YOLOv3论文
待解决区:
1、CNN正则化
2、CNN反向传播
3、除YOLOv3之外的目标检测算法
【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili
AP50的意思就是0.5IOU为阈值的mAP

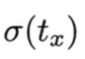 是sigmoid函数,把坐标限定在一个grid cell内。
是sigmoid函数,把坐标限定在一个grid cell内。
yolo的创新其实就在于把目标检测任务变成回归任务,用回归任务的损失函数平方误差来训练模型。
yolov3改成了sigmoid做逻辑回归。
一种尺度3个anchor,一共三种尺度共9个anchor,与ground truth的IOU最大的anchor作为正样本,负责拟合。置信度标签从以前版本的IOU直接变成了1。
YOLOV1/V2中使用IOU作为置信度标签有何不好?
1、很多预测框与GT的IOU最高只有0.7(最好的学生只有70分)
2、coco中小目标IOU对像素偏移很敏感,无法有效学习。

dimension prior就是anchor
以anchor为基准,加入偏移量,就得到了蓝色的预测框。
sigmoid函数的存在使得中心点限制在了某一个grid cell,但框不会。
正样本只用IOU最高的框,其他的IOU大于0.5的框都忽略,不产生损失函数。
正样本对分类和定位学习产生贡献。
IOU<0.5就是负样本,只对置信度学习产生贡献,且置信度标签为0.
多类别标注与分类:可能多个预测结果和标签都为1(即多个类别输出高概率),而不是求和为1.(互斥)。现在每一个类别都用二分类输出一个概率,0到1之间的独立的概率。
多尺度目标检测:3中不同尺度。受FPN论文的启发


semantic information:深层抽象特化语义信息
finer-grained information:浅层细粒度像素结构信息。
仍然使用K-means聚类来生成9个框


Bn Ops是计算量(十亿次的浮点运算数), BFLOP/s(每秒可进行的浮点运算量)

难例挖掘就是错题本。
yolov3在IOU阈值为0.5性能最好,但IOU阈值提高以后就不太行了,精准定位性能仍然较差。
性能指标:
 TP即:正确预测目标。
TP即:正确预测目标。
FP即:本来是个背景,但把它预测出来了。本来没有一只猫,但出现了预测一只猫的框。
FN即:框定位不错,但置信度太小。
TN即:本来是背景,也预测成背景。





没起作用的:
1、预测相对于初始anchor宽高倍数作为偏移量(类似RCNN和RPN)因为这样预测框会不受约束而乱窜,不像sigmoid函数能让预测框中心约束在某一个grid cell内,所以不稳定。
2、直接线性回归偏移量,不用sigmoid函数也不太行。
3、focal loss也不太行。
原因:focal loss解决单阶段目标检测正负样本不均衡,真正有用的负样本少的问题,相当于是某种程度的难例挖掘。而yolov3中负样本IOU阈值设置的过高(0.5)导致负样本中混入了疑似正样本label noise(就是把它当成错题)而focal loss又会给noise赋予更大权重(纠错),因此效果不好。
4、双IOU阈值Dual IOU thresholds。
原因:RetinaNet指出单阶段目标检测不缺正样本,而是缺高质量负样本。
讨论为什么mAP.5到.95不太行:
人是分不清0.3到0.5IOU有什么不一样的。人类对二维不敏感,而是对颜色、类别敏感。为什么要追求预测框和ground truth要那么完美的重合?

如果是大框的话,这个惩罚项就很小,如果是小框的话,这个惩罚项就很大。

正样本pc越接近于1,则-log(pc)越接近于0,就越好
负样本的pc越接近于0,则-log(1-pc)越接近于0,就越好
