B站弹幕文件protobuf协议的逆向和还原
目标是B站弹幕的数据还原,随便打开一个视频,直接三连
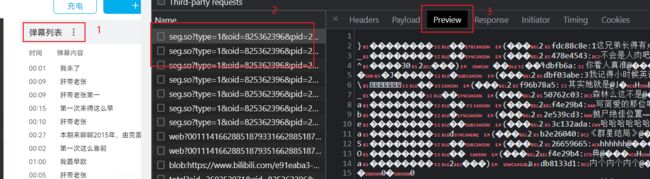
能看到真实文本,但也有一些乱码,看一下 content-type
content-type: application/octet-stream
参考这篇可知,这是一个字节流文件,但浏览器也不知道如何处理
算了,直接google 就可知,这是一个使用了protobuf协议编码 的文件,使用这种协议的好处就是数据量小,传输快,坏处也显而易见,就是使用麻烦!!!
配置和原理的话,跟着这两篇博客走就行,注意把 protoc.exe 配置到环境变量
- python简单使用protobuf
- Protobuf协议逆向解析-APP爬虫 - 猿人学
protobuf 初体验
然后可以写一个小demo玩一玩,首先是自定义 .proto文件
syntax = "proto3";
message Person {
string name = 1;
int32 age = 2;
string phone = 3;
string gender = 4;
}
然后编译生成python代码,目录下就多了一个 person_pb2.py
protoc --python_out=./ person.proto
然后就可以导入模块, import 的时候可能会报错:
ImportError: cannot import name 'builder' from 'google.protobuf.internal'
这时候需要升级:pip3 install --upgrade protobuf
In [4]: from person_pb2 import Person
In [5]: peron = Person()
In [7]: peron.name = "xxx"
In [8]: peron.age = 25
In [10]: send_bytes = peron.SerializeToString()
# 序列化
In [11]: send_bytes
Out[11]: b'\n\t\xe9\x99\x88\xe6\x99\x93\xe7\x94\x9f\x10\x19'
In [15]: decode_person = Person()
In [16]: decode_person.ParseFromString(send_bytes)
Out[16]: 13
# 反序列化
In [17]: decode_person
Out[17]:
name: "xxx"
age: 25
# 转换字典
from google.protobuf.json_format import MessageToDict
MessageToDict(decoder, preserving_proto_field_name=True)
so文件逆向
有了上面的经验,要来逆向就比较容易上手了,首先下载弹幕的二进制文件:
https://api.bilibili.com/x/v2/dm/web/seg.so?type=1&oid=555856394&pid=809421068&segment_index=2
然后运行命令:protoc --decode_raw < seg.so,先看一下大体内容是怎么样的:

再打断点调试看看:


直接搜索还原后的key值,midHash

格式化一下,答案呼之欲出:

这下可以开始编写 .proto文件了,把整个字典扣下来,用代码生成:
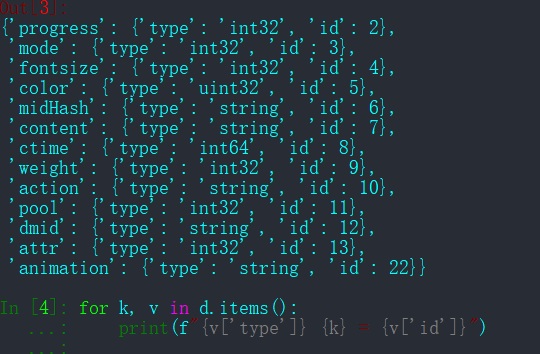
In [4]: for k, v in d.items():
...: print(f"{v['type']} {k} = {v['id']}")
bili.proto 文件如下:
syntax = "proto3";
// 弹幕的数据是放在一个key的大value里,所以需要嵌套多一层
// 字段不需要和 decode_raw 解析出来的完全一致
message BiliDanmu {
message Message {
int32 progress = 2;
int32 mode = 3;
int32 fontsize = 4;
uint32 color = 5;
string midHash = 6;
string content = 7;
int64 ctime = 8;
int32 weight = 9;
string action = 10;
int32 pool = 11;
string dmid = 12;
int32 attr = 13;
string animation = 22;
}
repeated Message message = 1;
}
再走一遍上面的流程:
-
生成 pb2.py 文件
protoc --python_out=./ bili.proto -
导入模块
from bili_pb2 import BiliDanmu -
解析字节流
In [2]: bili_decoder = BiliDanmu() In [3]: pb_bytes = open("seg.so", "rb").read() In [4]: bili_decoder.ParseFromString(pb_bytes) -
转换成字典
from google.protobuf.json_format import MessageToDict MessageToDict(bili_decoder, preserving_proto_field_name=True)
后记
不得不说,protobuf用起来真是麻烦,不过亲自跑了一遍流程,还是挺有成就感的