YOLOV3论文学习
YOLOv3论文链接:https://pjreddie.com/media/files/papers/YOLOv3.pdf
综述
一、摘要
1、320*320的YOLOv3推理时间22ms,准确率28.2mAP,达到了SSD的精确度,推理速度却快了三倍。
2、基于.5mAp Iou 的YOLOv3的检测效果还比较不错,在Titan X上准确率为57.9AP50,推理时间为51ms,和RetinaNet在Titan X上推理相比,RetinaNet推理时间为198ms,准确率为57.5AP50
二、简介
本文将介绍对YOLOv3网络的处理过程、以及过程中做的一些无用功。
2 网络的处理
YOLOv3的思想都从别处借鉴来的,但是本文训练出来了更加优秀的分类器,下面将从零开始介绍它。
2.1 Bounding box prediction(边界框预测)
延续YOLO9000的策略,边界框的预测像锚框(anchor)一样采用dimension cluster(维度聚类)。网络会预测出边界框的四个坐标,[tx,ty,tw,th],如果该cell的左上角坐标在整幅图像中的偏移是(cx, cy),并且边界框宽和高的先验值是(pw, ph),则边界框的预测结果可以用公式计算:

在训练过程中我们采用均方和误差作为损失函数。假设预测框的ground truth是\hat{t} _{*} ,那么梯度的计算公式是groud truth 减预测值:
![]() 。
。
ground truth的值计算可以通过转换2.1小节中的公式。
YOLOv3使用**logistic regression(逻辑回归)**预测boungding box的objectness score(目标置信度)。如果一个目标的先验框和gound truth重合,则目标置信度得分为1.如果先验框的目标置信度得分不是1,我国通过设定阈值,将目标置信度得分小于阈值的预测过滤掉,根据论文【17】,我们把阈值设定为.5。
不同论文【17】,本文对每个ground truth仅分配一个先验框,如果一个先验框没有被分配到对应的ground truth,对坐标和分类预测不会产生影响,仅仅影响目标置信度的得分。
Q&A:
1、先验框分配给ground truth的策略
2.2. 分类预测
每个框用多标签分类预测边界框可能包含的分类。我们不适用softmax,因为我们发现这对良好的性能是不必要的,相反我们使用独立的逻辑分类器。在训练过程中,我们使用binary-cross entropy loss(二值交叉熵损失)预测分类。
该方法更适用复杂的开源数据集。例如数据集中目标有多个重叠的标签(woman/person)。使用softmax预测分类,印证了我们假设每个目标 只有一个标签,但是实际情况往往不是这样的。多标签分类能帮助数据更好的建模。
QUESTION:
什么是 binary cross entrop loss?
2.3 多尺度预测
YOLOv3可以在三个尺度上预测。本文采用类似于特征金字塔【8】的方法从三个尺度上提取特征。在我们的基础特征提取器中,我们添加了几个卷积层,最后预测得到的3维tensor是编码的边界框,目标置信度和分类预测。在本文的实验中才用了COCO数据集,在每个尺度上预测出3个边界框,因此预测得到的tensor维度是 N * N * [3 * (4 + 1 +80)],其中4代表边界框的偏移,1表示目标置信度,80表示COCO数据集80个分类。
接下来我们从之前的两层上通过2倍下采样提取特征图。同时我们也从更早的网络层中提取特征图,并且使用concatenation(拼接)将它和我们下采样得到的特征图进行融合。这种方法使我们能够从下采样特征中得到更有意义的语义信息。并且从更早的网络层中获取更细粒度的(finer-grained)信息。然后我们添加更多的卷积层来处理这个组合特征图,最终预测得到一个相似的tensor,尽管现在是两倍大。
按照这样的流程我们再执行一次,得到最后一个尺度的预测框。因此第三个尺度的预测得益于此前所有的计算,并且得益于更早网络层中细粒度的特征。
本文依然采用K-means聚类来确定先验框。首先任意选择9个簇和3个尺度,然后根据尺度均匀的划分9个簇。在COCO数据集上9个簇是:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116 × 90),(156 × 198),(373 × 326).
2.4 特征提取
本文使用一个新网络来执行特征提取。新网络混合了YOLOv2和Darknet-19中的方法。并且这种方法使得残差网络流行。新网络使用连续的33和11卷积层,但是现在也有一些shortcut connections,使得网络明显变大了。它有53个卷积层,因此我们称它,Darknet-53.

该新网络比Darknet-19更强大,同时也比ResNet-101或者ResNet-152更高效。在ImageNet数据上的运行结果如下表:
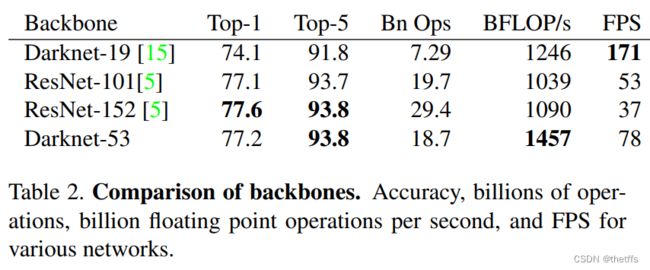
表中网络都是基于同样的设置训练的并且在256*256(single crop accuracy)上测试。运行时间是在Titan X上测试的。
DarkNet-53的优势总结如下:
1、每秒浮点操作数更高:这意味着能够更好的利用GPU.而且ResNet有太多的网络层,因此效率也不高。
2.5 训练
本文训练都采用标准化的方法:完整图像,没有 hard negtive mining、采用多尺度训练、大量数据增强、批处理归一化。使用DarkNet神经网络框架训练和测试【14】
3、怎样做
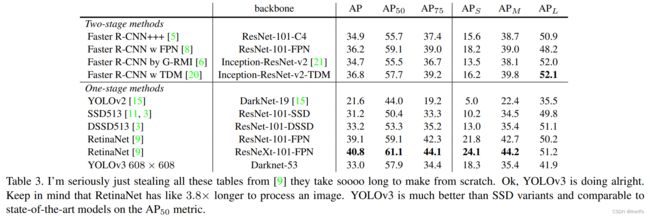
如下图所示,在COCO数据集上YOLOv3与SSD变体的(weird)mAP表现相当。但是速度前者是后者的三倍。尽管在下表中YOLOv3表现稍逊色于RetinaNet,但是当我们看到mAP(AP50)的数据,发现YOLOv3还是非常强大。表现和RetinaNet相当,并且远优于SSD变体,这表明YOLOv3很强大,并且擅长生成合适的目标边界框。
过去的YOLO系列网络适合检测小尺寸目标,但是现在趋势反过来了。YOLOv3基于多尺度预测有相当高的AP(S)表现。但是基于中、大尺寸目标检测表现相对较差。对此需要更多的调查去究其根本。当在AP50的前提条件下,绘制accuracy vs. speed曲线图可以看到YOLOv3比其他的检测system有显著的优势,即更快更好。
4、做的无用功
5、这些都意味着什么