核函数+支持向量机+SMO算法详解
核函数
一、核心思想
在前面我们所讨论的分类器中,基本都是线性分类器,但是当数据集不存在一个线性的决策边界时,线性分类器便无法很好得进行分类。
事实证明,有一种优雅的方法可以将非线性问题合并到大多数的线性分类器可解决的问题中,即将线性分类器非线性化,这便是核函数。
我们可以看一个经典的例子:如下图所示的数据集,显然它是不存在线性的决策边界的,但是我们可以通过函数 ϕ ~\phi~ ϕ 对特征向量进行特征变换使得数据线性可分。

我们不妨将特征变换函数定义为:
ϕ ( x ) = ϕ ( [ x 1 , x 2 ] T ) = [ x 1 , x 2 , ∣ x 1 ⋅ x 2 ∣ ] T \phi(x)=\phi([x_1,x_2]^T)=[x_1,x_2,|x_1\cdot x_2|]^T ϕ(x)=ϕ([x1,x2]T)=[x1,x2,∣x1⋅x2∣]T
我们所添加的维度捕捉了原始特征之间的非线性交互,使得数据变为了线性可分,升维的方法较为简便,并且使得问题保持凸且表现良好,但是缺点是升维可能会导致维度过高,使得模型变得复杂,比如下面这个例子所示:

通过特征变换,维度从 d ~d~ d 维变为了 2 d ~2^d~ 2d 维,这种新的表示法 ϕ ( x ) ~\phi(x)~ ϕ(x) 非常有表现力,允许复杂的非线性决策边界,但维数非常高。这使得我们的算法速度慢得令人无法忍受。
二、核技巧
核技巧是一种通过在更高维空间中学习函数来绕过这一困境的方法,而无需计算单个向量 ϕ ( x ) ~\phi(x)~ ϕ(x) 或完整向量 w ~w~ w 。
2.1 梯度下降
我们考虑平方损失函数的梯度下降过程:
l ( w ) = ∑ i = 1 n ( w T x i − y i ) 2 l(w)=\sum_{i=1}^n(w^Tx_i-y_i)^2 l(w)=i=1∑n(wTxi−yi)2
在梯度下降过程中,我们每次需要选择一个步长进行更新:
w t + 1 = w t − s ⋅ ( ∂ l ( w ) ∂ w ) ∂ l ( w ) ∂ w = 2 ∑ i = 1 n ( w T x i − y i ) ⋅ x i w_{t+1}=w_{t}-s\cdot(\frac{\partial l(w)}{\partial w})\\ \frac{\partial l(w)}{\partial w}=2\sum_{i=1}^n(w^Tx_i-y_i)\cdot x_i wt+1=wt−s⋅(∂w∂l(w))∂w∂l(w)=2i=1∑n(wTxi−yi)⋅xi
此处我们要引入一个重要的假设:我们可以将参数 w ~w~ w 表示为特征向量 x i ~x_i~ xi 的线性组合:
w = ∑ i = 1 n α i x i w=\sum_{i=1}^n\alpha_ix_i w=i=1∑nαixi
根据该假设我们可以得到: w t + 1 ~w_{t+1}~ wt+1 与 x i ~x_i~ xi 线性相关, w t ~w_t~ wt 与 x i ~x_i~ xi 线性相关,由此:梯度 ∂ l ( w ) ∂ w ~\frac{\partial l(w)}{\partial w}~ ∂w∂l(w) 与 x i ~x_i~ xi 线性相关:
∂ l ( w ) ∂ w = 2 ∑ i = 1 n ( w T x i − y i ) ⋅ x i = ∑ i = 1 n γ i x i \frac{\partial l(w)}{\partial w}=2\sum_{i=1}^n(w^Tx_i-y_i)\cdot x_i=\sum_{i=1}^n\gamma_ix_i ∂w∂l(w)=2i=1∑n(wTxi−yi)⋅xi=i=1∑nγixi
由于损失函数为凸函数,最终解与初始化无关我们可以将 w 0 ~w_0~ w0 初始化为我们想要的任何值,我们不妨令:
w 0 = [ 0 , 0 , . . . , 0 ] T , α 0 = [ 0 , 0 , . . . , 0 ] T w_0=[0,0,...,0]^T,\alpha^0=[0,0,...,0]^T w0=[0,0,...,0]T,α0=[0,0,...,0]T
根据上述分析我们可以得到梯度下降的过程为:
