精读Swin Transformer
Swin Transformer:Hiaerarchical(层级式) VIsion Transformer using Shifted Windows (MSRA研究领域的黄埔军校)
选自8.17号的更新版本
摘要
swin transformer用来做计算机视觉领域一个 通用的骨干网络,在Vit只做分类任务,下游任务比如检测与分割留给以后的人来探索时,当时大家并不能确定transformer能否把视觉领域所有的任务都做掉,那么swin transformer的动机告诉大家transformer没毛病,但是把transformer从NLP用到vision里面是有挑战的,这要来自于两个方面 ,一是尺度问题,比如说现在有一张街景的图片,里面有很多的车和行人,里面的物体都大大小小,代表同样语义的词就有很多的尺寸,但是NLP就没有这个问题,另一个问题是 图像的resolution太大了,如果以像素点为基本单位的话,这个序列长度就高不可攀了,所以说之前的工作要么以后续的特征图作为transformer的输入,要么就是把图片达成patch,减少图片的resolution,要么就是把图片化成一个一个的小窗口,在小窗口里面进行自注意力, 所有的这些方法都是为了减少序列的长度.基于此.本文作者提出了 hierarchical Transformer,通过移动窗口的方式学来的,它不仅带来了很好的效率,并且移动的操作使得相邻的窗口有了交互,所以上下层之间就有了cross-window connection 从而变相的达到了一种全局建模的能力,作者说这种层级式的好处在于它不仅非常的 灵活,可以 提供各个尺度的这个特征信息,同时因为它的自注意力是在这个小窗口之内算的,所以说它的这个计算复杂度是随着图像的大小程线性增长而不是平方及增长,因此可以在特别大的分辨率图像中预训练模型,然后因为Swin Transformer拥有了像卷积神经网络一样这种分层的结构,有了这种多尺度的特征,所以它可以很容易使用到这种下游的任务,所以它不光在ImageNet-1k 上做了实验,而且达到87.3的准确率,而且还在密集预测型的任务上也达到了很好的效果.因此基于transformer这个模型在视觉领域都是很好的前景的.针对MLP这个架构的话采用shift window 的方法也能够提升.
引言
图一:transformer想干的事情,图二作者介绍了swin transformer的贡献,也就是移动窗口
在视觉领域中卷积神经网络占据主导地位,但是transformer在NLP中应用的很好,所以作者想把transformer用到视觉领域当中,但是VIT已经把这件事给干了,swin transformer在第三段的开始就说明了他们的研究动机用于证明transformer可以用作为一个通用的骨干网络,读在所有的视觉的任务,不光是分类,在检测,分割视频上也能取得很好的效果,
 一般像写的好的论文,图一一般都画的非常好,就是说不看内容,看图片 就大概知道它要讲什么了
一般像写的好的论文,图一一般都画的非常好,就是说不看内容,看图片 就大概知道它要讲什么了
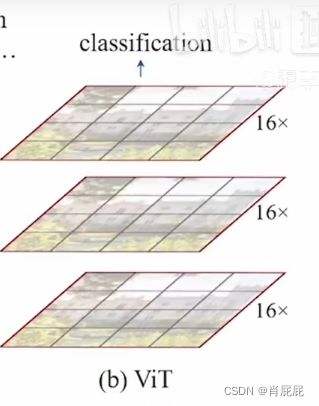 b图作者先说Vision Transformer将图片达成patch,因为Vit中patch 为16*16的,所以说16*就是16倍的下采样率,那么就是说这里的每一个patch/token它自始至终代表的尺寸都是差不多的,都是16倍的下采样率,虽然说它可以通过全局的自注意力操作达到全局的建模能力,但是他对多尺寸特征的把握就是弱一点,但是对于下游视觉任务比如检测和分割来说,多尺寸的特征是至关重要的,对于目标检测应用最广泛的一个就是说, 当你有一个分层式的卷积神经网络之后,每一个卷积层出来的特征出来的感受都是不一样的,
b图作者先说Vision Transformer将图片达成patch,因为Vit中patch 为16*16的,所以说16*就是16倍的下采样率,那么就是说这里的每一个patch/token它自始至终代表的尺寸都是差不多的,都是16倍的下采样率,虽然说它可以通过全局的自注意力操作达到全局的建模能力,但是他对多尺寸特征的把握就是弱一点,但是对于下游视觉任务比如检测和分割来说,多尺寸的特征是至关重要的,对于目标检测应用最广泛的一个就是说, 当你有一个分层式的卷积神经网络之后,每一个卷积层出来的特征出来的感受都是不一样的,

抓住物体的不同尺寸的特征,从而能够很好的处理物体不同尺寸的问题,基于这个问题,作者提出来skip connection(u-net)这个方法,意思就是说党采用一系列下采样之后,采用上采样的时候,不光从bottleneck里面拿特征,还从每次下采样之后去拿特征 ,这样就将高频率分割出来的东西拿出来了
Vit不适合密集型预测任务,因为它处理的都是单一特征和16倍下采样率的,它的注意力始终都是在最大这个窗口下进行的,始终都是在整图上进行的, 所以它的复杂度是和图像的尺寸平方倍递增的
作者在方法这一大段中主要分了两个大块,一个主要是过来一下前线过程以及pachmergin,

