逻辑回归总结
文章目录
- 1. 简介
- 2. 逻辑回归模型的数学推导
-
- 2.1 逻辑回归的损失函数
- 2.2 极大似然估计(MLE)
- 2.3 使用梯度下降方法求的最佳参数 w w w
- 2.4 为什么可以用梯度下降法?
- 3. 逻辑回归的可解释性
- 4. 逻辑回归的决策边界是否是线性的?
- 5. 总结
- 6. 逻辑回归的优缺点
- 7. 如何使用逻辑回归做非线性分类
- 9. 逻辑回归和SVM的区别是什么?
- 10. 逻辑回归与树模型的区别
- 8. 参考
1. 简介
逻辑回归本名应该叫对数几率回归,是线性回归的一种推广,所以我们在统计学上也称之为广义线性模型。线性回归针对的是标签为连续值的机器学习任务,那如果我们想用线性模型来做分类任何可行吗?答案当然是肯定的,这就需要用到sigmoid函数,将一个数值转化成0-1的概率。
相较于线性回归的因变量 y 为连续值,逻辑回归的因变量则是一个 0/1 的二分类值,这就需要我们建立一种映射将原先的实值转化为 0/1 值。这时候就要请出我们熟悉的 sigmoid 函数了:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
它的函数图像如下所示:
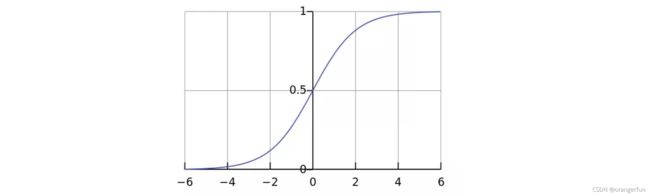
sigmoid 函数有一个很好的特性就是其求导计算等于下式,这给我们后续求交叉熵损失的梯度时提供了很大便利。
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) \mathrm{f}^{\prime}(\mathrm{x})=\mathrm{f}(\mathrm{x})(1-\mathrm{f}(\mathrm{x})) f′(x)=f(x)(1−f(x))
2. 逻辑回归模型的数学推导
2.1 逻辑回归的损失函数
由 sigmoid 函数可知逻辑回归模型的基本形式为:
y = 1 1 + e − ( w T x + b ) y = \frac{1}{1+e^{-(w^{T}x+b)}} y=1+e−(wTx+b)1
损失函数就是用来衡量模型的输出与真实输出的差别。
假设只有两个标签1和0, y n ∈ { 0 , 1 } y_n \in \{0, 1\} yn∈{0,1} 。我们把采集到的任何一组样本看做一个事件的话,那么这个事件发生的概率假设为p。我们的模型y的值等于标签为1的概率也就是p。(注意:为了方便,在下面的推导中暂时忽略偏置 b b b)
P y = 1 = 1 1 + e − w T x = p P_{y=1}=\frac{1}{1+e^{-\boldsymbol{w}^{T} \boldsymbol{x}}}=p Py=1=1+e−wTx1=p
因为标签不是1就是0,因此标签为0的概率就是: y y = 0 = 1 − p y_{y=0}=1-p yy=0=1−p。我们把单个样本看做一个事件,那么这个事件发生的概率就是:
P ( y ∣ x ) = { p , y = 1 1 − p , y = 0 P(y \mid \boldsymbol{x})=\left\{\begin{array}{r} p, y=1 \\ 1-p, y=0 \end{array}\right. P(y∣x)={p,y=11−p,y=0
上式等价于:
P ( y i ∣ x i ) = p y i ( 1 − p ) 1 − y i P\left(y_{i} \mid \boldsymbol{x}_{i}\right)=p^{y_{i}}(1-p)^{1-y_{i}} P(yi∣xi)=pyi(1−p)1−yi
上式的含义是:我们采集到了一个样本 { x i , y i } \{x_i, y_i\} {xi,yi}。对这个样本,它的标签是 y i y_i yi的概率是 p y i ( 1 − p ) 1 − y i p^{y_{i}}(1-p)^{1-y_{i}} pyi(1−p)1−yi。 (当y=1,结果是p;当y=0,结果是1-p)。
如果我们采集到了一组数据一共N个样本, { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) … ( x N , y N ) } \left\{\left(\boldsymbol{x}_{1}, y_{1}\right),\left(\boldsymbol{x}_{2}, y_{2}\right),\left(\boldsymbol{x}_{3}, y_{3}\right) \ldots\left(\boldsymbol{x}_{N}, y_{N}\right)\right\} {(x1,y1),(x2,y2),(x3,y3)…(xN,yN)} ,这个合成在一起的合事件发生的总概率怎么求呢?(看作所有事件一起发生的概率)其实就是将每一个样本发生的概率相乘就可以了,即采集到这组样本的概率:
P 总 = P ( y 1 ∣ x 1 ) P ( y 2 ∣ x 2 ) P ( y 3 ∣ x 3 ) … P ( y N ∣ x N ) = ∏ n = 1 N p y n ( 1 − p ) 1 − y n \begin{aligned} P_{\text {总 }} &=P\left(y_{1} \mid \boldsymbol{x}_{1}\right) P\left(y_{2} \mid \boldsymbol{x}_{2}\right) P\left(y_{3} \mid \boldsymbol{x}_{3}\right) \ldots P\left(y_{N} \mid \boldsymbol{x}_{N}\right) \\ &=\prod_{n=1}^{N} p^{y_{n}}(1-p)^{1-y_{n}} \end{aligned} P总 =P(y1∣x1)P(y2∣x2)P(y3∣x3)…P(yN∣xN)=n=1∏Npyn(1−p)1−yn
注意 P 总 P_总 P总 是一个函数,并且未知的量只有 w w w(在p里面)
那么我们可以得到对数损失函数:
F ( w ) = ln ( P 总 ) = ln ( ∏ n = 1 N p y n ( 1 − p ) 1 − y n ) = ∑ n = 1 N ln ( p y n ( 1 − p ) 1 − y n ) = ∑ n = 1 N ( y n ln ( p ) + ( 1 − y n ) ln ( 1 − p ) ) \begin{aligned} F(\boldsymbol{w})=\ln \left(P_{\text {总 }}\right) &=\ln \left(\prod_{n=1}^{N} p^{y_{n}}(1-p)^{1-y_{n}}\right) \\ &=\sum_{n=1}^{N} \ln \left(p^{y_{n}}(1-p)^{1-y_{n}}\right) \\ &=\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right) \end{aligned} F(w)=ln(P总 )=ln(n=1∏Npyn(1−p)1−yn)=n=1∑Nln(pyn(1−p)1−yn)=n=1∑N(ynln(p)+(1−yn)ln(1−p))
其中, p = 1 1 + e − w T x i p = \frac{1}{1+e^{-\boldsymbol{w}^{T} \boldsymbol{x_i}}} p=1+e−wTxi1,损失函数可以理解成衡量我们当前的模型的输出结果,跟实际的输出结果之间的差距的一种函数。这里的损失函数的值等于事件发生的总概率,我们希望它越大越好。但是跟损失的含义有点儿违背,因此也可以在前面取个负号
2.2 极大似然估计(MLE)
在真实世界中并不能直接看到概率是多少,我们只能观测到事件是否发生。也就是说,我们只能知道一个样本它实际的标签是1还是0。那么我们如何估计参数 w w w 跟b的值呢?最大似然估计MLE(Maximum Likelihood Estimation),就是一种估计参数的方法。他的主要思想就是,既然这个事件发生了,肯定不是出于偶然,那么我们就把它发生的概率最大化,从而求出参数
现在我们的问题变成了,找到一个 w ∗ w^{*} w∗,使得我们的总事件发生的概率 F ( w ) F(w) F(w)取得最大值。即:
w ∗ = arg max w F ( w ) = − arg min w F ( w ) ( 2.1 ) \boldsymbol{w}^{*}=\arg \max _{w} F(\boldsymbol{w})=-\arg \min _{w} F(\boldsymbol{w}) \,\,\,\,\,\,\,\,\,\,\,\, (2.1) w∗=argwmaxF(w)=−argwminF(w)(2.1)
2.3 使用梯度下降方法求的最佳参数 w w w
求式2.1结果我们使用梯度下降算法
关于求导的一些知识:
- 对于一个矩阵 A \bold A A乘以一个向量的方程 A x \bold{Ax} Ax对向量 x \bold x x求导结果为: A T \bold A^T AT
- 可以推导出: ( x T A ) ′ = A \left(\boldsymbol{x}^{T} \boldsymbol{A}\right)^{\prime}=\boldsymbol{A} (xTA)′=A
