异常检测 and 开集识别(2)
文章目录
- 前言
- 一、开集识别的演变
- 二、开集识别技术分类
- 三、目前先进的开集识别算法
-
- 1、OpenMax
- 2、G-OpenMax
- 3、CROSR
- 4、MLOSR
- 总结
前言
本文是本人在学习开集识别时的一些记录,主要是综合其他博主的内容并进行了一些修改,希望大家可以有所收获~
一、开集识别的演变
作为总结,下表1列出了开放集识别和上面提到的相关任务之间的区别。

事实上,OSR已经在许多框架、假设和名称进行了研究。相关具体内容可参考Recent Advances in Open Set Recognition: A Survey,这里提供了关于开集识别的全面回顾。
二、开集识别技术分类
根据建模形式,这些模型可进一步分为四类(见表2):判别模型角度的基于传统ML (TML)的方法和基于深度神经网络(DNN)的方法;生成模型的基于实例和非实例生成方法。对于每一个类别,文章通过关注其对应的代表作品来回顾不同的方法。此外,图3给出了这些方法链接的全局图,同时也列出了几个可用的软件包链接(表3),以方便相关研究者进行后续研究。其次,文章Recent Advances in Open Set Recognition: A Survey首先从判别模型的角度对现有的OSR算法进行了综述,后面也从生成模型的角度进行了综述。


三、目前先进的开集识别算法
1、OpenMax
Softmax是深度学习分类网络中最常见的最后一层的激活函数,用于概率值的生成。这不可避免地会带来归一化问题,使其固有的封闭集特性。例如,在处理UUCs的样本时,DNNs常常做出错误的预测,甚至过于自信。所以《Towards Open Set Deep Networks》提出了openmax层来替代softmax,作为开放集深度网络的第一个解决方案。
Openmax利用来自预训练的深度神经网络的倒数第二层(也就是dense层)的激活矢量。
流程:
只计算并保留所有预测样本正确样本(预测错误(预测值和真实label不符)输出的舍弃)的特征值(特征值的长度就是类别的长度,比如最后的类别数量为3,那么这个特征就是长度为3的向量,而不是之前一层的向量)。
求出所有预测正确样本的向量,根据不同的类别(真实label)将这些向量对应分开,然后分别计算每个类别对应向量的均值作为该类别的中心(可认为类别的中心点,和聚类的中心点类似)。
然后分别计算每个类别中每个样本对应向量和其类别中心的距离,然后对这些距离进行排序,针对排序后的几个尾部极大值进行极大值理论分析,这些极大值的分布符合weibull分布,所以使用weibull分布(libmr中的fithigh方法)来拟合这些极大的距离,得到一个拟合分布的模型,这时候基本已经完成了Algrithms 1。


接下来是算法2 的Openmax的计算。当来了一个新的测试图像的时候,输入模型,先得到对应的dense向量(softmax的前一层),然后针对该向量分别针对每个类别计算与其之间的距离(共得到N个距离),然后针对上述得到的每个距离分别使用每个类别对应的拟合模型对其进行预测,最后会分别得到一个分数FitScores,这个分数就是指该测试图像特征值归属于其对应类别的概率,所以一共是有N个分类的。然后根据该图像的最终输出(此处为softmax的输出),根据该概率分数的输出进行排序,然后计算w的值(该值的计算就是根据采用tail的个数(即阿尔法的值)来计算的) f o r i = 1... α w = 1 − F i t S c o r e s ∗ ( α − i ) / α for \ i=1...α \ \ \ \ w=1−FitScores∗(α−i)/α for i=1...α w=1−FitScores∗(α−i)/α
然后将该向量分别针对每个类别计算与其之间的距离与上述得到的w进行相乘,后续再进行类似softmax的操作,最终得到两个分数,一个是openmax后的分数,一个是unknown的分数,注意这里得到的openmax的类别比softmax输出的类别多一个类别,也就是unknown的类别。
概括:该方法使用EVT从每个类的平均值建模这些激活矢量的距离,生成更新的倒数第二矢量(称为OpenMax),这个更新的矢量产生了更好的模型,用于识别未知的类测试样本。即以前的CNN中倒数第二层使用SoftMax概率描述,但是并没有产生开集识别的良好模型,为适应开放式环境,更新倒数第二层矢量。
EVT:极值理论,能够处理小概率事件,预测极端事件的概率。
使用EVT的原因:使用EVT建模技术对来自网络的重构误差分布进行建模,从而进一步提高性能。
2、G-OpenMax
该算法是将OpenMax与使用GAN生成的数据增强相结合。使用GAN从已知的类数据生成未知样本,然后将它们用于训练CNN以及已知类。这种数据增强技术被证明可以改善未知的类别识别。
GAN网络:生成式对抗网络是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型和判别模型的互相博弈学习产生相当好的输出。
3、CROSR
训练网络以进行输入数据的联合分类和重建。其增强了学习的表示,以便保存未知和已知数据的信息,以及区分已知类别的信息。用于开集识别的新型分类-重建学习(CROSR),能够在不损害已知分类准确度的情况下实现稳健的未知检测。大量实验表明,此方法在多个标准数据集中优于现有的深度开集分类器,并且对各种异常具有鲁棒性。
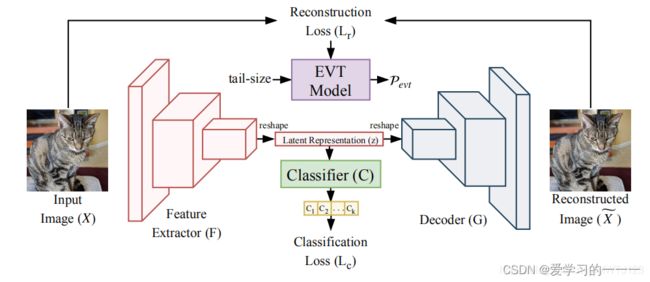
4、MLOSR
原理:其为基于CNN的深度开放式识别多任务学习,是通过将自动编码器和分类结合起来可以有效通过多任务提高open-set的表现。系统架构由四个模块组成:
- 特征提取器(或编码器)
- 解码器
- 分类器
- 极值模型(Pevt)
特征提取器(或编码器)网络由CNN架构建模,该架构将输入图像映射到潜在空间上表示。 另一个CNN和分类器模拟的解码器,由完全连接的神经网络建模,将这种潜在的代表作为输入,并分别产生重建的图像及其标记作为输出。 解码器网络和分类器网络共享特征提取器模块。 在训练模型F,G和C之后,使用EVT对重建误差进行建模。训练过程以学习参数(Θf,Θg,Θc)并使用EVT讨论识别分数分析。
特征提取器网络获取任何输入图像(X)并产生潜在表示(z)。 分类器(C)和解码器(G)使用该潜在表示来分别预测类标签和重建输入(X)。 训练这些网络以在多任务框架中执行分类和重建任务。 使用EVT对重建误差分布的尾部建模。在测试期间使用分类分数和EVT重建误差概率来执行开集识别。
总结
参考网站如下:
开集识别(open-set)算法(1)——>Openmax参考
open-set recognition(OSR)开集识别的一些思考(四)——>Openmax参考
开集识别(Open Set Recognition)——>算法参考