(五) 深度学习笔记 |LeNet-5
一、前言
LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。
卷积神经网络能够很好的利用图像的结构信息。
卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定的。
如果对卷积神经网络不了解的,可以查看我此前的博客,里面有从卷积神经网络结构的基础说起,详细地讲解每个网络层。https://blog.csdn.net/weixin_45579930/article/details/112230543
二、关于feature maps
什么叫特征图呢?其实一张图片经过一个卷积核进行卷积运算,我们可以得到一张卷积后的结果图片,而这张图片就是特征图。在CNN中,我们要训练的卷积核并不是仅仅只有一个,这些卷积核用于提取特征,卷积核个数越多,提取的特征越多,理论上来说精度也会更高,然而卷积核一堆,意味着我们要训练的参数的个数越多。在LeNet-5经典结构中,第一层卷积核选择了6个,而在AlexNet中,第一层卷积核就选择了96个,具体多少个合适,还有待学习。
回到特征图概念,CNN的每一个卷积层我们都要人为的选取合适的卷积核个数,及卷积核大小。每个卷积核与图片进行卷积,就可以得到一张特征图了,比如LeNet-5经典结构中,第一层卷积核选择了6个,我们可以得到6个特征图,这些特征图也就是下一层网络的输入了。我们也可以把输入图片看成一张特征图,作为第一层网络的输入。
三、关于LeNet-5
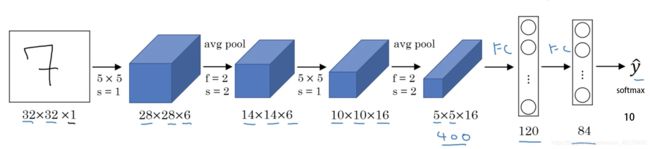
LeNet-5 结构:
- 输入层
图片大小为 32×32×1,其中 1 表示为黑白图像,只有一个 channel。 - 卷积层
filter 大小 5×5,filter 深度(个数)为 6,padding 为 0, 卷积步长 =1,输出矩阵大小为 28×28×6,其中 6 表示 filter 的个数。 - 池化层
average pooling,filter 大小 2×2(即 =2),步长 =2,no padding,输出矩阵大小为 14×14×6。 - 卷积层
filter 大小 5×5,filter 个数为 16,padding 为 0, 卷积步长 =1,输出矩阵大小为 10×10×16,其中 16 表示 filter 的个数。 - 池化层
average pooling,filter 大小 2×2(即 =2),步长 =2,no padding,输出矩阵大小为 5×5×16。注意,在该层结束,需要将 5×5×16 的矩阵flatten 成一个 400 维的向量。 - 全连接层(Fully Connected layer,FC)
neuron 数量为 120。 - 全连接层(Fully Connected layer,FC)
neuron 数量为 84。 - 全连接层,输出层
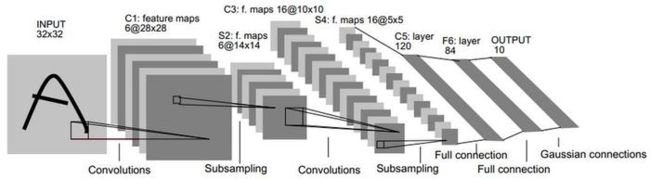
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
四、各层参数详解:
4.1INPUT层-输入层
首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。
注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
4.2.C1层-卷积层
输入图片:32*32
卷积核大小:5*5
卷积核种类:6
输出featuremap大小:28*28 (32-5+1)=28
神经元数量:28286
可训练参数:(55+1) * 6(每个滤波器55=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(55+1)62828=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5*5 的卷积核),得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
4.3.S2层-池化层(下采样层)
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:6
输出featureMap大小:14*14(28/2)
神经元数量:14146
连接数:(22+1)61414
S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 2*2核 进行池化,于是得到了S2,6个14*14的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。同时有5x14x14x6=5880个连接。
4.4.C3层-卷积层
输入:S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核种类:16
输出featureMap大小:10*10 (14-5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6*(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516
连接数:10101516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5*5. 我们知道S2 有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:
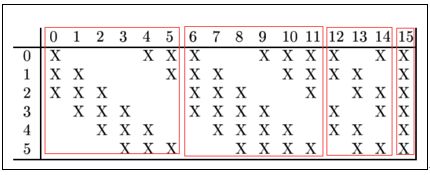
- C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为55,所以总共有6(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
- C3与S2中前3个图相连的卷积结构如下图所示:
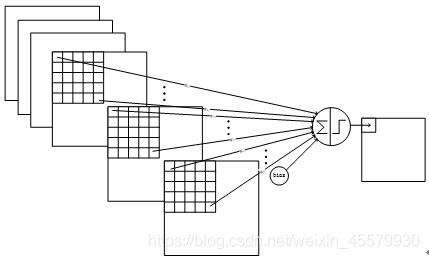
4.5.S4层-池化层(下采样层)
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:5*5(10/2)
神经元数量:5516=400
连接数:16*(2*2+1)55=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。有5x5x5x16=2000个连接。连接的方式与S2层类似。
4.6.C5层-卷积层
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类:120
输出featureMap大小:1*1(5-5+1)
可训练参数/连接:120*(1655+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
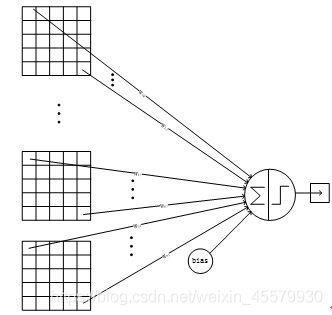
4.7.F6层-全连接层
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
可训练参数:84*(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

- F6层的连接方式如下:
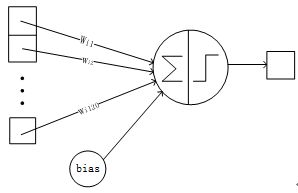
4.8.Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
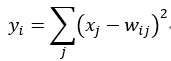
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
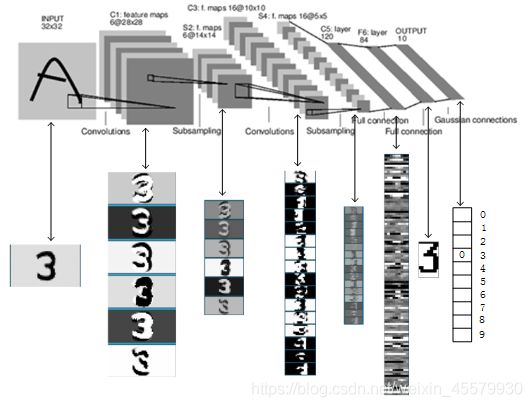
上图是LeNet-5识别数字3的过程。
五、定义神经网络
- 定义一个神经网络:
- 我们通过代码更好的理解各层参数中的详解
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32 * 5 * 5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
input1 = torch.rand([32, 3, 32, 32])
model = LeNet()
print(model)
output = model(input1)
输出:
LeNet(
(conv1): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=800, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
参考:
https://cuijiahua.com/blog/2018/01/dl_3.html