做图的人是如何看待GNN的(一):feature 提取
目录
一、概述
二、node-level feature
1、degree
2、节点重要程度
3、结构性feature
三、Link-level feature
1、基于distance
2、基于局部邻居特征
3、基于全局邻居特征
四、graph-level feature
1、基于GraphLet
2、基于WL(着色法)
一、概述
如果说神经网络是把定向输入经过黑盒变换,转化为定向输出,例如CNN是把图像转化为标签(物体识别与检测)、RNN把提取好的文本转化为标签/概率(NER/分类),那图神经网络就是把图转为标签。
图卷积神经网络的输出,依照组成图的元素,可以分为:node-level、link-level、graph-level。node-level的任务,主要对节点进行分类,例如,找节点的label。link-level的任务是对边进行预测,例如,删去静态图的一些边,而后对删除的边进行预测;或者,预测根据时间变化的动态图的边的出现。graph-level的任务,一般是对整个图的性质进行预测。
但区别于CNN和RNN的输入,图这种结构非常复杂。CNN的本质是要对grid进行操作,这个grid可以看成一个二维矩阵,这种欧氏空间数据的卷积核也好找,直接用一个m*n的矩阵平移就足够。RNN是要对序列化的一个一维数据,每个点可以“看到”前后的部分数据,它的卷积也就只有【前】和【后】两个方向。图的每个点,其度是高度不确定的,也就不满足欧氏空间数据,更无法像RNN一样只有有限的几个方向。因此,对图进行卷积,需要转换的东西很多。
此外,参照神经网络,图神经网络的输入的特征需要经过提取。本文,将主要阐述各种的特征提取。
二、node-level feature
1、degree
度是衡量一个节点的最基础信息。如果用度作为提取的feature,就会面临以下问题:
如果一个图里,两个点的度相同,那么如何区分这两个节点呢?
2、节点重要程度
节点重要程度可以有以下3个指标判断:
Eigenvector centrality:特征向量中心性。该中心线的假设前提是,每个点的重要程度由邻居节点的重要性决定。例如PageRank。每个centrality的参照见下公式。
考虑到计算情况,整个公式见下面。其中A是邻接矩阵,c是特征向量,lamda是特征值。
Bewteenness centrality:找sssp上的重合点。例如,下图中A和B和E的centrality都是0,而C和D都是3。betweenness越大,越重要。
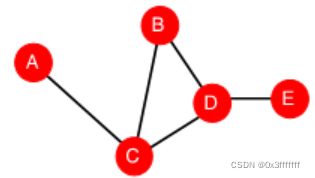
Closeness centrality:找该点为起点的sssp的和的倒数,越大越重要。例如上图中A点的centrality = 1/(2+1+2+3) = 1/8。个人认为,Closeness在较大的图例一定要取对数。
3、结构性feature
Clustering coefficient: 给定点u,衡量u点的周围的点的紧密程度。具体计算公式见下。该指标可以看作是计算点u附近有多少个三角形。分子的edge表示,u点的邻居里N(u),它们有多少共同邻居。
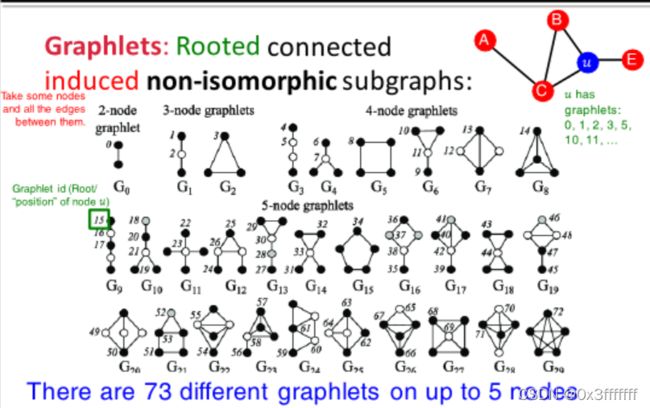
Graphlets Degree Vector:先介绍Graphlet。Graphlet是指一个图集合,该集合内部是一组互不同构、内部对称、但点数目相同的图的集合。 上面的标号是为了确定图上的点。例如G1的点是1和2,1与剩下的黑色点是同构的。
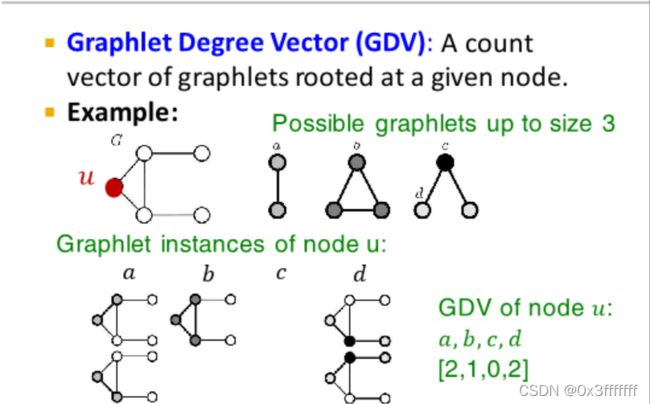