w 1 = w 0 − s ⋅ 2 ∑ i = 1 n ( w 0 T x i − y i ) x i = ∑ i = 1 n α i 0 x i − s ∑ i = 1 n γ i 0 x i = ∑ i = 1 n α i 1 x i α 1 = α 0 − s γ 0 w 2 = w 1 − s ⋅ 2 ∑ i = 1 n ( w 1 T x i − y i ) x i = ∑ i = 1 n α i 1 x i − s ∑ i = 1 n γ i 1 x i = ∑ i = 1 n α i 2 x i α 2 = α 1 − s γ 1 w 3 = w 2 − s ⋅ 2 ∑ i = 1 n ( w 2 T x i − y i ) x i = ∑ i = 1 n α i 2 x i − s ∑ i = 1 n γ i 2 x i = ∑ i = 1 n α i 2 x i α 3 = α 2 − s γ 2 . . . w t = w t − 1 − s ⋅ 2 ∑ i = 1 n ( w t − 1 T x i − y i ) x i = ∑ i = 1 n α i t − 1 x i − s ∑ i = 1 n γ i t − 1 x i = ∑ i = 1 n α i t x i α t = α t − 1 − s γ t − 1 \begin{aligned} &w_1=w_0-s\cdot2\sum_{i=1}^n(w_0^Tx_i-y_i)x_i=\sum_{i=1}^n\alpha_i^0x_i-s\sum_{i=1}^n\gamma_i^0x_i=\sum_{i=1}^n\alpha_i^1x_i~~~~\alpha^1=\alpha^0-s\gamma^0\\ &w_2=w_1-s\cdot2\sum_{i=1}^n(w_1^Tx_i-y_i)x_i=\sum_{i=1}^n\alpha_i^1x_i-s\sum_{i=1}^n\gamma_i^1x_i=\sum_{i=1}^n\alpha_i^2x_i~~~~\alpha^2=\alpha^1-s\gamma^1\\ &w_3=w_2-s\cdot2\sum_{i=1}^n(w_2^Tx_i-y_i)x_i=\sum_{i=1}^n\alpha_i^2x_i-s\sum_{i=1}^n\gamma_i^2x_i=\sum_{i=1}^n\alpha_i^2x_i~~~~\alpha^3=\alpha^2-s\gamma^2\\ &...\\ &w_t=w_{t-1}-s\cdot2\sum_{i=1}^n(w_{t-1}^Tx_i-y_i)x_i=\sum_{i=1}^n\alpha_i^{t-1}x_i-s\sum_{i=1}^n\gamma_i^{t-1}x_i=\sum_{i=1}^n\alpha_i^tx_i~~~~\alpha^t=\alpha^{t-1}-s\gamma^{t-1}\\ \end{aligned} w1=w0−s⋅2i=1∑n(w0Txi−yi)xi=i=1∑nαi0xi−si=1∑nγi0xi=i=1∑nαi1xi α1=α0−sγ0w2=w1−s⋅2i=1∑n(w1Txi−yi)xi=i=1∑nαi1xi−si=1∑nγi1xi=i=1∑nαi2xi α2=α1−sγ1w3=w2−s⋅2i=1∑n(w2Txi−yi)xi=i=1∑nαi2xi−si=1∑nγi2xi=i=1∑nαi2xi α3=α2−sγ2...wt=wt−1−s⋅2i=1∑n(wt−1Txi−yi)xi=i=1∑nαit−1xi−si=1∑nγit−1xi=i=1∑nαitxi αt=αt−1−sγt−1
因为 α i 0 = 0 ~\alpha^0_i=0~ αi0=0 ,则有:
α i 1 = 0 − s γ i 0 = − s γ i 0 α i 2 = α i 1 − s γ 0 1 = − s γ i 0 − s γ i 1 α i 3 = α i 2 − s γ i 2 = − s γ i 0 − s γ i 1 − s γ i 2 . . . α i t = α i t − 1 − s γ i t − 1 = − s ∑ r = 1 t − 1 γ i r \begin{aligned} &\alpha^1_i=~0~-s\gamma^0_i=-s\gamma^0_i\\ &\alpha^2_i=\alpha^1_i-s\gamma^1_0=-s\gamma^0_i-s\gamma^1_i\\ &\alpha^3_i=\alpha_i^2-s\gamma^2_i=-s\gamma^0_i-s\gamma^1_i-s\gamma^2_i\\ &...\\ &\alpha^t_i=\alpha_i^{t-1}-s\gamma^{t-1}_i=-s\sum_{r=1}^{t-1}\gamma_i^r \end{aligned} αi1= 0 −sγi0=−sγi0αi2=αi1−sγ01=−sγi0−sγi1αi3=αi2−sγi2=−sγi0−sγi1−sγi2...αit=αit−1−sγit−1=−sr=1∑t−1γir
我们用 x i ~x_i~ xi 的线性组合代替 w ~w~ w ,得到新的模型和损失函数:
h ( x i ) = w t T x i = ∑ j = 1 n α j t x j T x i l ( w ) = ∑ i = 1 n ( w t T x i − y i ) 2 = ∑ i = 1 n ( ∑ j = 1 n α j t x j T x i − y i ) 2 h(x_i)=w_t^Tx_i=\sum_{j=1}^n\alpha_j^tx_j^Tx_i\\ l(w)=\sum_{i=1}^n(w^T_tx_i-y_i)^2=\sum_{i=1}^n(\sum_{j=1}^n\alpha_j^tx_j^Tx_i-y_i)^2 h(xi)=wtTxi=j=1∑nαjtxjTxil(w)=i=1∑n(wtTxi−yi)2=i=1∑n(j=1∑nαjtxjTxi−yi)2
由此我们可以发现:为了学习具有平方损失的超平面分类器,我们需要的唯一信息是所有数据的特征向量对之间的内积。
2.2 计算内积
有了上述推导,我们将模型简化为只需要求解向量对之间的内积,我们回归到上述的升维操作中去:
在升维之后,内积的计算公式为:
ϕ ( x ) T ϕ ( z ) = 1 + x 1 z 1 + x 2 z 2 + . . . x 1 x 2 . . . x d z 1 z 2 . . . z d = ∏ k = 1 d ( 1 + x k z k ) \phi(x)^T\phi(z)=1+x_1z_1+x_2z_2+...x_1x_2...x_dz_1z_2...z_d=\prod_{k=1}^d(1+x_kz_k) ϕ(x)Tϕ(z)=1+x1z1+x2z2+...x1x2...xdz1z2...zd=k=1∏d(1+xkzk)
我们可以发现,尽管特征向量是 2 d ~2^d~ 2d 维的,但是计算其内积仅需要 d ~d~ d 次乘法运算,这极大提高了算法的速度。
我们由此即可定义核函数:
k ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) k(x_i,x_j)=\phi(x_i)^T\phi(x_j) k(xi,xj)=ϕ(xi)Tϕ(xj)
核函数计算出的结果存储在核矩阵中:
K i j = ϕ ( x i ) T ϕ ( x j ) K_{ij}=\phi(x_i)^T\phi(x_j) Kij=ϕ(xi)Tϕ(xj)
诸如 ϕ ~\phi~ ϕ 之类的用于升维的映射并不好找,因此我们用核函数 k ( x i , x j ) ~k(x_i,x_j)~ k(xi,xj) 去代替这样的映射,处理线性不可分问题。
则上述模型可以表示为:可以发现模型中唯一的未知参数即为 α ~\alpha~ α ,我们需要对它进行求解
h ( x i ) = w T x i = ∑ j = 1 n α j x j T x i = ∑ j = 1 n α j k ( x j , x i ) h(x_i)=w^Tx_i=\sum_{j=1}^n\alpha_jx_j^Tx_i=\sum_{j=1}^n\alpha_jk(x_j,x_i) h(xi)=wTxi=j=1∑nαjxjTxi=j=1∑nαjk(xj,xi)
同时我们也已经得到了:
α i t = − s ∑ r = 1 t − 1 γ i r \alpha^t_i=-s\sum_{r=1}^{t-1}\gamma_i^r αit=−sr=1∑t−1γir
所以当下我们的求解目标变为了 γ ~\gamma~ γ :
∂ l ( w ) ∂ w = 2 ∑ i = 1 n ( w T x i − y i ) ⋅ x i = ∑ i = 1 n γ i x i γ i = 2 ( w T x i − y i ) \frac{\partial l(w)}{\partial w}=2\sum_{i=1}^n(w^Tx_i-y_i)\cdot x_i=\sum_{i=1}^n\gamma_ix_i\\ \gamma_i=2(w^Tx_i-y_i) ∂w∂l(w)=2i=1∑n(wTxi−yi)⋅xi=i=1∑nγixiγi=2(wTxi−yi)
在经过 ϕ ~\phi~ ϕ 特征变换的新的高维空间中有:
γ i = 2 ( w T ϕ ( x i ) − y i ) = 2 ( ∑ j = 1 n α j k ( x j , x i ) − y i ) \gamma_i=2(w^T\phi(x_i)-y_i)=2(\sum_{j=1}^n\alpha_jk(x_j,x_i)-y_i) γi=2(wTϕ(xi)−yi)=2(j=1∑nαjk(xj,xi)−yi)
则梯度下降的过程为:
α i t + 1 = α i t − s γ i t = α i t − 2 s ( ∑ j = 1 n α j t k ( x j , x i ) − y i ) \alpha_i^{t+1}=\alpha_i^t-s\gamma_i^t=\alpha_i^t-2s(\sum_{j=1}^n\alpha_j^tk(x_j,x_i)-y_i) αit+1=αit−sγit=αit−2s(j=1∑nαjtk(xj,xi)−yi)
梯度下降过程中,每次更新 α ~\alpha~ α 的计算量为 O ( n 2 ) ~O(n^2)~ O(n2) ,远好于 O ( 2 d ) ~O(2^d)~ O(2d)
三、一般核函数
3.1 常用核函数
(1)线性核函数:
K ( x , z ) = x T z K(x,z)=x^Tz K(x,z)=xTz
(2)多项式核函数:
K ( x , z ) = ( 1 + x T z ) d K(x,z)=(1+x^Tz)^d K(x,z)=(1+xTz)d
(3)高斯核函数( RBF \text{RBF} RBF):
K ( x , z ) = e − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 K(x,z)=e^{-\frac{||x-z||_2^2}{\sigma^2}} K(x,z)=e−σ2∣∣x−z∣∣22
(4)指数核函数:
K ( x , z ) = e − ∣ ∣ x − z ∣ ∣ 2 σ 2 K(x,z)=e^{-\frac{||x-z||}{2\sigma^2}} K(x,z)=e−2σ2∣∣x−z∣∣
(5)拉普拉斯核函数:
K ( x , z ) = e − ∣ x − z ∣ σ K(x,z)=e^{-\frac{|x-z|}{\sigma}} K(x,z)=e−σ∣x−z∣
(6) Sigmoid \text{Sigmoid} Sigmoid核函数: tanh ( x ) = e x − e − x e x + e − x ~\tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}~ tanh(x)=ex+e−xex−e−x
K ( x , z ) = tanh ( γ x T z + r ) K(x,z)=\tanh(\gamma x^Tz+r) K(x,z)=tanh(γxTz+r)
3.2 良定义核函数
良定义的核函数定义如下:通过递归组合以下一个或多个规则构建的核称为定义良好的核:
① k ( x , z ) = x T z ② k ( x , z ) = c k 1 ( x , z ) ③ k ( x , z ) = k 1 ( x , z ) + k 2 ( x , z ) ④ k ( x , z ) = g ( k ( x , z ) ) ⑤ k ( x , z ) = k 1 ( x , z ) ⋅ k 2 ( x , z ) ⑥ k ( x , z ) = f ( x ) k 1 ( x , z ) f ( z ) ⑦ k ( x , z ) = e k 1 ( x , z ) ⑧ k ( x , z ) = x T A z \begin{aligned} &①~k(x,z)=x^Tz\\ &②~k(x,z)=ck_1(x,z)\\ &③~k(x,z)=k_1(x,z)+k_2(x,z)\\ &④~k(x,z)=g\big(k(x,z)\big)\\ &⑤~k(x,z)=k_1(x,z)\cdot k_2(x,z)\\ &⑥~k(x,z)=f(x)k_1(x,z)f(z)\\ &⑦~k(x,z)=e^{k_1(x,z)}\\ &⑧~k(x,z)=x^TAz \end{aligned} ① k(x,z)=xTz② k(x,z)=ck1(x,z)③ k(x,z)=k1(x,z)+k2(x,z)④ k(x,z)=g(k(x,z))⑤ k(x,z)=k1(x,z)⋅k2(x,z)⑥ k(x,z)=f(x)k1(x,z)f(z)⑦ k(x,z)=ek1(x,z)⑧ k(x,z)=xTAz
上述规则中 k 1 ( x , z ) ~k_1(x,z)~ k1(x,z) 和 k 2 ( x , z ) ~k_2(x,z)~ k2(x,z) 都是良定义的核函数, c ≥ 0 ~c\ge0~ c≥0 , g ~g~ g 是一个正系数多项式函数, f ~f~ f 是任何函数, A ~A~ A 是半正定的
某个核函数是良定义的等价为:
①核矩阵 K ~K~ K 的特征值都是非负的
②存在实矩阵 P ~P~ P 使得: K = P T P ~K=P^TP~ K=PTP
③核矩阵 K ~K~ K 是半正定的,即对于任何向量 x ~x~ x ,都有: x T K x ≥ 0 ~x^TKx\ge0~ xTKx≥0
定理 3-1
RBF核函数: k ( x , z ) = e − ( x − z ) 2 σ 2 是良定义的 \text{RBF}核函数:k(x,z)=e^{-\frac{(x-z)^2}{\sigma^2}}是良定义的 RBF核函数:k(x,z)=e−σ2(x−z)2是良定义的
证明如下:
k ( x , z ) = e − ( x − z ) 2 σ 2 = e − 1 σ 2 ( x T x − 2 x T z + z T z ) = e − x T x σ 2 ⋅ e 2 x T z σ 2 ⋅ e − x T x σ 2 \begin{aligned} &k(x,z)=e^{-\frac{(x-z)^2}{\sigma^2}}=e^{-\frac1{\sigma^2}(x^Tx-2x^Tz+z^Tz)}=e^{-\frac{x^Tx}{\sigma^2}}\cdot e^{\frac{2x^Tz}{\sigma^2}}\cdot e^{-\frac{x^Tx}{\sigma^2}} \end{aligned} k(x,z)=e−σ2(x−z)2=e−σ21(xTx−2xTz+zTz)=e−σ2xTx⋅eσ22xTz⋅e−σ2xTx
根据规则⑥: f ( x ) = e − x T x σ 2 , k 1 ( x , z ) = e 2 x T z σ 2 → k ( x , z ) = f ( x ) ⋅ k 1 ( x , z ) ⋅ f ( z ) 根据规则⑦: k 2 ( x , z ) = 2 x T z σ 2 → k 1 ( x , z ) = e k 2 ( x , z ) 根据规则②: k 3 ( x , z ) = x T z , c = 2 x T z σ 2 → k 2 ( x , z ) = c ⋅ k 3 ( x , z ) 根据规则①: k 3 ( x , z ) is well defined → k 2 ( x , z ) is well defined → k 1 ( x , z ) is well defined \begin{aligned} &根据规则⑥:f(x)=e^{-\frac{x^Tx}{\sigma^2}},k_1(x,z)=e^{\frac{2x^Tz}{\sigma^2}}\rightarrow k(x,z)=f(x)\cdot k_1(x,z)\cdot f(z)\\ &根据规则⑦:k_2(x,z)=\frac{2x^Tz}{\sigma^2}\rightarrow k_1(x,z)=e^{k_2(x,z)}\\ &根据规则②:k_3(x,z)=x^Tz,c=\frac{2x^Tz}{\sigma^2}\rightarrow