- sigmoid函数 g ( x ) g(x) g(x)求导结果为: g ( x ) ( 1 − g ( x ) ) g(x)(1-g(x)) g(x)(1−g(x))
所以我们能够事先算出:
p ′ = p ( 1 − p ) x p^{\prime}=p(1-p) \boldsymbol{x} p′=p(1−p)x
( 1 − p ) ′ = − p ( 1 − p ) x (1-p)^{\prime}=-p(1-p) \boldsymbol{x} (1−p)′=−p(1−p)x
接下来就可以对损失函数求导了:
∇ F ( w ) = ∇ ( ∑ n = 1 N ( y n ln ( p ) + ( 1 − y n ) ln ( 1 − p ) ) ) = ∑ ( y n ln ′ ( p ) + ( 1 − y n ) ln ′ ( 1 − p ) ) = ∑ ( ( y n 1 p p ′ ) + ( 1 − y n ) 1 1 − p ( 1 − p ) ′ ) = ∑ N ( y n ( 1 − p ) x n − ( 1 − y n ) p x n ) = ∑ n = 1 N ( y n − p ) x n \begin{aligned} \nabla F(\boldsymbol{w}) &=\nabla\left(\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right)\right) \\ &=\sum\left(y_{n} \ln ^{\prime}(p)+\left(1-y_{n}\right) \ln ^{\prime}(1-p)\right) \\ &=\sum\left(\left(y_{n} \frac{1}{p} p^{\prime}\right)+\left(1-y_{n}\right) \frac{1}{1-p}(1-p)^{\prime}\right) \\ &=\sum_{N}\left(y_{n}(1-p) \boldsymbol{x}_{n}-\left(1-y_{n}\right) p \boldsymbol{x}_{n}\right) \\ &=\sum_{n=1}^{N}\left(y_{n}-p\right) \boldsymbol{x}_{n} \end{aligned} ∇F(w)=∇(n=1∑N(ynln(p)+(1−yn)ln(1−p)))=∑(ynln′(p)+(1−yn)ln′(1−p))=∑((ynp1p′)+(1−yn)1−p1(1−p)′)=N∑(yn(1−p)xn−(1−yn)pxn)=n=1∑N(yn−p)xn
即:
∇ F ( w ) = ∑ n = 1 N ( y n − 1 1 + e − w T x n ) x n \nabla F(\boldsymbol{w})=\sum_{n=1}^{N}\left(y_{n}-\frac{1}{1+e^{-\boldsymbol{w}^{T} \boldsymbol{x}_{n}}}\right) \boldsymbol{x}_{n} ∇F(w)=n=1∑N(yn−1+e−wTxn1)xn
使用梯度下降更新参数:
w t + 1 = w t + η ∇ F \boldsymbol{w}_{t+1}=\boldsymbol{w}_{t}+\eta \nabla F wt+1=wt+η∇F
注意:通常梯度下降是减号,但是此处f(w)前有个减号在求导的时候没有添加上去,负负得正,故此处是加号
2.4 为什么可以用梯度下降法?
因为逻辑回归的损失函数L是一个连续的凸函数(conveniently convex)。这样的函数的特征是,它只会有一个全局最优的点,不存在局部最优。对于GD跟SGD最大的潜在问题就是它们可能会陷入局部最优。然而这个问题在逻辑回归里面就不存在了,因为它的损失函数的良好特性,导致它并不会有好几个局部最优。当我们的GD跟SGD收敛以后,我们得到的极值点一定就是全局最优的点,因此我们可以放心地用GD跟SGD来求解。
3. 逻辑回归的可解释性
逻辑回归最大的特点就是可解释性很强。在模型训练完成之后,我们获得了一组n维的权重向量 w w w 跟偏差 b。
对于权重向量 w w w,它的每一个维度的值,代表了这个维度的特征对于最终分类结果的贡献大小。假如这个维度是正,说明这个特征对于结果是有正向的贡献,那么它的值越大,说明这个特征对于分类为正起到的作用越重要。
对于偏差b (Bias),一定程度代表了正负两个类别的判定的容易程度。假如b是0,那么正负类别是均匀的。如果b大于0,说明它更容易被分为正类,反之亦然。
根据逻辑回归里的权重向量在每个特征上面的大小,就能够对于每个特征的重要程度有一个量化的清楚的认识,这就是为什么说逻辑回归模型有着很强的解释性的原因
4. 逻辑回归的决策边界是否是线性的?
