Hadoop综合项目——二手房统计分析(MapReduce篇)
Hadoop综合项目——二手房统计分析(MapReduce篇)
文章目录
- Hadoop综合项目——二手房统计分析(MapReduce篇)
-
- 0、 写在前面
- 1、MapReduce统计分析
-
- 1.1 统计四大一线城市房价的最值
- 1.2 按照城市分区统计二手房数量
- 1.3 根据二手房信息发布时间排序统计
- 1.4 统计二手房四大一线城市总价Top5
- 1.5 基于二手房总价实现自定义分区全排序
- 1.6 基于建造年份和房子总价的二次排序
- 1.7 自定义类统计二手房地理位置对应数量
- 1.8 统计二手房标签的各类比例
- 2、数据及源代码
- 3、总结

0、 写在前面
- Windows版本:
Windows10 - Linux版本:
Ubuntu Kylin 16.04 - JDK版本:
Java8 - Hadoop版本:
Hadoop-2.7.1 - Hive版本:
Hive1.2.2 - IDE:
IDEA 2020.2.3 - IDE:
Pycharm 2021.1.3 - IDE:
Eclipse3.8
1、MapReduce统计分析
通过MapReduce对最值、排序、TopN、自定义分区排序、二次排序、自定义类、占比等8个方面的统计分析
1.1 统计四大一线城市房价的最值
- 分析目的:
二手房房价的最值是体现一个城市经济的重要因素,也是顾客购买的衡量因素之一。
- 代码:
Driver端:
public class MaxMinTotalPriceByCityDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "MaxMinTotalPriceByCity");
job.setJarByClass(MaxMinTotalPriceByCityDriver.class);
job.setMapperClass(MaxMinTotalPriceByCityMapper.class);
job.setReducerClass(MaxMinTotalPriceByCityReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("datas/tb_house.txt"));
FileOutputFormat.setOutputPath(job, new Path("MapReduce/out/MaxMinTotalPriceByCity"));
job.waitForCompletion(true);
}
}
- Mapper端:
public class MaxMinTotalPriceByCityMapper extends Mapper {
private Text outk = new Text();
private IntWritable outv = new IntWritable();
@Override
protected void map(Object key, Text value, Context out) throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split("\t");
outk.set(data[1]); // city
outv.set(Integer.parseInt(data[6])); // total
out.write(outk, outv);
}
}
Reducer端:
public class MaxMinTotalPriceByCityReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
List totalList = new ArrayList();
Iterator iterator = values.iterator();
while (iterator.hasNext()) {
totalList.add(iterator.next().get());
}
Collections.sort(totalList);
int max = totalList.get(totalList.size() - 1);
int min = totalList.get(0);
Text outv = new Text();
outv.set("房子总价最大、小值分别为:" + String.valueOf(max) + "万元," + String.valueOf(min) + "万元");
context.write(key, outv);
}
}
- 运行情况:
-
结果:

1.2 按照城市分区统计二手房数量
- 分析目的:
二手房的数量是了解房子基本情况的维度之一,数量的多少在一定程度上体现了房子的受欢迎度。
- 代码:

Driver端:
public class HouseCntByCityDriver {
public static void main(String[] args) throws Exception {
args = new String[] { "/input/datas/tb_house.txt", "/output/HouseCntByCity" };
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://node01:9000");
Job job = Job.getInstance(conf, "HouseCntByCity");
job.setJarByClass(HouseCntByCityDriver.class);
job.setMapperClass(HouseCntByCityMapper.class);
job.setReducerClass(HouseCntByCityReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(CityPartitioner.class);
job.setNumReduceTasks(4);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Mapper端:
public class HouseCntByCityMapper extends Mapper {
private Text outk = new Text();
private IntWritable outv = new IntWritable(1);
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split("\t");
outk.set(new Text(data[1]));
context.write(outk, outv);
}
}
Reducer端:
public class HouseCntByCityReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) sum += val.get();
context.write(key, new IntWritable(sum));
}
}
- 运行情况:
- 结果:

1.3 根据二手房信息发布时间排序统计
- 分析目的:
二手房的信息发布时间是了解房子基本情况的维度之一,在一定程度上,顾客倾向于最新的房源信息。
- 代码:
Driver端:
public class AcessHousePubTimeSortDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration()
Job job = Job.getInstance(conf, "AcessHousePubTimeSort");
job.setJarByClass(AcessHousePubTimeSortDriver.class);
job.setMapperClass(AcessHousePubTimeSortMapper.class);
job.setReducerClass(AcessHousePubTimeSortReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("datas/tb_house.txt"));
FileOutputFormat.setOutputPath(job, new Path("MapReduce/out/AcessHousePubTimeSort"));
job.waitForCompletion(true);
}
}
Mapper端:
public class AcessHousePubTimeSortMapper extends Mapper {
private Text outk = new Text();
private IntWritable outv = new IntWritable(1);
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String lines = value.toString();
String data[] = lines.split("\t");
String crawler_time = data[9], followInfo = data[4];
String ct = crawler_time.substring(0, 10);
int idx1 = followInfo.indexOf("|"), idx2 = followInfo.indexOf("发");
String timeStr = followInfo.substring(idx1 + 1, idx2);
String pubDate = "";
try {
pubDate = getPubDate(ct, timeStr);
} catch (ParseException e) {
e.printStackTrace();
}
outk.set(new Text(pubDate));
context.write(outk, outv);
}
public String getPubDate(String ct, String timeStr) throws ParseException{
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date getTime = sdf.parse(ct);
String getDate = sdf.format(getTime);
Calendar calendar = Calendar.getInstance();
calendar.setTime(getTime);
if (timeStr.equals("今天")) {
calendar.add(Calendar.DAY_OF_WEEK,-0);
} else if (timeStr.contains("天")) {
int i = 0;
while (Character.isDigit(timeStr.charAt(i))) i++;
int size = Integer.parseInt(timeStr.substring(0, i));
calendar.add(Calendar.DAY_OF_WEEK, -size);
} else {
int i = 0;
while (Character.isDigit(timeStr.charAt(i))) i++;
int size = Integer.parseInt(timeStr.substring(0, i));
calendar.add(Calendar.MONTH, -size);
}
Date pubTime = calendar.getTime();
String pubDate = sdf.format(pubTime);
return pubDate;
}
}
Reducer端:
public class AcessHousePubTimeSortReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) sum += val.get();
context.write(key, new IntWritable(sum));
}
}
- 运行情况:
- 结果:
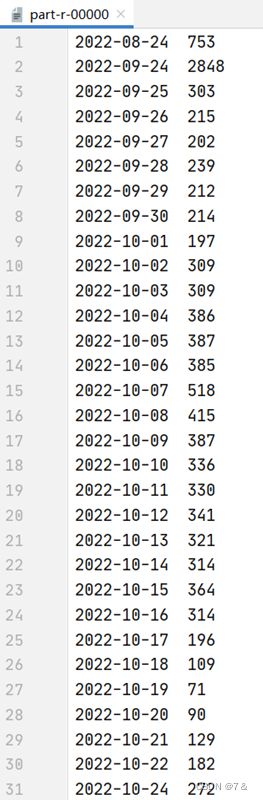
1.4 统计二手房四大一线城市总价Top5
- 分析目的:
TopN是MapReduce分析最常见且必不可少的一个例子。
- 代码:
Driver端:
public class TotalPriceTop5ByCityDriver {
public static void main(String[] args) throws Exception {
args = new String[] { "datas/tb_house.txt", "MapReduce/out/TotalPriceTop5ByCity" };
Configuration conf = new Configuration();
if (args.length != 2) {
System.err.println("Usage: TotalPriceTop5ByCity ");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(TotalPriceTop5ByCityDriver.class);
job.setMapperClass(TotalPriceTop5ByCityMapper.class);
job.setReducerClass(TotalPriceTop5ByCityReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Mapper端:
public class TotalPriceTop5ByCityMapper extends Mapper {
private int cnt = 1;
private Text outk = new Text();
private IntWritable outv = new IntWritable();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split("\t");
String city = data[1], totalPrice = data[6];
outk.set(data[1]);
outv.set(Integer.parseInt(data[6]));
context.write(outk, outv);
}
}
Reducer端:
public class TotalPriceTop5ByCityReducer extends Reducer {
private Text outv = new Text();
private int len = 0;
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
List totalPriceList = new ArrayList();
Iterator iterator = values.iterator();
while (iterator.hasNext()) {
totalPriceList.add(iterator.next().get());
}
Collections.sort(totalPriceList);
int size = totalPriceList.size();
String top5Str = "二手房总价Top5:";
for (int i = 1; i <= 5; i++) {
if (i == 5) {
top5Str += totalPriceList.get(size - i) + "万元";
} else {
top5Str += totalPriceList.get(size - i) + "万元, ";
}
}
outv.set(String.valueOf(top5Str));
context.write(key, outv);
}
}
- 运行情况:
- 结果:

1.5 基于二手房总价实现自定义分区全排序
- 分析目的:
自定义分区全排序可以实现不同于以往的排序方式,展示效果与默认全排序可以体现出一定的差别。
- 代码:
public class TotalOrderingPartition extends Configured implements Tool {
static class SimpleMapper extends Mapper {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
IntWritable intWritable = new IntWritable(Integer.parseInt(key.toString()));
context.write((Text) key, intWritable);
}
}
static class SimpleReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for (IntWritable value : values) {
context.write(value, NullWritable.get());
}
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, "Total Order Sorting");
job.setJarByClass(TotalOrderingPartition.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setNumReduceTasks(3);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path(args[2]));
InputSampler.Sampler sampler = new InputSampler.SplitSampler(5000, 10);
InputSampler.writePartitionFile(job, sampler);
job.setPartitionerClass(TotalOrderPartitioner.class);
job.setMapperClass(SimpleMapper.class);
job.setReducerClass(SimpleReducer.class);
job.setJobName("TotalOrderingPartition");
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
args = new String[] { "datas/tb_house.txt", "MapReduce/out/TotalOrderingPartition/outPartition1", "MapReduce/out/TotalOrderingPartition/outPartition2" };
int exitCode = ToolRunner.run(new TotalOrderingPartition(), args);
System.exit(exitCode);
}
}
- 运行情况:
- 结果:

…

…

…

1.6 基于建造年份和房子总价的二次排序
- 分析目的:
某些时候按照一个字段的排序方式并不能让我们满意,二次排则是解决这个问题的一个方法。
- 代码:
Driver端:

Mapper端:
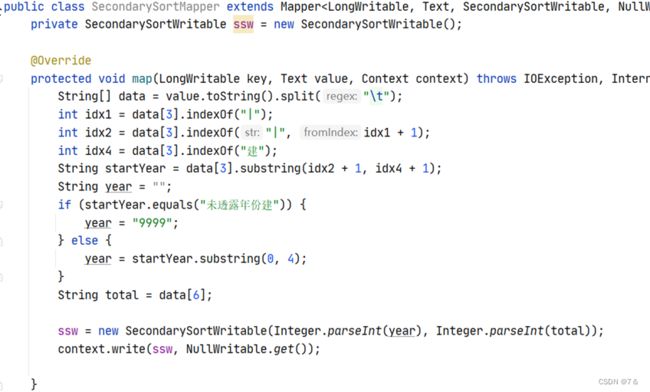
Reducer端:

- 运行情况:
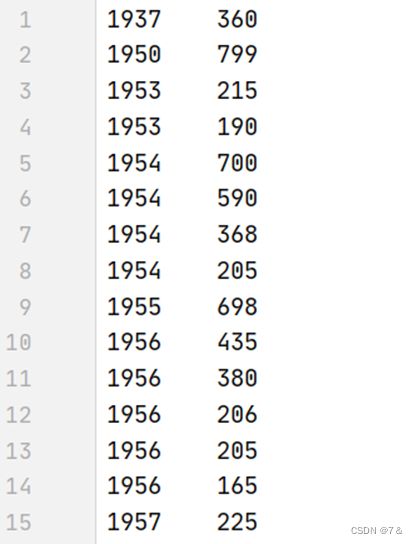
- 结果:
1.7 自定义类统计二手房地理位置对应数量
- 分析目的:
某些字段通过MapReduce不可以直接统计得到,这时采用自定义类的方式便可以做到。
- 代码:
自定义类:
public class HouseCntByPositionTopListBean implements Writable {
private Text info;
private IntWritable cnt;
public Text getInfo() {
return info;
}
public void setInfo(Text info) {
this.info = info;
}
public IntWritable getCnt() {
return cnt;
}
public void setCnt(IntWritable cnt) {
this.cnt = cnt;
}
@Override
public void readFields(DataInput in) throws IOException {
this.cnt = new IntWritable(in.readInt());
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(cnt.get());
}
@Override
public String toString() {
String infoStr = info.toString();
int idx = infoStr.indexOf("-");
String city = infoStr.substring(0, idx);
String position = infoStr.substring(idx + 1);
return city + "#" + "[" + position + "]" + "#" + cnt;
}
}
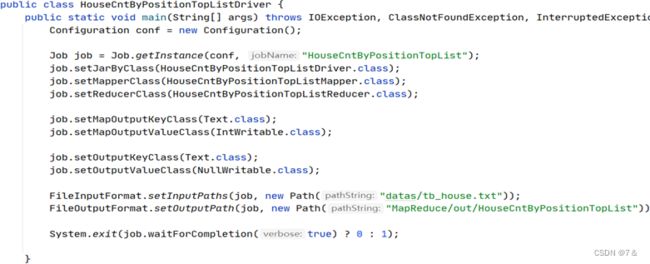
Driver端:
Mapper端:

