【学习笔记】AlexNet
00 前言
因为上个月准备考试,所以就没写博文,这篇是上个月交给人工智能工程伦理课的作业,所以现在发出来,凑个博文数哈哈哈
01 网络结构
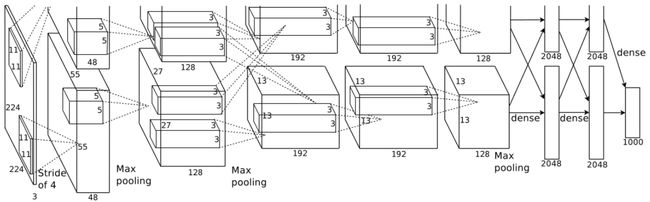
1.1第一层卷积池化层
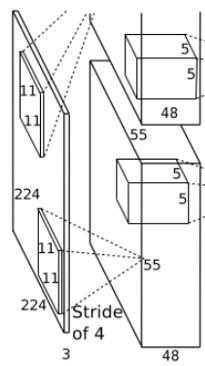
卷积:第一层输入图像为224*224*3的图像,这样需要说明一下的就是,学术界普遍认为这里的224*224*3是不合适的,后面改成了227*227*3的大小,然后通过11*11*3的卷积核进行卷积运算,卷积核的步长(Stride)为4。第一层使用了96个11*11*3的卷积核,拆分成了两部分进行,每一部分各48个卷积核,分别在一个GPU上进行运行,所以采用的是双GPU系统,之后形成了55*55*48的像素层数据。
池化:AlexNet采用重叠pooling池化层,池化类型采用最大池化,池化核为3*3,步长(Stride)为2,池化后生成尺寸为27*27*96分两组,每组48层。
LRN局部响应归一化(Local Response Normalization):将27*27*96分两组27*27*48进行局部归一化,分别在两个GPU上运行。
激活函数:ReLU。
1.2 第二层卷积池化层
卷积:输入第一层输出的27*27*96的像素层分两部分27*27*48分别在不同的GPU上进行卷积运算,使用256个5*5*48的卷积核分两组对每一组27*27*48像素层进行卷积。
池化:同样采用重叠池化,池化核3*3,步长为2,使27*27*128池化成13*13*128的像素层。
LRN局部响应归一化(Local Response Normalization):将13*13*256分两组13*13*128进行局部归一化,分别在两个GPU上运行。
激活函数:ReLU
1.3 第三层卷积池化层
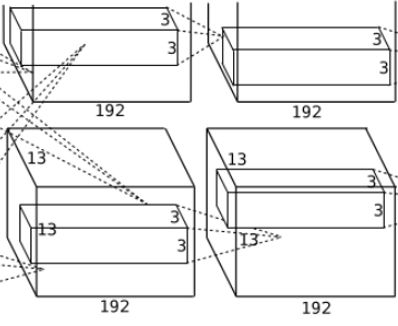
卷积:输入第二层输出的13*13*256的像素层分两部分13*13*128分别在不同的GPU上进行卷积运算,使用384个3*3*128的卷积核分两组对每一组13*13*128像素层进行卷积,之后就有了13*13*192的两组像素层。
激活函数:ReLU。
1.4 第四层卷积层
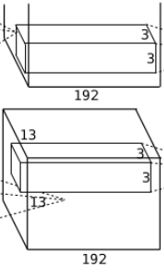
卷积:输入第三层输出的13*13*384的像素层分两部分13*13*192分别在不同的GPU上进行卷积运算,使用384个3*3*192的卷积核分两组对每一组13*13*128像素层进行卷积。
激活函数:ReLU。
1.5 第五层卷积池化层
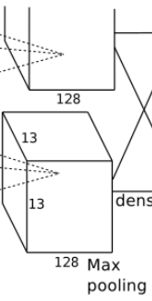
卷积:输入第四层输出的13*13*384的像素层,分两组13*13*192,使用256个3*3*192的卷积核对像素层进行卷积运算。
池化:使用3*3的池化核,stride = 2,进行池化运算,输出6*6*256的像素层。
1.6 全连接层
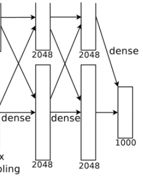
02 创新点
LRN局部响应归一化(Local Response Normalization):LRN模拟的是生物学中侧抑制的功能,侧抑制指的是被激活的神经元会抑制相邻的神经元。
对输入激活函数的数据进行标准化,提高性能。
b x , y i = a x , y i / ( k + α ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a x , y j ) 2 ) \ b_{x,y}^i=a_{x,y}^i/(k+\alpha\sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}{(a_{x,y}^j)}^2) bx,yi=ax,yi/(k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yj)2)
其中a表示在feature map中第i个卷积核(x,y)坐标经过了激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
重叠池化(Overlapping Pooling):重叠池化就是在池化操作上对部分像素进行重合,假设池化核大小为n*n,Stride = k,如果k = n,则是正常池化,如果k < n则重叠池化,重叠池化具有避免过拟合的作用
ReLU激活函数:AlexNet使用了ReLU激活函数,代替了sigmoid核tanh,ReLU的SGD收敛速度要比sigmoid和tanh快得多。
数据增强:AlexNet使用了数据增强的方法来增加数据集的数量,从而达到防止过拟合的情况的发生。
Dropout:结合预先训练好的许多不同模型,来进行预测是一种非常成功的减少测试误差的方式(Ensemble)。但因为每个模型的训练都需要花了好几天时间,因此这种做法对于大型神经网络来说太过昂贵。然而,AlexNet提出了一个非常有效的模型组合版本,它在训练中只需要花费两倍于单模型的时间。这种技术叫做Dropout,它做的就是以0.5的概率,将每个隐层神经元的输出设置为零。以这种方式“dropped out”的神经元既不参与前向传播,也不参与反向传播。所以每次输入一个样本,就相当于该神经网络就尝试了一个新的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。正因如此,网络需要被迫学习更为鲁棒的特征,这些特征在结合其他神经元的一些不同随机子集时有用。在测试时,我们将所有神经元的输出都仅仅只乘以0.5,对于获取指数级dropout网络产生的预测分布的几何平均值,这是一个合理的近似方法。前两个全连接层使用dropout。如果没有dropout,我们的网络会表现出大量的过拟合。dropout使收敛所需的迭代次数大致增加了一倍。Dropout方法和数据增强一样,都是防止过拟合的。