相当于问曲线 1 1 + e − w T x = 0.5 \frac{1}{1+e^{-\boldsymbol{w}^{T} \boldsymbol{x}}}=0.5 1+e−wTx1=0.5是否是线性的。我们对该式化简得到:
e − w T x = 1 = e 0 即 − w T x = 0 \begin{aligned} &e^{-\boldsymbol{w}^{T} \boldsymbol{x}}=1=e^{0} \\ &\text { 即 }-\boldsymbol{w}^{T} \boldsymbol{x}=0 \end{aligned} e−wTx=1=e0 即 −wTx=0
我们得到了一个等价的曲线,显然它是一个超平面(它在数据是二维的情况下是一条直线),逻辑回归的决策边界如下图所示。

5. 总结
-
两个假设
- 逻辑回归的第一个基本假设是假设数据服从伯努利分布(即0-1分布)
- 逻辑回归的第二个假设是正类的概率由sigmoid的函数计算
-
逻辑回归模型: y = 1 1 + e − w T x y=\frac{1}{1+e^{-\boldsymbol{w}^{T} \boldsymbol{x}}} y=1+e−wTx1
-
逻辑回归损失函数:
L ( w , b ) = ∑ n = 1 N ( y n ln ( p ) + ( 1 − y n ) ln ( 1 − p ) ) L(w, b)=\sum_{n=1}^{N}\left(y_{n} \ln (p)+\left(1-y_{n}\right) \ln (1-p)\right) L(w,b)=n=1∑N(ynln(p)+(1−yn)ln(1−p))
其中 y n y_n yn为实际label, p p p为预测值 -
参数求解(以一个样本为例):
w t + 1 = w t + η ( y n − 1 1 + e − w T x n ) x n \boldsymbol{w}_{t+1}=\boldsymbol{w}_{t}+\eta\left(y_{n}-\frac{1}{1+e^{-\boldsymbol{w}^{T} \boldsymbol{x}_{n}}}\right) \boldsymbol{x}_{n} wt+1=wt+η(yn−1+e−wTxn1)xn
6. 逻辑回归的优缺点
优点
- 形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
- 模型效果不错。在工程上是可以接受的(作为baseline),如果特征工程做的好,效果不会太差,并且特征工程可以大家并行开发,大大加快开发的速度。
- 训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化sgd发展比较成熟,训练的速度可以通过堆机器进一步提高,这样我们可以在短时间内迭代好几个版本的模型。
- 资源占用小,尤其是内存。因为只需要存储各个维度的特征值。
- 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cut off,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)。
缺点
- 准确率并不是很高。因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布。
- 很难处理数据不平衡的问题。举个例子:如果我们对于一个正负样本非常不平衡的问题比如正负样本比 10000:1.我们把所有样本都预测为正也能使损失函数的值比较小。但是作为一个分类器,它对正负样本的区分能力不会很好。
- 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据,或者进一步说,处理二分类的问题 。
- 逻辑回归本身无法筛选特征。有时候,我们会用gbdt来筛选特征,然后再上逻辑回归。
7. 如何使用逻辑回归做非线性分类
可以考虑和SVM一样,使用核函数,把数据升维,从线性不可分变成线性可分
9. 逻辑回归和SVM的区别是什么?
- 它们的目标都是减少“错误率”
- SVM通过寻找最佳划分超平面来减少错误率,相应的损失函数是hinge函数;
- 逻辑回归通过最大化样本输出到正确分类的概率来减少错误率,相应的损失函数是负对数似然
- 损失函数的优化方法不一样,逻辑回归用剃度下降法优化,svm用smo方法进行优化
- 逻辑回归产出的是概率值,而SVM只能产出是正类还是负类,不能产出概率
10. 逻辑回归与树模型的区别
- 逻辑回归更侧重于数据的整体结构(即全局性),因此其一般不会出现过拟合的情况;而对于决策树模型,其更侧重于对数据局部结构的分析(即局部性),因此其需要使用修剪的方式来避免过拟合现象的出现
- 逻辑回归更适合线性关系,能够找到适合线性分割;而决策树可以找到非线性分割
- 逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;决策树是对每一个特征做一个划分
8. 参考
如何使用Logistic回归做非线性分类
逻辑回归常见面试点总结!!!
逻辑回归 logistics regression 公式推导