首先对输入的一张图片 进行patch 假设一张图片为224*224*3 patch后变成 56*56*48 其中*48是因为 是RGB3通道 又,H/4,W/4,故4*4*3=48, 接下来进行linear Embedding就是将这个向量的维度设置为我们预先设置好的值,就是这个Transformer能够接受的值,他把这个超参数设置为96,所以这个时候输入尺寸就又变成了56*56*96,然后他又会拉直变成了3136*96的序列长度,然后这个96就变成了每一个token这个向量的维度, 这个swin TransformerBlock 是基于窗口来算注意力的 ,,,patch Merging 是一个上采样的方式, 各一点采一个样

原来的1个张量 就变成了4个张量, 每个张量的大小就变成h/2,w/2 就是用空间上的维度去换了更多的通道数,通过这样的操作就将一个大的张量就变小了(卷积神经网络的池化操作),但是池化操作后 它的通道都会翻倍,比如从128变成了256,256再变成512, 这里我们在做了一个操作,紧接着 又做了一个操作就是在c 的这个维度上,它用一个1*1的卷积,将c降下来变成了一个2c,,
 窗口的自注意力机制, 原来的图片会被平均的分成一些没有重叠的窗口
窗口的自注意力机制, 原来的图片会被平均的分成一些没有重叠的窗口
 切成橘黄色的窗口,但是橘黄色的窗口并不是最小的计算单元,(最小的计算单元还是之前的那个patch),现在所有的自注意力的计算都是在这个小窗口里面完成的,序列长度永远都是49, 56/7=8; 8*8=64,也就是说在这个64个窗口里面分别去结算他们的自注意力,
切成橘黄色的窗口,但是橘黄色的窗口并不是最小的计算单元,(最小的计算单元还是之前的那个patch),现在所有的自注意力的计算都是在这个小窗口里面完成的,序列长度永远都是49, 56/7=8; 8*8=64,也就是说在这个64个窗口里面分别去结算他们的自注意力,
以多头自注意力为例子:

 比如说现在输入一张图片,这个自注意力就是说先把这个图片变成q,
比如说现在输入一张图片,这个自注意力就是说先把这个图片变成q,
k,v三个向量,(这个过程就是原来的三个向量分别乘了三个系数矩阵)然后一旦得到,q,k后他们就会做一个相乘,然后就会得到这个Attention也就是这个自注意力的这个矩阵,然后A再和v做一次加权,然后再做一个projection.

-
移动窗口自注意力
-

将四个窗口进行移位,这时我们得到了9个窗口, 但是这个九个窗口的batch不一致,当然也可在边界填充0,然后计算9个窗口的注意力,但是计算复杂度太大了.接着我们做下面的操作

将A,C直接移动下面来,左边的B移动到右边的B, 那么这个时候移位之前的窗口数为4个,那么循环移位后得到的窗口就也变成了4个,那这样窗口的数量固定了,也就是说现在计算的复杂度也固定了.但是仍然存在问题,虽然对于中间的窗口来时,它里面的元素都是紧挨着的,他们之间可以两两的去做这个自注意力机制,但是对于剩下的窗口来说,是从远远的搬过来的,按道理来讲是不可以进行自注意力的,就是他们之间也没有太大的联系, 此时,就提出了掩码,做完掩码后再将循环位移还原回去
具体的掩码方式,
经过循环位移之后得到的  以序号3为例,先把里面的拉直 就变成了
以序号3为例,先把里面的拉直 就变成了 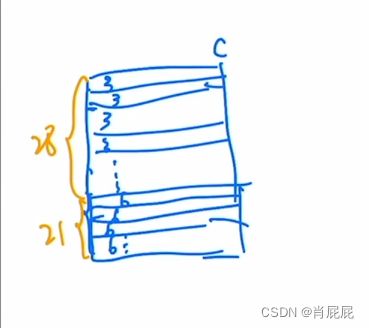 那么一共有多少个3号元素呢? 因为移动窗口的时候是移动窗口的一半,在这里窗口移动的是7,所有序号3竖着的是4,横变就是7 所有有4*7=28个3号元素
那么一共有多少个3号元素呢? 因为移动窗口的时候是移动窗口的一半,在这里窗口移动的是7,所有序号3竖着的是4,横变就是7 所有有4*7=28个3号元素
以序号3为例,先把里面的拉直 就变成了 那么一共有多少个3号元素呢? 因为移动窗口的时候是移动窗口的一半,在这里窗口移动的是7,所有序号3竖着的是4,横变就是7 所有有4*7=28个3号元素
自注意力操作

那么作者针对转置相乘后的结构,那块区域保留那块区域社区,这个时候制作出了一个掩码
 掩码1,4区域都是0;2,4区域都是-100,然后让着两个矩阵进行相加,所以当他们相加以后,2,4区域的值就会变成了一个很小的负数, 然后再经过softmax后这两块区域里面的自注意力就masked掉了,
掩码1,4区域都是0;2,4区域都是-100,然后让着两个矩阵进行相加,所以当他们相加以后,2,4区域的值就会变成了一个很小的负数, 然后再经过softmax后这两块区域里面的自注意力就masked掉了,

