从训练一个模型开始学习pytorch(1)——用Alexnet训练CIFAR10数据集
一.导入必要的库
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import torch.utils.data.dataloader as dataloader
import pdb
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
pytorch知识点1:导入工具包
常用的工具包有如下几个:
1.import torch:用于Tensor有关的计算。
Tensor:一个多维数组,是标量、向量、矩阵的高维拓展,通常一维的张量就是我们所谓的向量,二维的张量就是我们所谓的矩阵,再往后拓展多维的我们就称之为张量。那么torch工具包可以用来干什么呢?可以实现对张量的创建 、索引、连接、转置、加减乘除、切片等操作。
在这篇博客里说啦~有兴趣可以去这里看
2.import torch.nn:用于搭建神经网络
包含搭建神经网络层的模块(Modules)和一系列loss函数。如卷积、全连接FC、BN批处理、dropout、CrossEntryLoss、MSELoss等。
详情点这里
3.import torchvision:专门用来处理图像的库
这个包中常用的几个模块有下面这几个:
——torchvision.datasets:是用来进行数据加载,提供常用数据集常用数据集。MNIST、COCO、CIFAR10、Imagenet等
——torchvision.models:提供已经训练好的模型,加载之后可以直接使用。包括AlexNet、VGG、ResNet
——torchvision.transforms:图片相关处理。裁剪、尺寸缩放、归一化等
——torchvision.utils:将给定的Tensor保存成image文件。
二.下载数据集及数据格式转换
pytorch知识点2:下载数据集及格式转换
前面介绍了torchvision工具包中的torchvision.datasets,提供MNIST、COCO、CIFAR10、Imagenet等常用数据集常用数据集。
1.下载数据集
train=torchvision.datasets.数据集(路径,是否下载,测试集还是训练集)
test=torchvision.datasets.数据集()
train_set = torchvision.datasets.CIFAR10(
root="./data",
download=True,
train=True,
transform=transform
#root指定下载到哪个路径,这里是当前文件夹下的data文件夹;指定下载train训练集
)
test_set = torchvision.datasets.CIFAR10(
root="./data",
download=True,
train=False,
transform=transform
#指定下载测试集
)
2.数据格式转换
虽然torchvision提供数据集下载接口,但是下载的数据集的格式pytorch不一定支持,所以要用transform把数据集的格式转换成pytorch支持的形式,或者需要自己定义数据集格式的时候也用到transform。
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(), #概率水平翻转,默认p=0.5
transforms.RandomGrayscale(),#转灰度图
transforms.ToTensor(),#转换为Tensor 并归一化到0-1(直接除以255,若自己数据尺度右边则要修改)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))#标准化,mean,std 对数据按通道进行标准化,先减均值再除标准差
]
)
常见的数据与处理方法这里有介绍
三.设置数据接口dataloader.py
test_loader = dataloader.DataLoader(
dataset=test_set,
batch_size=100,
shuffle=True
)
关于dataloader的更多详情
四.搭建模型
这里用到torch.nn包的知识
1.搭建子模块
2.连接子模块
class AlexNet(nn.Module):
#1.搭建子模块
def __init__(self, class_num):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(192, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 4 * 4, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, class_num),
)
#2.连接子模块
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 4 * 4)
x = self.classifier(x)
return x
五.训练模型
如果需要使用GPU:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AlexNet(10)
model.to(device)
epoches = 100
lr = 0.001
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(epoches):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
output = model(images)
loss = criterion(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'
.format(epoch + 1, epoches, loss.item()))
with torch.no_grad():
correct = 0
total = 0
for (images, labels) in test_loader:
images, labels = images.to(device), labels.to(device)
output = model(images)
_, predicted = torch.max(output.data, 1)
total += labels.size(0)
#pdb.set_trace()
correct += (predicted == labels).sum().item()
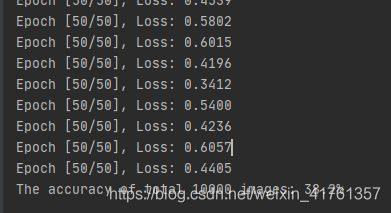
print("The accuracy of total {} images: {}%".format(total, 100 * correct / total))
结果:
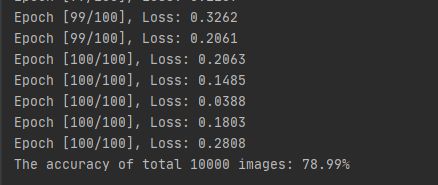
这里用的是Adam优化策略(关于优化策略的文章)
用SGD优化,大概训练了一天半,时间是Adam的两倍,结果还差……
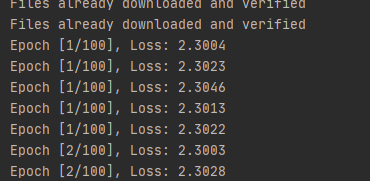

Adagrad: