【机器学习】一文读懂准确率、精确率、召回率、F1分数、ROC-AUC都是什么
在机器学习中衡量一个模型是否准确我们有很多指标:
准确率 - accuracy
精确率 - precision
召回率 - recall
F1分数-F1 score
ROC曲线下面积 - ROC-AUC (area under curve)
那么,这些指标到底都是什么呢?各自有什么优缺点呢?笔者在了解这些指标的时候是在网上各大网站(CSDN、博客园、知乎)上找文章学习的。但是这些文章要么是过于数学化,要么是有地方不那么好读(前后变量不一致导致阅读苦难)、要么是过于“去数学化”。我自己整理了一份学习笔记,一定能够让大家一次性读懂这几个指标。
下面进入正文:
大家要明白,以上指标统统离不开一个工具:混淆矩阵-confusion matrix
混淆矩阵是个什么东西?
对于二分类问题,每一条数据要么预测正确,表示为1;要么预测错误,表示为0(注意这里是预测结果正确与否,而不是预测结果是0还是1),而事物本身也是被分为0(负样本)和1(正样本)两类。
用矩阵来表示就是这个样子

TP:True&Positive(positive表示正样本,true表示预测正确,即预测为positive是正确的)
FP:False&Positive(positive表示正样本,false表示预测错误,即预测为positive是错误的)
FN:False&Negative(negative表示负样本,false表示预测错误,即预测为negative是错误的)
TN:True&Negative(negative表示负样本,true表示预测正确,即预测为negative是正确的)
下面正式讲解五种指标:
一、准确率
很直观,就是预测正确的个数/总样本数,如果用混淆矩阵里的数据表示,就是(TP+TN)/(TP+FP+FN+TN)。讲道理这其实是正常人最能理解也最常用的评价指标了。但其实这个指标有个缺陷。机器学习的模型经常会出现在一个数据集上表现良好,但是在另一个数据集上却一塌糊涂的情况。假设一个数据集有100条数据,99个1,1个0,而你的模型所有的输出都是1,那么你的模型在该数据集上的准确率是99%,惊人的高。但实际上你的模型没有意义,因为只能输出1。这就反映出了准确率的弊端。

二、精确率
又名查准率,类似于准确率,但有别于准确率。精确率指的是预测为1的样本中实际为1的频率,也就是TP/(TP+FP)。精确率代表的是正样本结果中的预测准确度,准确率是既考虑了正样本也考虑了负样本。照这个逻辑,上面的例子的精确率是0.99。

三、召回率
召回率又叫查全率,其公式为TP/(TP+FN)。这个比率反映了正样本被正确预测的比例,在传染病学领域有极高的意义,我们规定“有病”为正样本,即为1。TP表示被在正确诊断为有病的个数,FN表示本来有病却被诊断为没病的个数。召回率越高,表示我们准确确诊的能力就越强。召回率低说明有大量有病案例被诊断为没病,这就非常可怕。

四、F1分数
F1分数的计算公式为:
F1score=(2*precision*recall)/(precision+recall)
如果将F1分数在不同阈值(阈值的概念下面有介绍)下绘制出来,就得到了P-R曲线(精确率-召回率曲线)。何为阈值?我们都知道,对于二分类问题,模型的输出仅仅是概率,当1的概率为0.8,0的概率为0.2时,我们认为模型预测的结果为1。一般情况下,我们取大于0.5的那个概率作为模型的预测结果,这个0.5就是阈值。但是实际中,阈值为0.5的时候可能不能保证模型的精确率和召回率,因此,我们常常需要尝试不用的阈值,该曲线就是在不同阈值下绘制的P-R关系图。
F1分数其实是精确率和召回率的调和平均(倒数之和的平均值的倒数)
五、ROC_AUC
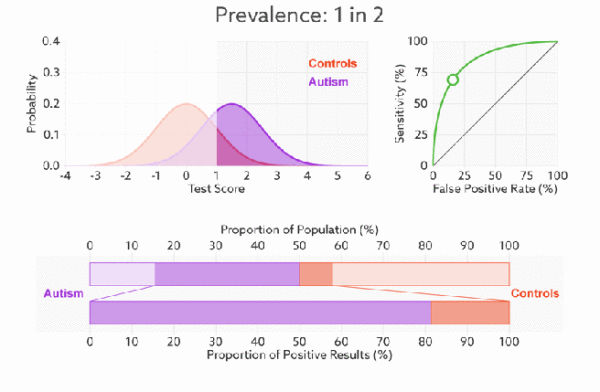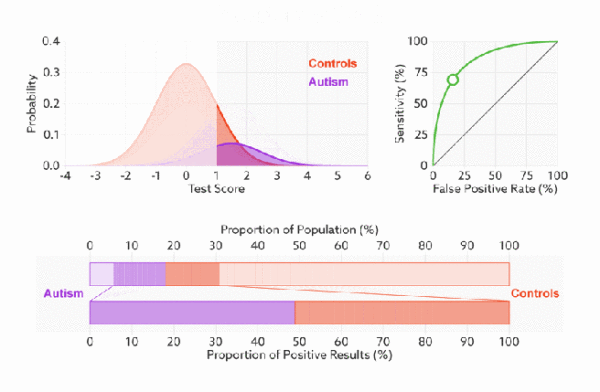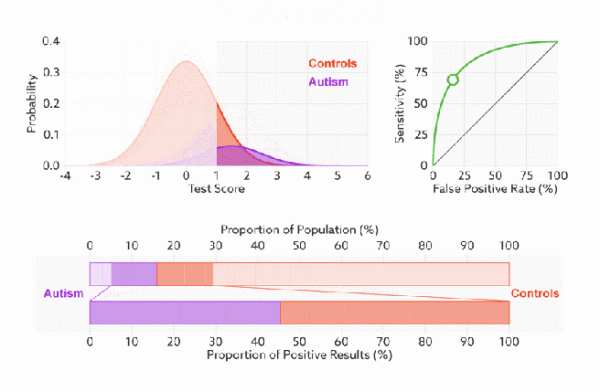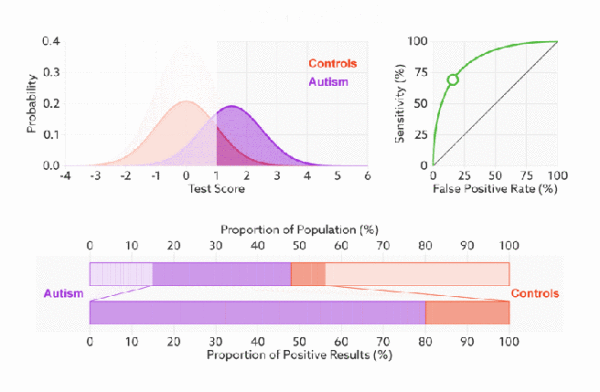
ROC(receiver operating characteristic curve:接受者操作特征曲线)是一条曲线。该曲线涉及两个指标:真正率(TPR)和假正率(FPR)
真正率就是召回率,假正率(1-特异度)=FP/(FP+TN)。

下面是真正率和假正率的示意,我们发现TPR 和 FPR 分别是基于实际表现 1 和 0 出发的(注意看分母,分母分别是实际为1和实际为0),也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。 正因为如此,所以无论样本是否平衡,都不会被影响。还是拿之前的例子,总样本中,99% 是正样本,1% 是负样本。我们知道用准确率是有水分的,但是用 TPR 和 FPR 不一样。这里,TPR 只关注 99% 正样本中有多少是被真正覆盖的,而与那 1% 毫无关系,同理,FPR 只关注 1% 负样本中有多少是被错误覆盖的,也与那 99% 毫无关系。通俗的讲:**真正率就是正样本中预测正确的比率,假正率就是负样本中预测错误的比率。**按照这个逻辑,上面的例子中真正率为1,假正率为1。
我们以FPR为x轴,TPR为y轴画图,就得到了ROC曲线。
与F1分数曲线一样的是,ROC也是通过遍历阈值的方式绘制的。

我们如何通过ROC曲线判断一个模型的好坏?
针对一个模型,我们希望的是假正率(X值,自变量)一定的时候真正率(Y值,因变量)越高越好,也就是曲线“越上凸”就越好。
由于,ROC曲线的xy值都是正负样本的准确率(错误率),因此,**无论我们给的样例中正负样本的个数孰多孰少,都不会影响ROC的形状,我们可以称ROC曲线“无视样本的不平衡”,**这是ROC曲线比前几种指标更加准确合理的根本原因。
那AUC(曲线下面积)又是干嘛的呢?
上面提到,ROC曲线越上凸模型就越好,那有没有什么度量指标能够量化这种好呢?答案就是用曲线下方的面积,也就是曲线在0到1上的积分。
比较有意思的是,如果我们连接对角线,它的面积正好是 0.5。对角线的实际含义是:随机判断响应与不响应,正负样本覆盖率应该都是 50%,表示随机效果。 ROC 曲线越陡越好,所以理想值就是 1,一个正方形,而最差的随机判断都有 0.5,所以一般 AUC 的值是介于 0.5 到 1 之间的。
本人还是学生,学识尚浅,如有不正确的地方欢迎大家在评论区指正~
(图片来源见水印,侵删)