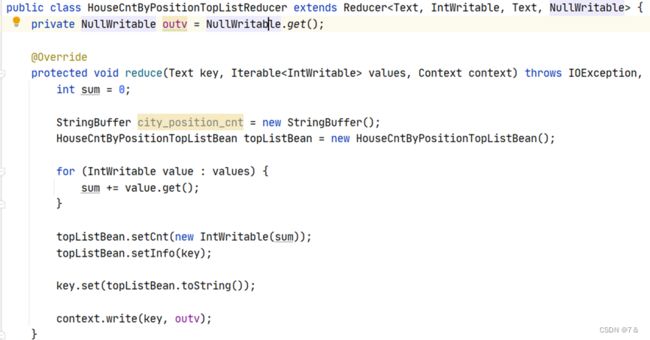
Reducer端:
- 运行情况:
- 结果:
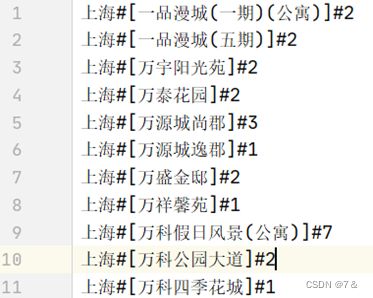
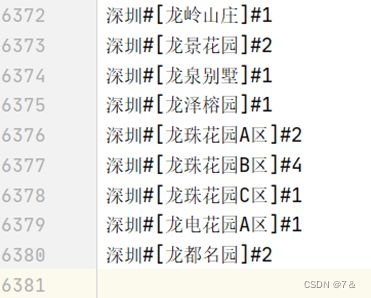
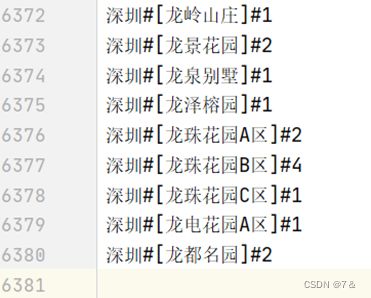
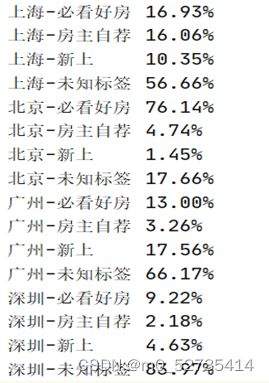
1.8 统计二手房标签的各类比例
- 分析目的:
占比分析同样是MapReduce统计分析的一大常用方式。
- 代码:
Driver端:
public class TagRatioByCityDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[] {"datas/tb_house.txt", "MapReduce/out/TagRatioByCity" };
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TagRatioByCityDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(TagRatioByCityMapper.class);
job.setReducerClass(TagRatioByCityReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Mapper端:
public class TagRatioByCityMapper extends Mapper {
private Text outk = new Text();
private IntWritable outv = new IntWritable(1);
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split("\t");
String city = data[1], tag = data[8];
if ("".equals(tag)) tag = "未知标签";
outk.set(city + "-" + tag);
context.write(outk, outv);
}
}
Reducer端:
public class TagRatioByCityReducer extends Reducer {
private Text outv = new Text();
private int sum = 0;
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
DecimalFormat df = new DecimalFormat("0.00");
int cnt = 0;
for (IntWritable value : values) {
cnt += value.get();
}
String s = key.toString();
String format = "";
if (s.contains("上海")) {
sum = 2995;
format = df.format((double) cnt / sum * 100) + "%";
} else if (s.contains("北京")) {
sum = 2972;
format = df.format((double) cnt / sum * 100) + "%";
} else if (s.contains("广州")) {
sum = 2699;
format = df.format((double) cnt / sum * 100) + "%";
} else {
sum = 2982;
format = df.format((double) cnt / sum * 100) + "%";
}
outv.set(format);
context.write(key, outv);
}
}
- 运行情况:
- 结果:
tp
2、数据及源代码
-
Github
-
Gitee
3、总结
MapReduce统计分析过程需要比较细心,「根据二手房信息发布时间排序统计」这个涉及到Java中日期类SimpleDateFormat和Date的使用,需要慢慢调试得出结果;统计最值和占比的难度并不高,主要在于统计要计算的类别的数量和总数量,最后二者相处即可;二次排序和自定义类难度较高,但一步一步来还是可以实现的。
结束!