在 Netflix 评论中做情感分析的深度学习模型

文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
原标题 | Sentiment Analysis with Deep Learning of Netflix Reviews
作者 | Artem Oppermann
译者 | ybNero(电子科技大学)、Devin_ABCDEF(汕头大学)、夕阳红老年万花(数据分析师)

在这篇文章中,我将介绍情感分析的主题和怎样实现一个可以识别和分类Netflix评论中人的感情的深度学习模型。
企业最重要的目的之一就是与客户群保持联系。这些公司必须清楚地了解客户对新老产品、最近的举措以及客户服务的看法。
情感分析是完成上述任务的方法之一
情感分析是自然语言处理(NLP)中的一个领域,它建立模型,试图识别和分类语言表达中的属性 e.g.:
1. 极性:如果发言者表达了积极或者消极的意见
2. 主题:正在被讨论的事情
3. 意见持有者:表达这个观点的人或者团体
在我们每天产生2.5万亿字节数据的世界里,情感分析已经成为理解这些数据的关键工具。这使得公司能够获得关键的洞察力并自动化所有类型的流程。
情感分析可以使得无结构的信息,比如民众关于产品、服务、品牌、政治和其他话题上的意见,自动转变为结构化的数据。这些数据对如市场分析、公共关系、产品意见、净推荐值、产品反馈和顾客服务等商业应用非常有用。
接下来,我将向你们展示如何使用深度学习模型对 Netflix 评论进行正向和负向的分类。这个模型会把全部评论作为输入(每一个单词),并且提供一个百分比的评分来检测某个评论是在表达正向或负向的情绪。
我使用的数据集包含了大约5000条负向和5000条正向的评论。这里有5个数据集中的样本,这些样本在文末做模型分类。

