依赖方面表现不佳。为了克服这个缺点,提出MH-SA层来学习乘客需求的动态空间相关性。FC-FF层提供线性变换来整合要素表示,并输出固定格式的残差连接。
解码器的结构类似于编码器,由一个LSTM层、两个注意机制层、一个FC-FF层和一个Norm层组成。
B.一种解码器的预测方法
众所周知,对于多步提前预测,在预测范围内没有真实值。因此,只能利用先前的预测结果和隐藏状态来逐步获得后续周期中的每一步预测。然而,预测误差以这种方式逐渐累积。为了处理这些问题,使用最小二乘LS-SVM计算一个预先预测的结果作为解码器的输入。预测结果为多步预测提供了未来乘客需求的参考信息。MOS-BiAtten模型将预先预测结果与注意机制层和多输出策略相结合,将全面捕捉近期、当前和未来需求之间的相关性,从而实现更好的多步预测。训练步骤如下:

C.注意力机制层
注意机制层由两部分组成::多头空间注意机制层(MH-SA层)和双向注意层(Bi-Atten层),这是本文的核心部分。图2 (a)呈现了MH-SA层的内部结构,而图2 (b)展示了双头注意力层的计算过程。接下来,分别介绍了MH-SA层和Bi-Atten层的主要组成部分。
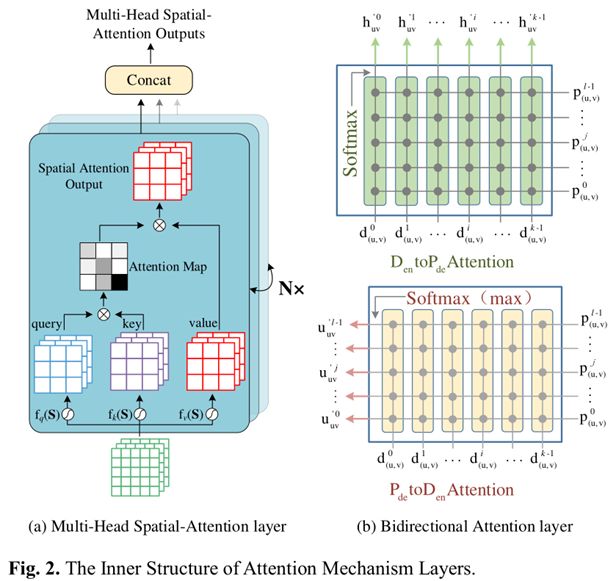
MH-SA层可以被视为将一组查询键对和值映射到输出。Query指出每对键值应该关注多少。Key用于计算注意力矩阵,注意力矩阵被视为成对值的权重。values用于计算输出。简而言之,输出被计算为values的加权和,其中分配给每个value的权重由Quary与相应Key的兼容性函数来计算。由于乘客需求的动态空间依赖性,MH-SA层补充了LSTM层,以获取空间和时间域中预测需求和历史输入之间的相关性。注意力图确定与配对键相关的每个值的权重。多头注意力将重复N次的空间注意力输出的结果连接在一起。
在每个时间步计算双向注意力,并允许所获得的注意力向量沿着模型中的下一层流动。这能够减少由早期汇总引起的信息损失。与其他注意机制不同,每个时间步的双向注意不仅依赖于前一时间步的信息,而且关注于先前、当前和未来需求表征之间的交互。显然,在两个方向上设计了注意机制,可以为两个领域提供互补的信息。这避免了遗漏重要信息。
D.多步输出策略
大多数现有的在输出层具有RNNs单元的模型只能通过迭代过程预测多个步骤。这意味着模型应该执行解码器l次来预测期望的步骤l。这不仅消耗太多时间,而且容易忽略预测步骤之间的相关性特征。相比之下,采用多输出策略的MOS-BiAtten模型可以预测所有区域的未来乘客需求,因此能够保持区域之间和观测时间间隔之间的乘客需求的时空相关性。
受BiDAF网络设计的启发,由注意力向量处理的解码器状态和编码器状态通过以下方式融合:
![]()
5.实验
数据集
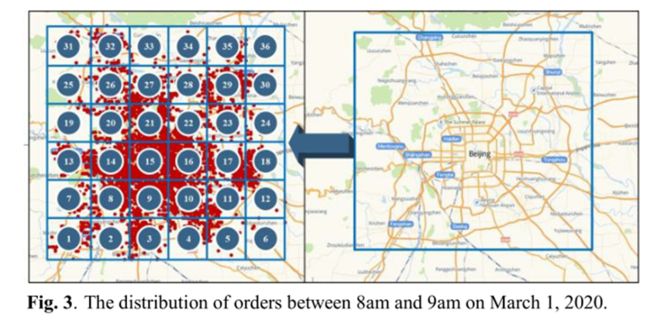
BJ-taxi数据集:该数据集的研究地点位于中国北京市中心,经度从116.05 E至116.80 E,纬度从39.65 N至40.25 N。数据集被分成20分钟的时间间隔。为了消除区域形状等外界因素对空间特征的影响,将研究区域等分为6 × 6个网格,每个区域约为一个边长10公里的正方形,如图3所示。乘客的在线需求摘自2020年3月1日至3月31日的滴滴出行,其中包含每天超过170,000个请求订单。将用作模型输入的乘客需求数据可以通过在一段时间间隔内累加一个区域内的请求来获得。图3显示了2020年3月1日上午8点到9点之间的订单分布。可以看出,由于位置不同,每个地区的需求也不同。
HK-Taxi数据集:数据集收集自中国海口市,时间范围为2017年5月1日至2017年7月31日。时间序列被分成20分钟的时间间隔。该数据集的研究区域划分为6 × 6个网格,范围为东经110.25°至110.42°和北纬19.95°至20.05°。每个区域大约是一个边长2公里的正方形。该数据集每天包含大约80,000个请求。
两个数据集包含的时间跨度和区域大小不同,可以验证模型的可靠性。在实验中,通过最大-最小归一化将乘客需求值归一化到范围[-1,1]内。此外,每个数据集的20%用作测试集,其余部分按七比三的比例分为训练集和验证集。
超参数设置
MOS-BiAtten模型的超参数主要包括:学习速率(LR)、批量和训练时间。随机搜索通常用于优化超参数。参考常用设置,手动调整以选择最佳设置。最后,将学习率设置为0.001,批量大小固定为32。将训练epoch设置为500,以确保结果收敛。此外,Adam优化器用于训练模型。
数据样本的数量,选择预测步骤l来确定输出步骤的数量。为了确保多步提前预测,基于深度学习的方法采用它们各自的多输出策略。对于不同实验中的所有现有技术方法,回看时间窗k被设置为24,并且预测步长l被设置为1、2、3或4。所有比较方法的参数设置都符合使性能最佳的参数设置。每个实验运行30次,取平均结果。
模型对比
MOS-BiAtten模型在所有场景中的所有评估指标下都获得了最佳性能,证明了其在在线乘车需求预测中的有效性。特别地,MOS-BiAtten模型具有如下所述的高预测精度、强时空预测能力和强多输出预测能力。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!