多头自注意力机制
本文为《Attention Is All You Need》精读中的一个拓展
论文- 《Attention Is All You Need》
为了学到多重语意含义的表达,进行多头注意力机制的运算。不要被这个多头注意力给吓住,其实这里面就是用到了几个矩阵运算,先不用管怎么运算的,我们先宏观看一下这个注意力机制到底在做什么? 拿单头注意力机制举例:
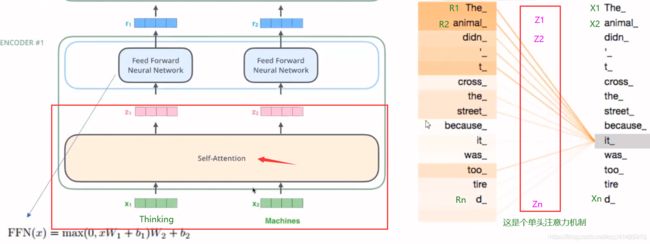
左边的红框就是我们现在讲的部分,右图就是单头注意力机制做的事情,拿句子:
The animal didn’t cross the street, because it was too tired.
我们看it这个词最后得到的R矩阵里面,就会表示出这个it到底是指的什么, 可以看到R1和R2和it最相关,就可以认为it表示的是The animal。
也就是说,每一个字经过映射之后都会对应一个R矩阵, 这个R矩阵就是表示这个字与其他字之间某个角度上的关联性信息,这叫做单头注意力机制。(具体怎么做到的,下面会说)
下面看一下多头注意力宏观上到底干了什么事情:
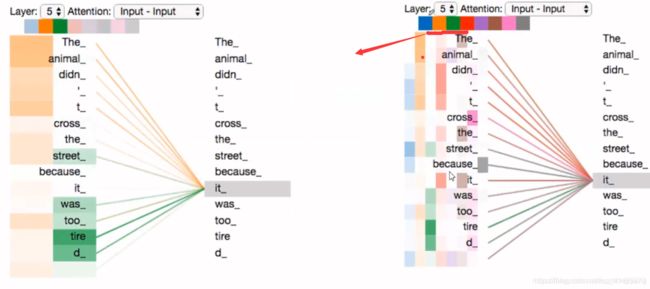
左边这个是两头的注意力机制,上面说到这个橙色的这个注意力反映了it这个词指代的信息。 而这个绿色的这个注意力,反应了it这个词的状态信息,可以看到it经过这个绿色的注意力机制后,tired这个词与it关联最大,就是说it,映射过去,会更关注tired这个词,因为这个正好是它的一个状态。 它累了。
这样是不是就能明白多头注意力的意义了啊,每个字经过多头注意力机制之后会得到一个R矩阵,这个R矩阵表示这个字与其他字在N个角度上(比如指代,状态…)的一个关联信息,这个角度就是用多个头的注意力矩阵体现的。这就是每个字多重语义的含义。
那么究竟是怎么实现的呢? 其实这个过程中就是借助了三个矩阵来完成的。下面具体看一下:
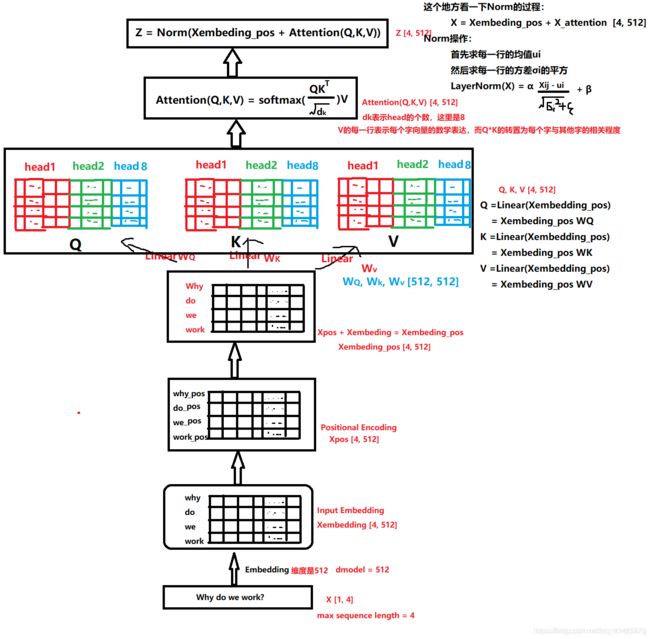
我们的目标是把我们的输入Xembedding_pos通过多头注意力机制(系列线性变换)先得到Z。然后Z通过前馈神经网络得到R。这个R矩阵表示这个字与其他字在N个角度上(比如指代,状态…)的一个关联信息。
先看看怎么得到这个Z: 在Xembedding_pos->Z的过程中到底发生了什么呢?