本文所使用的深度模型+全部所需的代码都能在我的GitHub repo中找到。
下面先开始理论部分。
01
循环神经网络
循环神经网络(RNNs)是很受欢迎的模型,并且在很多NLP任务上已经取得了很好的表现。
循环神经网络使用了序列信息,如文本。在传统的前馈神经网络中,我们假设所有的输入是彼此独立的。但是对很多任务而言,这是很不好的想法。举个例子,一句话有完整的语法结构和顺序,句子中每个词都依赖于前一个词。如果你想你的神经网络能够学习到意义(或者我们案例中的情感),神经网络必须知道哪个词按哪个顺序出现。
循环神经网络被叫做循环是因为他们对序列中的每个元素都执行同样的任务,并且输出是依赖于之前的计算。其他的方式去理解循环神经网络是它们有记忆,能够获取之前已经计算过的信息。这里有一个经典的循环神经网络:
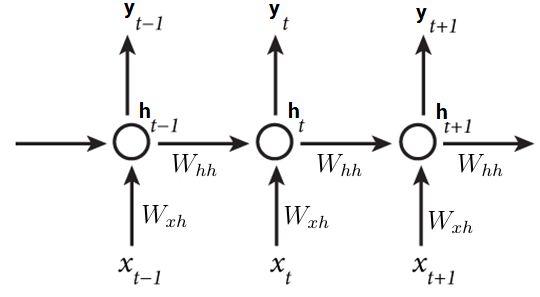
图1-循环神经网络架构
x(t-1),x(t),x(t+1)是彼此依赖的输入序列(例如句子中的单词)。y(t_1),y(t),y(t + 1)是输出。RNN的独特之处在于,输入x(t)的神经元的当前隐藏状态h(t)的计算取决于先前输入x(t-1)的先前隐藏状态h(t-1)。Wxh和Whh是权重矩阵,其分别将输入x(t)与隐藏层h(t)和h(t)与h(t-1)连接。通过这种方式,我们将神经网络的重复引入,可以将其视为先前输入的记忆。
从理论上讲,这种“vanilla”RNNs可以在任意长的序列中使用信息,但在实践中,它们仅限于循环中的几个步骤。
01
LSTMs
长短时记忆网络-通常简称为“LSTMs”一种特殊的RNN,能够学习到长期依赖。LSTMs 与RNNs没有根本不同的架构形式,但是它融合了额外的组件。
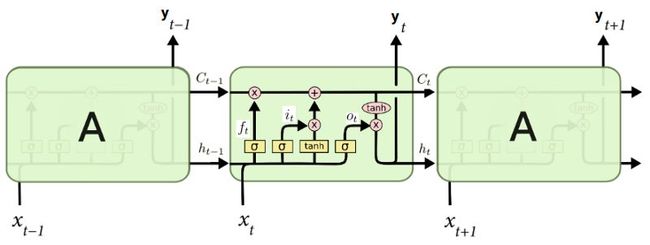
LSTM的关键是状态单元C(t),即横穿图顶部的水平线。除了仅仅只使用隐藏状态h(t)之外,单元状态是额外的方式来存储记忆。然而,与 “vanilla”RNN相比, C(t)使得LSTMs能够在更长的序列上工作成为可能。
更重要的是,LSTMs 可以在单元状态上删除或者增加信息,严格地被称为门的架构约束。门是一种可以选择地让信息通过的方式。一个LSTM有三种门结构,来保护和控制单元状态。
1. 遗忘门:在获取之前的输入x(t-1)的隐藏状态h(t-1)后,遗忘门帮助我们决定该从h(t-1)中删除什么,只保留相关信息。
2. 输入门:在输入门中,我们决定从当前输入x(t)添加内容到我们当前单元状态C(t)。
3. 输出门:正如名字所说一样,输出门决定从当前单元状态C(t)输出什么到下一个C(t+1)。对于语言模型例子而言,因为它只能看见一个主语,它可能希望看到一个和动词有关的信息,来控制接下来要发生的情况。举个例子,它可能输出主语是单数还是复数,这样我们就可以知道接下来的动词应该变成什么形式。
每一种状态的背后都是独立的神经单元。可以想象,这将会使得LSTMs变得相当复杂。在这一点上,我不会继续深入讲更多关于LSTMs的细节。
02
预处理
在我们用这些评论作为循环神经网络的输入之前,对这些数据做一些预处理是有必要的。这里我们的主要目的是减小观测空间。
01
单词的统一书写
考虑像"Somethiing"和“something”这些单词,对我们人来说,这些词有着同样的意思,它们之间唯一的区别是第一个字母是大写,因为它或许是句子中的第一个词。但是对于神经网络而言,由于不同的书写,这些单词将有(至少在开始的时候)不同的意思。只有在训练阶段,神经网络才可能学习到或者学习不到识别这些意思相同的词。我们目的就是避免这些错误理解。
因此,预处理的第一步就是把所有字母都变成小写字母。
02
删除特殊字符
像. , ! ? '等等特殊字符,不能对一段评价的情感分析起到促进作用,因此可以被删除。
最后结果
考虑以下未处理的评价例子:

我们做完上面所说的预处理步骤后,这个评价例子看起来如下所示:

预处理将会应用于数据集上的每个评价。
03
“词—索引”映射
另一个重要步骤是创建称为“词—索引”的映射,这个映射为数据集中每一个单词分配一个唯一的整数值。在我所使用的数据集中,全部的正向和负向评论共包含18339个不同的单词。因此“词—索引”映射有相同数量的条目。这个数量被称为词汇数(vocabulary size)。
我得到的 “词—索引”映射中的第一个和最后一个条目如下:

由于我们不能将字符串格式的数据输入神经网络,因此为数据集中的单词分配唯一整数值的步骤非常关键。通过“词—索引”映射,我们可以使用整数代替字符来表示整个句子和评论。考虑以下评论:

使用”词—索引”映射 , 可以用一个整数向量来表示这条评论,每一个整数表示映射中对应的单词:

