任务型客服系统简述
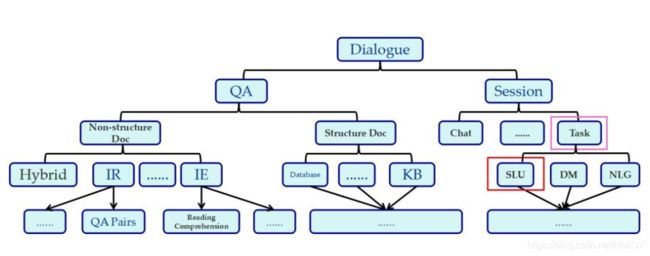
这里的分类是这样分的:首先将对话分为问答与会话,在问答中按照文档是否结构化分为无结构化文档与结构化文档。无结构化文档中包含一些如IR信息检索(如QA对,查找文档的问题),IE信息抽取(如阅读理解,查找文档中的精确片段),这一块的难点在于相似性的计算。结构化文档中包含数据库,知识图谱等,他们的输入为结构化的片段,数据库具有查询的功能,知识图谱具有查询与推理的能力,这一块的难点其实也是如何获取自然语言中的约束条件(槽位)的问题。接下来重点看下会话,会话划为为闲聊型,任务型等,传统的任务型分为语言理解模块(SLU),对话管理模块(DM)以及自然语言生成模块(NLG)等。
这是今天分享的大纲。主要包括四个部分:首先介绍对话系统的背景和整体架构;然后介绍对话系统中的两个关键部分,分别是自然语言理解(NLU)和对话管理(DM);最后再讲讲助理来也在打造对话系统中的思考和尝试。
接下来我们重点介绍自然语言理解(NLU)和对话管理(DM)这两个模块:
自然语言理解(NLU)的目标是将文本信息转换为可被机器处理的语义表示。因为同样的意思有很多种不同的表达方式,对机器而言,理解一句话里每个词的确切含义并不重要,重要的是理解这句话表达的意思。上面的例子中,三句话在字面上完全不同,但表达了类似的意思,即用户想预约上门保洁服务。
NLU challenge
NLU表示可以用意图+槽位的方式来描述。意图即这句话所表达的含义,槽位即表达这个意图所需要的具体参数,用slot和value对的方式表示。比如,「预约这周日上午的保洁阿姨」这句话的意图是「发起请求」,槽位是「服务类型=保洁,服务日期=20161127」。NLU要做的事情就是将自然语言转化成这种结构化的语义表示。
下面介绍NLU的几种方法。第一种是基于规则的方法,大致的思路是定义很多语法规则,即表达某种特定意思的具体方式,然后根据规则去解析输入的文本。上图中展示了一个订机票场景下基于规则的NLU模块。这个方法的好处是非常灵活,可以定义各种各样的规则,而且不依赖训练数据。当然缺点也很明显,就是复杂的场景下需要很多规则,而这些规则几乎无法穷举。因此,基于规则的NLU只适合在相对简单的场景,适合快速的做出一个简单可用的语义理解模块。当数据积累到一定程度,就可以使用基于统计的方法了。
NLU components task
基于统计的NLU使用数据驱动的方法来解决意图识别和实体抽取的问题。意图识别可以描述成一个分类问题,输入是文本特征,输出是它所属的意图分类。传统的机器学习模型,如SVM、Adaboost都可以用来解决该问题。实体抽取则可以描述成一个序列标注问题,输入是文本特征,输出是每个词或每个字属于实体的概率。
传统的机器学习模型,如HMM、CRF都可以用来解决该问题。如果数据量够大,也可以使用基于神经网络的方法来做意图识别和实体抽取,通常可以取得更好的效果。和基于规则的NLU相比,基于统计的方法完全靠数据驱动,数据越多效果越好,同时模型也更加健壮。缺点是需要训练数据,尤其是如果使用深度学习,需要大量的数据。在实践中,这两种方法通常结合起来使用:1)没有数据的时候先基于规则,有数据了逐渐转为统计模型;2)基于统计的方法覆盖绝大多数场景,在一些极端的场景下用基于规则的方法来保证效果。
以上是NLU服务的例子。输入是「11月28号下午3点在公司开会」,返回的结果中能正确的将意图识别为创建日程,而对应实体,如日期、时间、地点都能被准确的抽取出来。
下面来介绍对话系统中另一个重要的模块:对话管理(DM)。DM是对话系统的大脑,它主要干两件事情:1)维护和更新对话的状态。对话状态是一种机器能够处理的数据表征,包含所有可能会影响到接下来决策的信息,如NLU模块的输出、用户的特征等;2)基于当前的对话状态,选择接下来合适的动作。举一个具体的例子,用户说「帮我叫一辆车回家」,此时对话状态包括NLU模块的输出、用户的位置、历史行为等特征。在这个状态下,系统接下来的动作可能有几种:1)向用户询问起点,如「请问从哪里出发」;2)向用户确认起点,如「请问从公司出发吗」;3)直接为用户叫车,「马上为你叫车从公司回家」。
常见的DM也有几种。第一种是基于有限状态机(FSM),显示的定义出对话系统应有的状态。DM每次有新的输入时,对话状态都根据输入进行跳转。跳转到下一个状态后,都会有对应的动作被执行。上图中展示了一个控制物体前后左右移动或停止的对话系统中的基于FSM的DM,大家可以清晰的看到各中状态的定义和状态间的跳转逻辑。基于FSM的DM,优点是简单易用,缺点是状态的定义以及每个状态下对应的动作都要靠人工设计,因此不适合复杂的场景。