对于下图的u点,size<3的graphlet里,u相连的共有三种结构。a结构有2个,b结构有1个,c0,d2。因此gdv的向量表示为[2,1,0,2]T
三、Link-level feature
1、基于distance
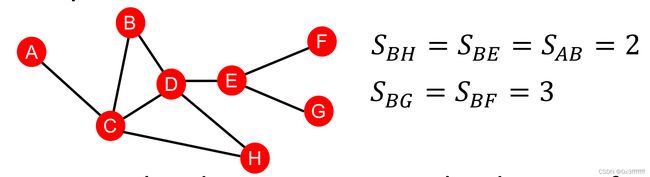
基于distance的特征主要是路径长度,可以理解为sssp。但sssp对相同大小的最短路径,无法描述一些顶点对的紧密情况。例如,BH比AB更紧密。
2、基于局部邻居特征
由于sssp无法描述紧密程度,因此用以下参数描述局部邻居特征。如果两个点比较紧密,那么下面两个特征一定相对较大。
如果没有相邻,那么这两个点的紧密程度应当为0。
Jaccard:
类似Jaccard的是参数overlap,这是在计算cluster时常用的参数。区别是,overlap去掉了u和v两点,即:
Adamic-Adar index:
例如:A(A,B)= 1/log(3)
3、基于全局邻居特征
基于局部的邻居特征有一个限制,那就是,如果两点直接不是直接相连时,无法估量他们的相似程度。因此,每次假定节点都可以跳跃,学习全局的邻居特征katz。katz指的是,两点之间的所有长度的walk值。要学习katz,先要了解公式。
如上面公式所示。其实,也就是矩阵乘法。具体代表的含义是,从u点到v点,长度为k的walk有几条。
v1到v2的kaze中心度为:,是对P^k进行数列求和,该数列里越长的path影响越小。
该公式等价于
四、graph-level feature
像前面的edge-level和node-level的feature一样, graph-level的feature用于提取图级别的feature。
在介绍graph-level feature时,需要先引入Kernel的概念。一般,graph-level的问题是分类问题,对整个图的性质进行预测;而graph-level的解决办法是通过引入kernel。在该情况下,相似性K与特征的关系为:
接下来给出几个的表示方法。
最简单的表示方法是,用Bag-of-Word表示不同的图。见下图。显然这种会有一个问题,那就是下面两个图将表示为相同的feature。
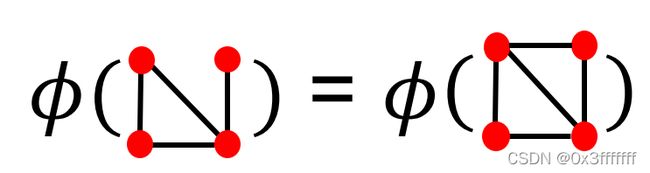
例如,用节点度作为feature,则能区分这两个图。
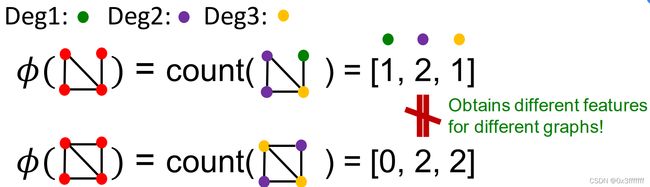
1、基于GraphLet
在前面已经介绍了GVD,基于GraphLet的方法是,在某图里做graphlet集合的子图匹配。用不同的graphlet的数目大小,区分不同的图。
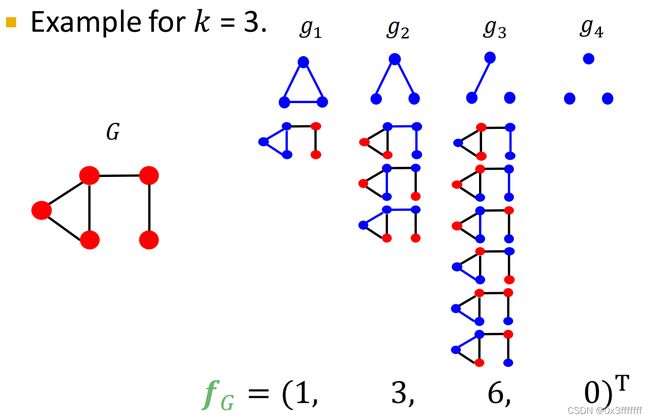
考虑到如果G和G1的大小(指点的数目)有所不同 ,那么其对应的graphlet大小可能差异过大。用取log显然是不合适的处理方式。这里采用归一化的方式进行处理。
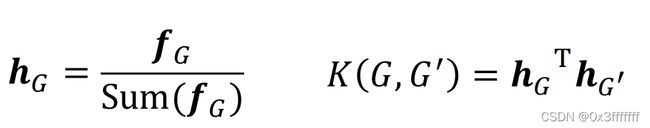
该问题最大的缺点是,子图同构是个NP-hard的问题。
2、基于WL(着色法)
着色法参照以下步骤:
(a)图里的每个节点着相同颜色0。
(b)每个节点将自己的颜色传递给邻居并记录,并定义一个HashSet记录该点和邻居的颜色。
(c)计算k次b,得到
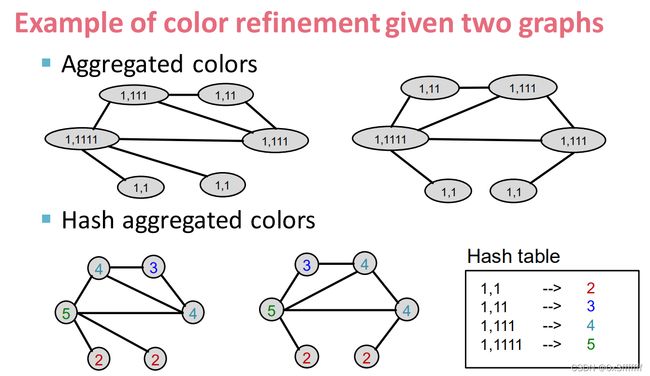
算法复杂度在O(n)级别,完全可以接受。
cite:
【斯坦福 CS224W】图机器学习( 中英字幕 | 2021秋) Machine Learning with Graphs by Jure Leskovec_哔哩哔哩_bilibili