03
词嵌入
当然,神经网络既不能接受字符串,也不能接受单个整数值作为输入。我们必须使用词嵌入(word embedding)向量来代替。
词嵌入是一种分布式的文本表示,这可能是深度学习方法在挑战NLP问题上令人印象深刻的关键突破之一。词嵌入实际上是一种用实值向量表示单词的技术,通常具有数十或数百个维度。每个单词被映射到一个特定的向量,向量值由神经网络学习。
与单词的稀疏表示方式不同,词嵌入不需成千上万的维度。例如,我们可以使用词嵌入技术把单词“although”和“life”表示成十维向量:
1. although = [0.8 1.0 4.2 7.5 3.6]
2. life = [8.3 5.7 7.8 4.6 2.5 ]
表示数据集中单词的全部向量组成一个大型矩阵,称为嵌入矩阵(embedding-matrix)。该矩阵的行数表示词嵌入的维数,列数表示词汇量,或者说数据集中不同单词的个数。因此,这个矩阵的每一列表示数据集中每个单词相应的的嵌入向量。
我们应如何从矩阵中找出单词对应的列?此时我们需要参考词—索引映射。假设你想查找单词“although”的嵌入向量,根据单词—索引映射,单词“although”由数字2511表示。接下来,我们需要创建一个长度18339为的独热向量,这里的向量长度等于数据集中的单词数量,向量的第2511位取值为1,其余为0。
通过对嵌入矩阵和独热编码向量进行点积运算,我们得到矩阵中的第2511列,即为单词“although”的嵌入向量。
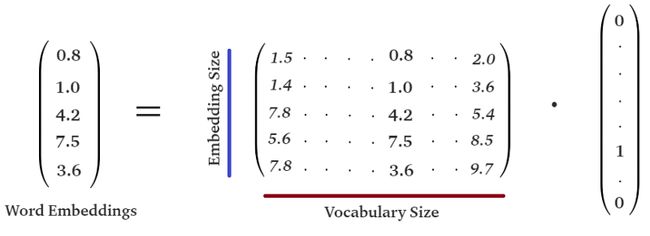
这样我们就可以将整个字符串段落或Netflix评论提供给LSTM。我们只需在单词到索引映射中查找每个单词的整数值,创建适当的独热编码向量并使用矩阵执行点积。然后将评论逐字(矢量形式)馈送到LSTM网络中。
04
获得评论情感
到目前为止,你已经了解了如何预处理数据,以及如何将评论输入LSTM网络中。现在,让我们讨论一下如何获得给定评论的情感。
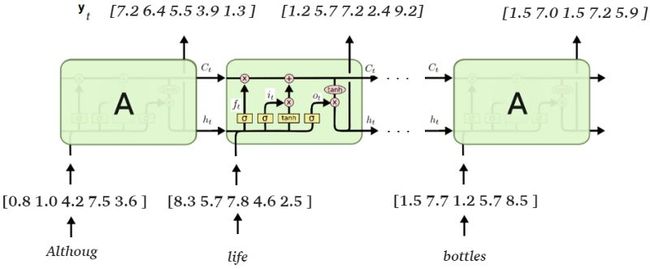
对于每一个时间步长t,将向量x(t)输入LSTM网络中,得到输出向量y(t)。在不同的步长上进行此操作,直到输入向量为x(n),n代表评论中全部单词的长度。我们不妨假设n=20,直到输入向量为x(n),LSTM模型输出向量y(n)为止,全部20个向量中,每个向量都代表一定含义,但仍然不是我们所需要的评论中的情感。实际上,向量y是神经网络生成的对评论特征的编码表示,这些特征在判断情感时非常重要。
y(8)表示评论中前8个单词的神经网络识别特征。另一方面,y(20)表示评论整体的特性。尽管只使用最后一个输出向量y(20)足以进行情感判断,但我发现如果使用y(0) - y(20)的全部向量来确定情感,结果会更加准确。为了使用全部向量,我们可以计算这些向量的均值向量。我们称这个均值向量为y_mean。
现在,均值向量y_mean可以用编码的方式来表示评论中的特征。我们需要在模型最后增加一个分类层,使用均指向量y_mean将评论划分为正向情感类和负向情感类。在最终的分类层中,需要将均值向量y_mean和权重矩阵W相乘。
以上描述的情感分析过程已经在我的GitHub repo上一个深度学习模型中实现。欢迎你来尝试和复现。模型训练完成后,可以对新的评论进行情感分析:

本文编辑:王立鱼
英语原文:
https://towardsdatascience.com/sentiment-analysis-with-deep-learning-62d4d0166ef6


星标我,每天多一点智慧