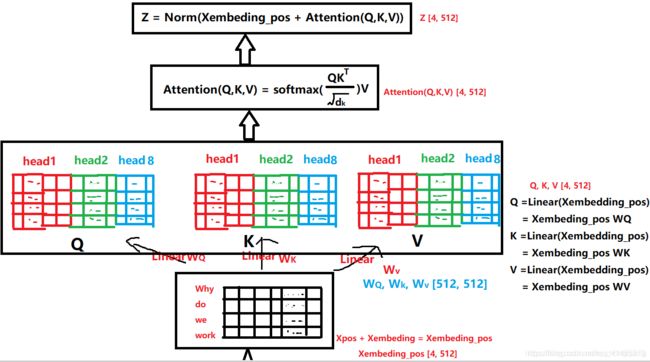
这就是整个过程的变化,首先Xembedding_pos会做三次线性变化得到Q,K,V,三个矩阵,然后里面Attention机制,把Q,K,V三个矩阵进行运算,最后把Attention矩阵和Xembedding_pos加起来就是最后的Z。
可是为什么要这么做呢? Q,K,V又分别表示什么意思呢?
我们先说第二个问题,Q,K,V这三个矩阵分别是什么意思, Q表示Query,K表示Key,V表示Value。之所以引入了这三个矩阵,是借鉴了搜索查询的思想,比如我们有一些信息是键值对(key->value)的形式存到了数据库,(5G->华为,4G->诺基亚), 比如我们输入的Query是5G, 那么去搜索的时候,会对比一下Query和Key, 把与Query最相似的那个Key对应的值返回给我们。 这里是同样的思想,我们最后想要的Attention,就是V的一个线性组合,只不过根据Q和K的相似性加了一个权重并softmax了一下而已。下面具体来看一下:
上面图中有8个head, 我们这里拿一个head来看一下做了什么事情:(请注意这里head的个数一定要能够被embedding dimension整除才可以,上面的embedding dimension是512, head个数是8,那么每一个head的维度是(4, 512/8))
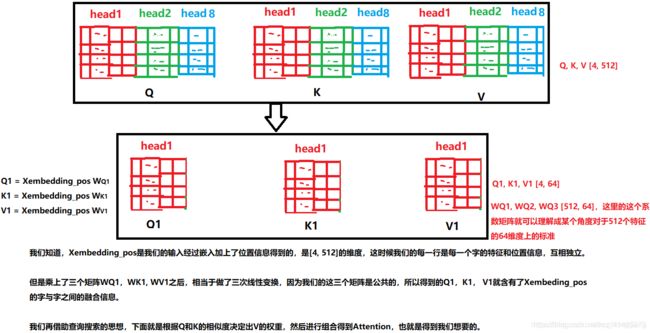
怎么得到Q1和K1的相似度呢? 我们想到了点积运算, 我们还记得点积运算的几何意义吗?两个向量越相似, 他们的点积就越大,反之就越小(因为向量a点乘向量b等与||a|| ||b| |cosθ, 越相似,θ越小,点积就会越大)。
我们看看Q1*K1的转置表达的是个什么意思:
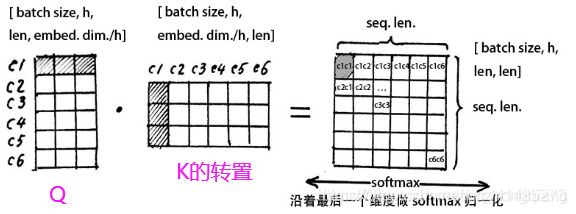
c1, c2,…c6这些就代表我们的输入的每一个字,每一行代表每一个字的特征信息, 那么Q1的c1行和K1转置的c1列做点积运算得到第一个字和其他几个字的注意力或者相关性。
这样最后的结果每一行表示的这个字和其他哪几个字比较相关, 这个矩阵就是head1角度的注意力矩阵。
但是我们有8个head头的,我们假设每一个头的Q1,K1服从标准正态的话,那么八个头堆叠的大矩阵Q和K的点积运算之后会服从均值为1, 方差为64的正态(相当于A服从N(0,1)的标准正态, 8A就服从N(0, 64)),这时候为了方向传播的时候能够获取平衡的梯度,我们有一个QK的转置然后除以根号64的操作,这时候把矩阵变成了标准正态。

然后对每一行使用softmax归一化变成某个字与其他字的注意力的概率分布(使每一个字跟其他所有字的权重的和为1)。
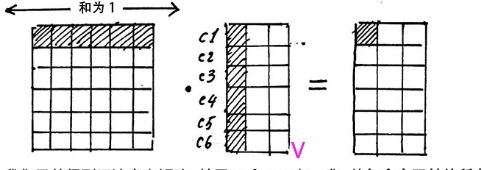
这时候,我们从注意力矩阵取出一行(和为1),然后依次点乘V的列,因为矩阵V的每一行代表着每一个字向量的数学表达,这样操作,得到的正是注意力权重进行数学表达的加权线性组合,从而使每个字向量都含有当前句子的所有字向量的信息。这样就得到了新的X_attention(这个X_attention中每一个字都含有其他字的信息)。
用这个加上之前的Xembedding_pos得到残差连接,训练的时候可以使得梯度直接走捷径反传到最初层,不易消失。
再经过一个LayerNormlization操作就可以得到Z。 LayerNormlization的作用是把神经网络中隐藏层归一化为标准正态分布,起到加快训练速度,加速收敛的作用。类似于BatchNormlization,但是与BatchNormlization不同的是前者是以行为单位(每一行减去每一行的均值然后除以每一行的标准差),后者是一个Batch为单位(每一个元素减去Batch的均值然后除以Batch的标准差)。
所以多头注意力机制细节总结起来就是下面这个图了: