ECCV|2018 几何约束联合车道分割和车道边界检测
--------------------------------
原文链接:https://pan.baidu.com/s/1wxu3BT_1ONsHkO_Gzx1VYw
--------------------------------
简介:

--------------------------------下面为全文翻译:
Geometric Constrained Joint Lane Segmentation
and Lane Boundary Detection
几何约束联合车道分割和车道边界检测
摘要:
车道检测在高级驾驶辅助系统中发挥着不可或缺的作用。用于车道检测的现有方法可以分类为车道区域分割和车道边界检测。当开发(exploit,个人觉得有确定,画出的有意思) 车道区域和车道边界时,这些方法中的大多数放弃了大量的补充信息,例如几何先验。在本文中,我们建立了一个多任务学习框架来分割车道区域并同时检测车道边界。我们提出的框架的主要贡献是这两方面:(1)提出了一种多任务学习框架,在车道分割和车道边界检测之间具有相互关联的子结构,以提高整体性能。(2)提出了一种新的损失函数,其中考虑了两个几何约束,假设车道边界被预测为车道区域的外轮廓,而车道区域被预测为车道边界线内的区域积分结果。通过端到端的培训流程,这些改进极大地增强了我们在多个指标上的方法的稳健性和准确性。这个提出的框架在KITTI数据集,CULane数据集和RVD数据集上进行评估。与现有技术相比,我们的方法在指标上实现了最佳性能,并在各种交通场景中实现了更具鲁棒性的检测。
1.介绍:
自动驾驶的轨迹规划是计算机视觉领域中极具挑战性的任务。车道检测是轨迹规划中的一个关键问题,它对不同的车道进行分类并产生明确的驾驶区域。
在早期工作中提出了基于纹理的方法。 聚合来自不同颜色空间的纹理特征以增强异常值下的车道检测的鲁棒性。 通常,在车道区域中存在均匀区域,因此难以为这些区域建立可区分的特征描述符。
如果没有足够的纹理信息可供依赖,车道边界的补充对于精确检测车道区域至关重要。传统方法提取边界信息以解决在车道区域中均匀区域的问题,其中主要使用高通滤波器。在提取边界信息的情况下,通过车道边界绘制检测到的车道区域。但是,由于遮挡和划线标记,边界信息经常丢失。 严重地,周围的阴影和车辆经常会引入无关的信息,这些信息会影响检测性能。近年来,提出了完全卷积神经网络(FCN),其中利用编码器 - 解码器结构自学习上下文特征以增强车道分割。FCN取得了比传统方法更好的性能。在不良照明和缺少车道边界条件下,FCN很难有效地提取有效的上下文信息并提供显着的,唯一的车道区域表示。
实际上,在车道区域与其边界之间存在几何关系:车道区域总是位于车道边界之间,而车道边界由车道区域的外轮廓组成。为了利用这种关系,通过顺序处理策略推进(提出)了一些先验模型。一些模型提取车道边界以大大减少车道检测的搜索范围。给定车道边界,将分割算法应用于有界区域以细化(改善)车道标签。相反,一些模型首先划分车道区域。 然后通过具有公差范围(可容忍范围)的 分割车道区域周围的高通滤波器提取边界信息。然而,这些模型将车道区域分割和车道边界检测视为两个单独的子过程,它们彼此不共享信息,导致几何依赖性的损失。此外,当第一个子过程受到异常值的严重干扰时,可能会发生极差的性能。
为了解决上述问题,我们有想法通过多任务学习框架提供车道区域分割和车道边界检测的统一解决方案。我们不是简单地在最终决策阶段融合不同任务的输出,而是将一个共享编码器应用于神经网络,以整合两个任务的补充信息。另外,附加了称为链接编码器的新颖结构,其可以隐含地提取车道区域与其边界之间的相互关系信息。因此,两个任务之间的流动信息有效地改善了彼此的性能。在分类器层,通过在原始输出上叠加这样的细化(改善)来生成结果。如图1所示,分割受到异常值的严重干扰,无法从错误分割中恢复。在我们的方法中,当车道区域分割无法分割一些比较难分割的情况时,若另一个任务,即车道边界检测具有良好的表现,则车道边界检测可以为车道分割提供有效的特征信息以使车道分割任务能从故障(表现不好)中恢复过来。反之亦然。此外,在我们的模型中提出了两个几何先验约束,能将车道检测问题规则化为适定的表达公式。给定车道边界检测,我们将车道区域预测为区域积分结果,其中车道边界为上限和下限。在Ren等人的启发下,软IoU损失计算方法测量了分割结果与gound true(标准答案)的差异,我们提出了一种新的IoU损失计算方法来测量边界一致性。给定提取的车道区域,车道边界被预测为(被视为)车道的外部轮廓。然后将预测结果和ground true(标准答案)之间的差异表述为两个可微分的损失项,以强调模型训练期间的几何先验。整个网络能够端到端地联合训练。
基准测试的实验结果表明,我们的方法在几个指标下优于其他最先进的方法。

Fig.1.几何关系的相互约束。Left:通过图像输入,传统方法为车道区域(绿色)或车道边界(红色)生成二进制分割掩码,这些掩码受到异常情况的严重影响。Right:我们的方法以隐式和显式方式将几何约束引入多任务网络,其能够相互恢复缺失的车道区域和车道边界(蓝色)。
2.相关工作
传统的车道分割方法主要利用像素级特征和超像素级特征.在像素级特征中,提取对阴影干扰鲁棒性高的颜色特征,用于使用8连通区域增长的车道区域分割。来自不同颜色空间的纹理特征由直方图峰值和时间滤波器响应来描述,然后在平坦区域内生成车道区域。Alon等人基于像素梯度图计算主导边缘并将它们形成为车道边界。在这些边界的指导下,遵循基于颜色的区域生长以生成车道区域。Valente等人首先提取像素级颜色特征并将其分类为车道区域。然后引入边界以约束车道区域的细化(完善,改善)。为了处理异常情况,优选使用超像素特征。Li等人用正则匹配追踪算法提取的超像素颜色特征来训练AdaBoost分类器,以提高在高模糊度下的车道检测。
随着深度学习方法的发展,语义分割取得了令人瞩目的成果。提出了几种改进的单任务网络,重点是将额外的知识嵌入到网络中。Gao等人提出了轮廓先验和位置先验,精巧地划分车道区域。由于缺乏先验和信息丢失,提出了多任务方法,通过引入更多的周围约束来解决,这种方法效果超越单任务方法。Oliveira等人用共享编码器训练联合了分类,检测和语义分割的网络。通过联合训练方式,最终的车道区域由拥有更多周围细节的增强特征生成。但是,在多个输出之间没有挖掘其内在的连接,因此很难解释网络结构背后的机制。
另一方面,大量的工作利用高通滤波器进行车道边界检测。 Haloi等人将来自二阶和四阶滤波器的响应结合起来,以通过自适应阈值处理获得车道边界特征。 Aly等用2D高斯核过滤逆透视映射(IPM)图像。 Kortli等人和Bergasa等人使用canny内核和Otsu方法检测边缘。
然而,车道边界检测的精度受到照明变化,噪声和杂乱背景的影响。一些深度学习技术被开发来大大提高检测性能。Overfeat 检测器用卷积网络来集成识别,定位,检测的方法被提出。之后,Huval等人修改了Overfeat结构,以同时处理车道边界检测和车辆检测。但是,这些方法对周围物体很敏感。因此,Li等人将卷积层提取的特征作为序列馈送到循环神经元层中,其中空间连续性约束用于规范车道检测的结果。Kim等人提出了一种更简单但有效的网络结构。 他们使用预先训练的VGG网络对网络进行微调,以生成检测结果。这些方法需要额外的数据才能进行充分的预训练,并且它们对杂乱的背景很敏感。我们的方法使用补充信息共享结构,并且在模型训练期间利用几何约束。因此,提取更多有效信息以表示车道和几何先验约束规则化了车道检测的不适定问题。
3.方法论
3.1多任务框架的概述
由人类感知而言,车道区域和车道边界是不可分离的。然而,现有的车道检测方法主要依靠单任务网络来独立训练车道分割和车道边界检测,完全忽略了两个任务之间固有的几何约束。像MultiNet这样的简单多任务网络被开发用于将任务组合在一起,例如分类,检测和分割,而并没有调查任务之间的固有(内在)关系。这些最先进的方法存在两个主要问题:多个训练任务之间的相互关系的丧失和适定的公式缺乏几何先验。 结果,他们总是陷入困难的例子中的检测失败。
受此观察的启发,我们提出了一个多任务学习框架,以提供车道分割和车道边界检测的统一解决方案。网络架构如图2所示,它由编码器网络和解码器网络组成,是一种完全卷积网络(FCN)。我们提出的(建议的)的框架不是使用两个独立的网络进行分割任务和检测任务,而是通过一个共享编码器网络和两个独立的解码器执行分割和检测这两个任务。为了将像素分类为二进制标签,每个解码器之后是sigmoid分类器。具体地,每个解码器连接到链路编码器以在两个任务之间传输补充信息,因此两个解码器的特征可以相互细化(完善,改善)。

Fig.2. 所提出的多任务学习框架。输入图像被送到共享编码器,该编码器提取车道区域分割和车道边界检测这两个任务的关键特征。连接到每个解码器的两个链路间编码器为每个任务提供补充信息。假设车道边界被预测为车道区域的外轮廓而车道区域被预测为车道边界线内的区域积分结果,则通过引入结构损失项来增强整体性能。
为了实现多任务学习框架的良好构造,我们通过引入任务之间的固有几何先验来提出新的损失函数,假设车道边界被预测为车道区域的外轮廓,而车道区域则预测为车道边界内的区域积分结果。这些几何先验对于找到车道分割和车道边界检测的一致解决方案至关重要。 通过端到端培训流程,这些改进极大地增强了我们在多个指标上的方法的稳健性和准确性。
3.2使用共享编码器提取关键特征
为了分别在单个任务学习框架中通过车道分割和车道边界检测的编码器来阐明激活区域,我们使用热图来可视化每个激活图。如图3所示,通过车道分割强调具有相似纹理的车道,这引起了车道检测的模糊问题。此外,一些背景区域被激活。 相反,背景中的边缘引起车道边界检测的更严重的异常值问题。提出了一种共享编码器,以大大减少模糊问题和异常值,因为在共享编码器的训练期间已经强调了对两个任务的性能改进至关重要的特征。与图3相比,在使用共享编码器时获得了更清晰的车道提取。
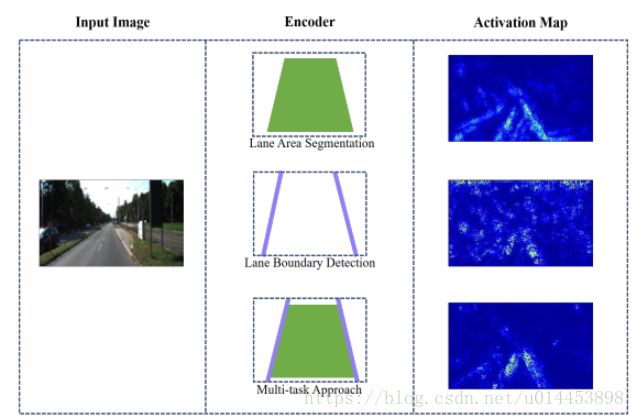
Fig.3. 编码器网络的激活图。两个激活图都是从最终的卷积层生成的。像素颜色表示与输入图像有关的任务(即面积检测和边界检测)相关显着性。
3.3 使用链路间编码器进行互补特征提取
共享编码器网络非常注重对整体性能增强至关重要的特征。但是,一个任务的某些重要特征可能会在其他任务中显得不那么重要而被其他任务所抑制。例如,车道区域分割非常强调细粒度纹理特征,以实现精确的像素标签。相反,车道边界检测更喜欢边缘性特征。
提出了一种链路间编码器网络,用于在两个任务之间传输互补信息,从而可以相互细化(完善,改善)两个解码器网络中的特征。如图2所示,解码器网络最初接收特征f并输出初步结果作为链路间编码器网络的输入。然后,这些解码器网络利用被链路间编码器网络精细化(细化过,完善过)的特征生成最终结果,其中特征f使用简单级联与链路间编码器网络输出l1和l2互补。因此解码器网络至少向前传递两次。这些精细化(细化过,完善过)的特征增强了车道的呈现。期望以统一的方式改善车道分割和车道边界检测的性能。
在图4的第一行,生成分割结果而没有互连编码器,其中红色区域表示假阳性和假阴性
结果。底行显示使用链路间编码器网络细化之前和之后的差异图像,其中使用热图突出显示像素以表示分割置信度的得分。

Fig.4. 原始图像和初始网络生成的FP + FN区域(红色)。底行:链路编码器优化前后的差异图像。如热图所示,最初的假阳性结果被有效地抑制,如蓝色所描绘的。同时,一开始错过的车道像素得到了很好的恢复,如暖色调所强调的那样。
3.4 几何约束结构损失函数(Loss)
在本节中,我们提出了一种考虑车道区域固有(内在的)几何特征的新型损失函数。除了传统的交叉熵损失函数之外,两个结构感知损失函数分别被添加到车道区域分割和车道边界检测中。
车道区域分割的边界感知损失
由于高模糊性,将交叉熵设置为用于车道区域分割的损失函数将会导致像素组具有错误的标签。假设分割车道区域的边界与车道边界的标准答案(ground true)之间存在一致性,我们引入了车道区域分割的边界感知损失函数。值得注意的是,如图5所示,通过像素比较,车道边界与标准答案(ground true)的轻微偏差可能产生极大的损失(误差)。因此,我们采用IoU损失函数来测量边界不一致性。因此,轻微的偏差将导致小的IoU损失(误差),这确保了收敛。让I表示图像中的像素集。 对于像素集I中的每个像素p,yp对应于其输出概率。而g={0,1}^(MxN) 是像素集I的标准答案(ground true)。M和N是图片的高度和宽度。通过给车道边界的标准答案(ground true)打上车道区域掩码,我们的边界感知损失函数lba就可以被定义为:

乘号x表示像素间的相乘。
施加两个一致性约束以增强车道分割的结果。交叉熵损失项lice测量分割区域与其标准答案(ground true)之间的一致性。另外,损失项lba测量分割区域的边界与车道边界标准答案(ground true)之间的一致性。相应地,测量车道分段总误差的损失函数llt更新为:

是平衡两个损失项的常数。我们一般设置为0.5。仅涉及逐像素线性计算,lba是完全可微分的。

Fig.5 边界感知损失和区域感知损失。左边:边界感知损失(Loss)的图。蓝色区域表示边界不一致。右边:区域感知损失(Loss)的图。预测区域中的不同强度表示不同的预测置信度。 恢复区域和标准答案(ground true)之间的差异表明区域方面的误差。
车道边界的区域感知损失(Area-aware Loss For Lane Boundary.)。车道边界检测与车道区域分割相比,由于边界周围的较低SNR(信噪比),车道边界检测受较高的丢失率影响较大。在车道区域是以车道边界作为上限和下限的区域积分结果的几何先验的推动下,提出了区域感知损失函数来测量从检测到的车道边界恢复的车道区域与车道区域标准答案(ground true)之间的差异。我们的区域感知损失函数表示为:

其中G 是车道区域标准答案(ground true的像素标签集合,G(p)= 1表示像素p属于车道区域,Ir(p)像素p属于恢复区域的概率。测量车道边界检测误差的损失函数lmt定义为:

其中lmce是交叉熵损失函数,以互补的方式测量检测到的车道边界与其标准答案(ground true)之间的一致性。我们把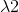 设置为1。具有强空间相关性的像素总是呈现相似的强度分布,因此我们直接从车道边界上的最近像素估计恢复的车道区域中的像素强度。将两个边界车道边界的像素表示为像素集B。对于车道边界标准答案(ground true)之间的像素p,其属于车道区域的概率等于车道边界上最近像素的概率,其计算如下:
设置为1。具有强空间相关性的像素总是呈现相似的强度分布,因此我们直接从车道边界上的最近像素估计恢复的车道区域中的像素强度。将两个边界车道边界的像素表示为像素集B。对于车道边界标准答案(ground true)之间的像素p,其属于车道区域的概率等于车道边界上最近像素的概率,其计算如下:

d(x,y)是像素x和像素y之间的欧几里得距离。Ib(v)是边界检测图中的像素概率。
从公式(6),(7)中计算恢复的车道区域,我们改良了损失函数laa,如下:
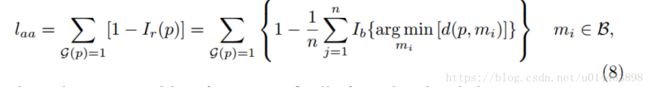
因此,最终完整的损失函数为:
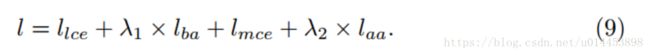
3.5训练细节
我们的框架旨在完全卷积和可微分,因此可以以端到端的方式进行训练。在本节中,我们主要关注训练过程的实施细节。
共享编码器网络由具有VGG结构的ImageNet初始化。首先,我们从训练单个车道分割子网开始。然后,我们转向车道区域分割和边界检测的子网,这是在没有链路编码器网络结构的情况下训练的。 最后,我们的多任务学习框架进行了全面的再培训,增加了链接间编码器网络。我们将全零张量连接到共享编码器的输出,以便解码器的输入特征维度在迭代训练过程中保持相同。整体框架使用批量正则化,批量大小为3。为避免过度拟合,采用dropout层,速率为0.2。 我们使用Adam优化器并预先训练车道分段和车道边界检测子网,学习率为10-3。 对于多任务框架训练过程,学习率设置为10-4直到收敛。
4.实验
我们在双线车道分割数据集上评估我们的方法:KITTI数据集
,道路车辆数据集(RVD)和CULane数据集。我们的方法由Tensorflow编写。在具有160 * 320输入图像的GeForce GTX TITAN上评估处理时间。 更多实验结果显示在我们的补充材料中。
4.1 数据集和评估
KITTI数据集包含289个训练图像和290个测试图像,包括四个道路场景子集:城市标记道路(UM),城市多重标记道路(UMM),城市无标记道路(UU)和URBAN ROAD(前三个联合))。UM被定义为具有两个车道的标记道路,而UMM由具有多个车道的道路组成。UU代表没有车道标记的道路,仅包含一条车道。
RVD数据集包含超过10小时的交通场景,其中多个传感器在不同的天气和道路条件下,包括高速公路场景,夜景和雨天。此数据集中有超过10,000个手动标记的图像,这些图像根据周围条件(如天气和照明)划分为不同的场景。
CULane数据集包含从55小时交通视频中提取的133,235个图像,其分为88,880个用于训练集的图像,9,675个用于验证集和34,680个用于测试集的图像。测试集根据其场景分为8个子集,以展示不同网络结构的稳健性。 这个新发布的数据集仅包含车道边界标准答案(ground true),因此我们根据车道边界的有界区域生成车道区域标准答案(ground true)。
为了评估车道分割结果,我们遵循经典的逐像素分割度量,精确度(P),召回率(R),F1度量和IoU得分。不考虑去除透视效应的指标,因为反透视映射会导致标准答案(ground true)的扭曲。
对于车道边界检测,我们使用逐像素度量来评估性能。在KITTI数据集上,当检测到的车道边界和标准答案(ground true)的距离小于阈值(图像对角线的1.5%)时,检测到的车道边界被视为正(True Postion)。在CULane数据集上,我们遵循其指标进行公平比较。当检测到的车道边界和标准答案(ground true)的IoU大于0.5阈值时,检测到的边界被视为正(True Postion)。对于所有比较方法都是如此。 最终结果用精度(P),召回(R)和F1测量来评估。

表1. URBAN,ROAD,KITTI数据集的车道分段结果。 “多任务(multi-task)”,“丢失(loss)”,“链接(inter-link)”和“链接+损失函数(inter-link+loss)”各自表示没有损失函数或链路结构的网络,只有损失函数的网络,仅具有链路结构的网络,损失函数和链路结构都具有的网络。
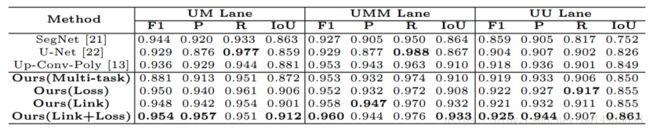
表2. KITTI子集(UM / UMM / UU)上的车道分段结果
4.2 结果和结论
我们的实验分为两部分。 首先,我们将我们的车道区域分割方法与KITTI数据集,CULane数据集和RVD数据集上的最新方法进行比较。然后,为了证明我们的多任务结构的有效性,在KITTI数据集和CULane数据集上评估车道边界检测结果。 不考虑RVD是因为它只提供了车道终点的标准答案(ground true),它无法处理曲线车道边界的情况
KITTI数据集上的车道分割结果:首先将所提出的网络与KITTI数据集上的最新方法(包括SegNet [21],U-Net [22]和Up-Conv-Poly [13])进行比较。 表1显示了总体结果。与基线方法[21](baseline)相比,我们的方法在各个方面都优于它。 即使没有添加链路间编码器网络和结构损失函数,联合训练也可以显着提高性能。受益于对任务之间固有(内在)的相互关系的研究,我们的多任务框架获得了比单任务网络更好的特征表示(representation),并进一步提高了性能。
请注意,我们的方法也优于U-Net和Up-Conv-Poly,IoU得分增加了4.0%和1.9%。两种方法都将编码器层与解码器层连接起来,这使得解码器直接从编码器接收相同的规模(scale)信息。我们的多任务网络更好地捕获了车道和标记的几何结构的依赖性。 我们还评估了表2中几种不同交通场景的方法。结果表明我们的方法对场景变化很有效。
我们研究了链路间编码器和结构损耗函数对我们模型的影响。 请注意,我们的只有结构损失函数的方法的IoU得分为86.1%,只有链路结构的方法的IoU得分为86.5%。随着链路间编码器网络和损耗函数的加入,我们的最终方法(链路+损失函数)在IoU上达到87.3%,在F1测量上达到93.2%。单独应用的结构损失函数和链接间编码器网络在促进分割结果中起着至关重要的作用。图7分别显示了通过我们的方法,KITTI数据集上的Up-Conv-Net方法和U-Net方法获得的一些车道区域分割结果。我们的方法有效地准确率高地处理了某些困难情况,例如图7的前两列的边界消失。
为了证明结构损失函数的效率,我们使用和不使用结构损失的方法通过图6中的单个图像的几个示例来评估。我们在KITTI数据集中随机选取100个图像,并计算两种方法的IoU得分。评价结果表明,结构损失函数的引入对干扰具有较高的鲁棒性。
CULane数据集上的车道分割结果。我们还评估了新发布的CULane数据集的车道分割。 测试集分为8个不同的场景:箭头,拥挤,曲线,炫光,夜晚,无线,正常和阴影。整体表现也显示在最后一栏中。

实验结果如表3所示。值得注意的是,我们的方法在所有8个子集上都优于最先进的方法,并且在整个数据集上实现了90.2%的F1-测量和82.4 IoU评分,这表明我们的方法更多 与最先进的方法相比,几乎可以处理所有交通场景。此外,我们的方法在4个子集(箭头,人群,阴影和正常)上实现了显着的改进。 这是因为我们的方法可以从杂乱的背景中捕捉车道边界结构。 良好提取的边界特征提供补充信息以有效地抑制错误分割.

在RVD数据集上的车道分割结果。此外,我们评估RVD数据集上的车道分段。 如4.1中所述,该数据集包含三个不同的场景:公路,夜晚和雨天和下雪天。 除了SegNet,U-Net和Up-Conv-Poly之外,我们还评估了提出RVD数据集的CMA方法的性能。

总体结果显示在表4中。注意,CMA仅提取两个车道边界的终点以分割车道区域。 这在网络上强制执行严格的几何假设,因此无法分割曲线通道。相比之下,我们网络中引入的几何先验适用于各种场景,并自适应地学习更好的边界特征,实现了对所有指标的显着改进。虽然由于背景清晰,两种方法在高速公路上的表现相似,但我们在其他场景中的表现也大为改善,特别是在夜间场景中。 通过更好地表示边界信息和几何约束,我们的方法可以很好地处理光照变化和图像质量下降。


车道边界检测结果。除了车道分割,我们还评估车道边界检测对KITTI和CULane数据集的有效性。 我们用手动标记的车道边界标准答案(ground true)测试了几种方法,并展示了SegNet ,SegNet-Ego-Lane和SCNN 的性能。我们仅仅用交叉熵来评估来说明强调我们的方法的结构损失函数在KITTI数据集上的有效性。另外一些车道边界检测的结果也在图7中展示出来。表5中提供了KITTI数据集的结果。至于精度,SegNet略高于我们。 但是,SegNet的召回率极低,这表明SegNet错过了很多真正的积极因素(True Postion)。与其他方法相比,我们的方法实现了最高的召回率,以及F1测量。我们的方法的消融分析表明,车道区域感知损失函数显着改善了车道边界检测的性能,特别是在召回率方面。 我们的准确率为3.2%,召回率为5.3%,F1测量为4.3%。
CULane数据集的结果如表6所示。请注意,我们的方法在7个子集上优于最先进的方法。 最先进的方法具有较差的性能,主要是由于图像劣化和车道边界的缺失。至于图像质量下降问题,我们的子网能用我们的区域感知损失函数提取比最先进的方法更好的边界特征和区域特征。因此,我们在Night,Dazzle Light和Shadow子集上显着提高了性能,其中图像质量受到照明条件的严重影响。对于看不见车道边界的问题,很难为边界检测提取足够的边界特征。尽管SCNN引入了用于边界检测的上下文信息,但是各种场景包含极其不同的上下文信息,导致车道检测结果的不准确。同时,我们的链接间结构利用了车道区域和边界之间更强大的几何关系,这些关系相互约束以获得更好的性能。
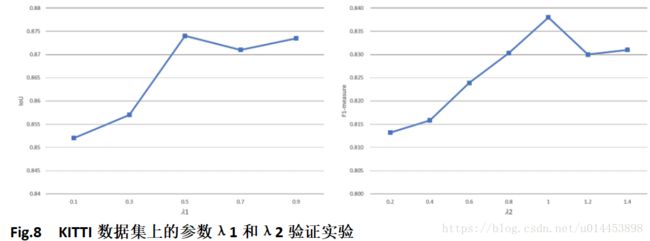
4.3 参数学习
为了选择最佳参数λ1和λ2,在10倍交叉验证集上进行参数研究。通过车道区域分割的IoU得分来比较不同λ1值的性能,而通过F1-车道边界检测的度量来评估λ2性能。最终结果如图8所示,其中两个参数均以固定间隔选择。虽然大于0.5的λ1都能实现了类似的IoU分数,但实验表明大的λ1对超参数敏感。 所以λ1设置为0.5。 并且λ2设置为1.0以获得最佳性能
5.结论
我们提出了一个多任务学习框架来共同解决车道分割和车道边界检测的问题。在此框架下,提出了共享编码器网络和链路间编码器网络结构,通过实验证明了其提高检测精度的好处。此外,我们提出了两种新的损失函数,它们被建立以适用于更一般的交通场景。 将所提出的方法与KITTI和RVD数据集上的现有方法进行比较,并显示出领先的性能。
6.参考文献
- Levinson, J., Askeland, J., Becker, J., Dolson, J., Held, D., Kammel, S., Kolter,
J.Z., Langer, D., Pink, O., Pratt, V.R., Sokolsky, M., Stanek, G., Stavens, D.M.,
Teichman, A., Werling, M., Thrun, S.: Towards fully autonomous driving: Systems and algorithms. In: IEEE Intelligent Vehicles Symposium (IV), 2011, BadenBaden, Germany, June 5-9, 2011. (2011) 163{168
2. Alvarez, J.M., L´opez, A.M., Baldrich, R.: Shadow resistant road segmentation from ´
a mobile monocular system. In: Pattern Recognition and Image Analysis, Third
Iberian Conference, IbPRIA 2007, Girona, Spain, June 6-8, 2007, Proceedings, Part
II. (2007) 9{16
3. Li, J., Jin, L., Fei, S., Ma, J.: Robust urban road image segmentation. In: Proceeding of the 11th World Congress on Intelligent Control and Automation. (June
2014) 2923{2928
4. Lu, K., Li, J., An, X., He, H.: A hierarchical approach for road detection. In: 2014
IEEE International Conference on Robotics and Automation, ICRA 2014, Hong
Kong, China, May 31 - June 7, 2014. (2014) 517{522
5. Kortli, Y., Marzougui, M., Bouallegue, B., Bose, J.S.C., Rodrigues, P., Atri, M.:
A novel illumination-invariant lane detection system. In: 2017 2nd International
Conference on Anti-Cyber Crimes (ICACC). (March 2017) 166{171
6. Aly, M.: Real time detection of lane markers in urban streets. CoRR
abs/1411.7113 (2014)
7. Haloi, M., Jayagopi, D.B.: Vehicle local position estimation system. CoRR
abs/1503.06648 (2015)
8. Bergasa, L.M., Almeria, D., Almaz´an, J., Torres, J.J.Y., Arroyo, R.: Drivesafe: An
app for alerting inattentive drivers and scoring driving behaviors. In: 2014 IEEE
Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, June 8-11, 2014.
(2014) 240{245
9. Fischler, M.A., Bolles, R.C.: Random sample consensus: A paradigm for model
fitting with applications to image analysis and automated cartography. Commun.
ACM 24(6) (1981) 381{395
10. Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic
segmentation. CoRR abs/1411.4038 (2014)
11. Barnes, D., Maddern, W., Posner, I.: Find your own way: Weakly-supervised
segmentation of path proposals for urban autonomy. In: 2017 IEEE International
Conference on Robotics and Automation, ICRA 2017, Singapore, Singapore, May
29 - June 3, 2017. (2017) 203{210
12. Gao, J., Wang, Q., Yuan, Y.: Embedding structured contour and location prior in
siamesed fully convolutional networks for road detection. In: 2017 IEEE International Conference on Robotics and Automation, ICRA 2017, Singapore, Singapore,
May 29 - June 3, 2017. (2017) 219{224
13. Oliveira, G.L., Burgard, W., Brox, T.: Efficient deep models for monocular road
segmentation. In: 2016 IEEE/RSJ International Conference on Intelligent Robots
and Systems, IROS 2016, Daejeon, South Korea, October 9-14, 2016. (2016) 4885{
4891
14. Alon, Y., Ferencz, A., Shashua, A.: Off-road path following using region classification and geometric projection constraints. In: 2006 IEEE Computer Society
Conference on Computer Vision and Pattern Recognition (CVPR 2006), 17-22
June 2006, New York, NY, USA. (2006) 689{696 - Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks:
Visualising image classification models and saliency maps. CoRR abs/1312.6034
(2013)
16. Zhang, G., Zheng, N., Cui, C., Yang, G.: An efficient road detection method in
noisy urban environment. In: Intelligent Vehicles Symposium. (2009) 556{561
17. Chen, S., Zhang, S., Shang, J., Chen, B., Zheng, N.: Brain inspired cognitive model
with attention for self-driving cars. CoRR abs/1702.05596 (2017)
18. Ren, M., Zemel, R.S.: End-to-end instance segmentation with recurrent attention.
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR
2017, Honolulu, HI, USA, July 21-26, 2017. (2017) 293{301
19. Katramados, I., Crumpler, S., Breckon, T.P.: Real-time traversable surface detection by colour space fusion and temporal analysis. In: Computer Vision Systems,
7th International Conference on Computer Vision Systems, ICVS 2009, Li`ege, Belgium, October 13-15, 2009, Proceedings. (2009) 265{274
20. Valente, M., Stanciulescu, B.: Real-time method for general road segmentation.
In: IEEE Intelligent Vehicles Symposium, IV 2017, Los Angeles, CA, USA, June
11-14, 2017. (2017) 443{447
21. Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional
encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2017)
22. Ronneberger, O., P.Fischer, Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted
Intervention (MICCAI). Volume 9351 of LNCS., Springer (2015) 234{241 (available
on arXiv:1505.04597 [cs.CV]).
23. Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., LeCun, Y.: Overfeat:
Integrated recognition, localization and detection using convolutional networks.
CoRR abs/1312.6229 (2013)
24. Huval, B., Wang, T., Tandon, S., Kiske, J., Song, W., Pazhayampallil, J., Andriluka, M., Rajpurkar, P., Migimatsu, T., Cheng-Yue, R., Mujica, F., Coates, A.,
Ng, A.Y.: An empirical evaluation of deep learning on highway driving. CoRR
abs/1504.01716 (2015)
25. Li, J., Mei, X., Prokhorov, D.V., Tao, D.: Deep neural network for structural
prediction and lane detection in traffic scene. IEEE Trans. Neural Netw. Learning
Syst. 28(3) (2017) 690{703
26. Kim, J., Park, C.: End-to-end ego lane estimation based on sequential transfer
learning for self-driving cars. In: 2017 IEEE Conference on Computer Vision and
Pattern Recognition Workshops, CVPR Workshops, Honolulu, HI, USA, July 21-
26, 2017. (2017) 1194{1202
27. Teichmann, M., Weber, M., Z¨ollner, J.M., Cipolla, R., Urtasun, R.: Multinet: Realtime joint semantic reasoning for autonomous driving. CoRR abs/1612.07695
(2016)
28. Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z.,
Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet Large
Scale Visual Recognition Challenge. International Journal of Computer Vision
(IJCV) 115(3) (2015) 211{252
29. Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale
image recognition. CoRR abs/1409.1556 (2014)
30. Hinton, G.E., Srivastava, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Improving neural networks by preventing co-adaptation of feature detectors. CoRR
abs/1207.0580 (2012) - 31. Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. CoRR
abs/1412.6980 (2014)
32. Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The KITTI
dataset. I. J. Robotics Res. 32(11) (2013) 1231{1237
33. Xingang Pan, Jianping Shi, P.L.X.W., Tang, X.: Spatial as deep: Spatial cnn for
traffic scene understanding. In: AAAI Conference on Artificial Intelligence (AAAI).
(February 2018)
34. Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado,
G.S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A.,
Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg,
J., Man´e, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J.,
Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V.,
Vi´egas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., Zheng,
X.: TensorFlow: Large-scale machine learning on heterogeneous systems (2015)
Software available from tensorflow.org.