k_2(x,z)=c\cdot k_3(x,z)\\ &根据规则①:k_3(x,z)\text{ is well defined}\rightarrow k_2(x,z)\text{ is well defined}\rightarrow k_1(x,z)\text{ is well defined}\\ \end{aligned} 根据规则⑥:f(x)=e−σ2xTx,k1(x,z)=eσ22xTz→k(x,z)=f(x)⋅k1(x,z)⋅f(z)根据规则⑦:k2(x,z)=σ22xTz→k1(x,z)=ek2(x,z)根据规则②:k3(x,z)=xTz,c=σ22xTz→k2(x,z)=c⋅k3(x,z)根据规则①:k3(x,z) is well defined→k2(x,z) is well defined→k1(x,z) is well defined
综上推导:
k ( x , z ) is well defined k(x,z)\text{ is well defined} k(x,z) is well defined
定理 3-2
S 1 , S 2 ∈ Ω , k ( S 1 , S 2 ) = e ∣ S 1 ∩ S 2 ∣ 是良定义的 S_1,S_2\in \Omega,k(S_1,S_2)=e^{|S_1\cap S_2|}是良定义的 S1,S2∈Ω,k(S1,S2)=e∣S1∩S2∣是良定义的
证明如下:
将 Ω ~\Omega~ Ω 中所有可能的元素排列成一个列表, S 1 , S 2 S_1,S_2 S1,S2分别用一个大小为 ∣ Ω ∣ ~|\Omega|~ ∣Ω∣ 的向量 x S 1 , x S 2 ~x^{S_1},x^{S_2}~ xS1,xS2 表示,如果 Ω ~\Omega~ Ω 中的第 i ~i~ i 个元素属于 S ~S~ S ,则 x i S = 1 ~x^{S}_i=1~ xiS=1 ,反之则 x i S = 0 ~x^{S}_i=0~ xiS=0 ,则上述核函数可以表示为:
k ( S 1 , S 2 ) = e x S 1 T x S 2 \begin{aligned} &k(S_1,S_2)=e^{x_{S_1}^Tx_{S_2}} \end{aligned} k(S1,S2)=exS1TxS2
根据规则⑦和规则①,我们可以得到: k ( S 1 , S 2 ) ~k(S_1,S_2)~ k(S1,S2) 为良定义核函数。
四、模型核化
一个算法可以通过三步实现核化:
①证明解决方案位于训练点的范围内,即对于某些 α i ~\alpha_i~ αi :
w = ∑ i = 1 n α i x i w=\sum_{i=1}^n\alpha_ix_i w=i=1∑nαixi
②重构算法与分类器,使得输入的特征向量仅用于内积的计算
③将内积替换为核函数:
x i T x j → ϕ ( x i ) T ϕ ( x j ) x_i^Tx_j\rightarrow\phi(x_i)^T\phi(x_j) xiTxj→ϕ(xi)Tϕ(xj)
4.1 线性回归核化
我们回顾一下普通的最小二乘回归 O L S ~OLS~ OLS :
l ( w ) = ∑ i = 1 n ( x i T w − y i ) w ^ M L E = a r g m i n w ∑ i = 1 n ( x i T w − y i ) h ( x ) = w T x l(w)=\sum_{i=1}^n(x_i^Tw-y_i)\\ \hat{w}_{MLE}=\underset{w}{argmin}~\sum_{i=1}^n(x_i^Tw-y_i)\\ h(x)=w^Tx l(w)=i=1∑n(xiTw−yi)w^MLE=wargmin i=1∑n(xiTw−yi)h(x)=wTx
输入的训练集为 X ~X~ X 和 Y ~Y~ Y ,则其闭合形式为:
w = ( X T X ) − 1 X T Y w=(X^TX)^{-1}X^TY w=(XTX)−1XTY
我们对该模型进行核化: X ~X~ X 为 n × d ~n\times d~ n×d 维矩阵, Y ~Y~ Y 为 n × 1 ~n\times1~ n×1 维矩阵, w , x i ~w,x_i~ w,xi 为 d × 1 ~d\times1~ d×1 维矩阵, α ~\alpha~ α 为 n × 1 ~n\times1~ n×1 维矩阵