另一种DM采用基于统计的方法。简单来说,它将对话表示成一个部分可见的马尔可夫决策过程。所谓部分可见,是因为DM的输入是存在不确定性的,例如NLU的结果可能是错误的。因此,对话状态不再是特定的马尔可夫链中特定的状态,而是针对所有状态的概率分布。在每个状态下,系统执行某个动作都会有对应的回报(reward)。基于此,在每个对话状态下,选择下一步动作的策略即为选择期望回报最大的那个动作。这个方法有以下几个优点:1)只需定义马尔可夫决策过程中的状态和动作,状态间的转移关系可以通过学习得到;2)使用强化学习可以在线学习出最优的动作选择策略。当然,这个方法也存在缺点,即仍然需要人工定义状态,因此在不同的领域下该方法的通用性不强。
最后一种DM方法是基于神经网络的。它的基本思路是直接使用神经网络去学习动作选择的策略,即将NLU的输出等其他特征都作为神经网络的输入,将动作选择作为神经网络的输出。这样做的好处是,对话状态直接被神经网络的隐向量所表征,不再需要人工去显式的定义对话状态。当然这种方法的问题时需要大量的数据去训练神经网络,其实际的效果也还有待大规模应用的验证。助理来也的对话系统中有尝试用该方法,但更多的还是传统机器学习方法和基于深度学习的方法结合。
刚刚介绍了对话系统中的两个重要模块:自然语言理解(NLU)和对话管理(DM)。实践中搭建和使用对话系统时,存在以下几个挑战:1)用户对错误的容忍度很低。因为自然语言的表达方式非常灵活多变,目前纯自动的对话系统往往达不到用户的预期,比如Siri在很多时候还是不能很好地理解用户说的话;2)有些场景下,如果只使用语音或者文字的对话系统,交互效率不一定是最高的;3)基于对话的人机交互目前还不是一种主流的交互方式,大多数用户还不习惯。下面我想针对这三点挑战,讲讲来也在搭建和使用对话系统时的一些思路和尝试。
首先,为了提升对话系统的可靠性,我们使用AI+HI的方法,此处HI表示Human Intelligence,即真人智能。AI+HI表示机器助理和真人助理结合起来,为用户提供优质的体验。为什么要这么做呢?因为当真人能够和机器配合时,能产生一个正反馈:真人纠正机器的错误 -> 更好的用户体验 -> 更多的活跃用户 -> 获取更高质量的数据 -> 训练更好地模型 -> 机器更好地辅助真人。
HI和AI如何无缝的配合呢?我们通过群聊将用户、AI和HI放在一个群里。由AI根据置信度来判断,什么情况下需要将HI加入群内,将什么样的HI加入群内,以及什么时候HI来干预。AI和HI的配合分为三种:1)AI置信度较高时,无需HI干预,对话系统完全由AI来执行动作;2)AI置信度不高时,AI生成候选动作辅助HI来动作;3)AI不确定性很高时,完全由HI接管来执行动作。
在基于AI+HI的对话系统中,HI扮演三种角色:1)为AI提供反馈,如NLU出现错误时,HI可以纠正,然后AI在纠正后的对话状态下继续工作;2)在AI的辅助下执行动作,比如AI生成候选动作但不执行,由HI进行判断最终来执行;3)产生标注数据使AI不断进化,例如HI每一次纠错、执行动作都是一个标注的样本,可以用于训练AI。
刚刚提到第二个挑战是仅用语音和文字,有时候交互效率不够高。例如,用户通过自然语言叫车,然后想知道司机的实时位置,我们如果通过自然语言去描述司机位置「司机在XXX路距离你YY米」,这个体验会很差。我们解决这个问题的方案是使用多模态交互,即在语音和文字的基础上增加更多的交互形式,如图形化的交互界面。上面的例子展示了用户通过自然语言交互叫车、查看司机位置、取消用车的全过程。很显然,通过一个地图来展示司机位置比使用自然语言去描述司机位置更精确和高效。我们将文本消息和webapp结合起来,用户既可以使用对话式的交互,也可以使用图形式的交互。
刚刚提到第三个挑战是对话式的交互目前还不是主流,用户并不适应。为了让用户更接受对话式的交互,我们可以将对话系统和推荐系统结合起来,这样对话系统不仅仅是被动的回复用户,还可以基于情景向用户进行推荐,主动和用户进行沟通。上面的图片展示了,助理来也通过分析用户的习惯和喜好,在合适的场景下向用户主动推荐打车、咖啡等服务。这种情况下,用户往往不需要再进输入任何东西,即可得到需求的满足。同时,因为用户收到的推荐是基于场景的,是个性化的,用户不会觉得被打扰,转化率也不错。
Q&A
Q1:目前,人工智能聊天机器人能在多大程度上代替企业客服?
A1:聊天机器人在基于特定知识库的客服场景下,已经能取得不错的效果。比如淘宝和京东上的客服机器人,已经能回答很多问题。当然,前提是语料足够多,质量足够高。
Q2:如何快速构建简单场景的chatbot?
A2:首先需要一个懂AI的产品经理明确的定义出你的对话场景,包括意图、实体、动作等。其次想办法收集到一批对话数据,进行标注,越多越好。最后可以使用现有的NLU服务搭建一个简单的chatbot。