①将 w ~w~ w 表示为 x i ~x_i~ xi 的线性组合: α = [ α 1 , α 2 , . . . , α n ] T ~\alpha=[~\alpha_1,\alpha_2,...,\alpha_n~]^T~ α=[ α1,α2,...,αn ]T
w = ∑ i = 1 n α i x i = X T α \begin{aligned} &w=\sum_{i=1}^n\alpha_ix_i=X^T\alpha \end{aligned} w=i=1∑nαixi=XTα
②将模型修正为输入特征向量的内积:
h ( x i ) = ∑ j = 1 n α j x j T x i = w T x i = α T X x i h(x_i)=\sum_{j=1}^n\alpha_jx_j^Tx_i=w^Tx_i=\alpha^TXx_i h(xi)=j=1∑nαjxjTxi=wTxi=αTXxi
③用核函数代替内积:
h ( x i ) = ∑ j = 1 n α j k ( x j , x i ) h(x_i)=\sum_{j=1}^n\alpha_jk(x_j,x_i) h(xi)=j=1∑nαjk(xj,xi)
求解 α ~\alpha~ α 的闭合形式:
w = X T α = ( X T X ) − 1 X T Y → X T X X T α = X T Y → X X T α = Y K i j = k ( x i , x j ) → K = X X T → K α = Y α = K − 1 Y \begin{aligned} &w=X^T\alpha=(X^TX)^{-1}X^TY\rightarrow X^TXX^T\alpha=X^TY\rightarrow XX^T\alpha=Y\\ &K_{ij}=k(x_i,x_j)\rightarrow K=XX^T\rightarrow K\alpha=Y\\ &\alpha=K^{-1}Y \end{aligned} w=XTα=(XTX)−1XTY→XTXXTα=XTY→XXTα=YKij=k(xi,xj)→K=XXT→Kα=Yα=K−1Y
岭回归同理,我们也可以实现同样的核化并求解 α ~\alpha~ α 的闭合形式:
模型为:
l ( w ) = ∑ i = 1 n ( x i T w − y i ) + λ ∣ ∣ w ∣ ∣ 2 2 w ^ M A P = a r g m i n w ∑ i = 1 n ( x i T w − y i ) + λ ∣ ∣ w ∣ ∣ 2 2 h ( x ) = ∑ j = 1 n α j k ( x j , x i ) l(w)=\sum_{i=1}^n(x_i^Tw-y_i)+\lambda||w||_2^2\\ \hat{w}_{MAP}=\underset{w}{argmin}~\sum_{i=1}^n(x_i^Tw-y_i)+\lambda||w||_2^2\\ h(x)=\sum_{j=1}^n\alpha_jk(x_j,x_i) l(w)=i=1∑n(xiTw−yi)+λ∣∣w∣∣22w^MAP=wargmin i=1∑n(xiTw−yi)+λ∣∣w∣∣22h(x)=j=1∑nαjk(xj,xi)
α ~\alpha~ α 的闭合形式为:
w = X T α = ( X T X + λ I ) − 1 X T Y → ( X T X + λ I ) X T α = X T Y → ( X T X X T + λ X T ) α = X T Y → ( X X T + λ I ) α = Y → α = ( K + λ I ) − 1 Y \begin{aligned} &w=X^T\alpha=(X^TX+\lambda I)^{-1}X^TY\rightarrow (X^TX+\lambda I)X^T\alpha=X^TY\\ &\rightarrow (X^TXX^T+\lambda X^T)\alpha=X^TY\rightarrow (XX^T+\lambda I)\alpha=Y\\ &\rightarrow \alpha=(K+\lambda I)^{-1}Y \end{aligned} w=XTα=(XTX+λI)−1XTY→(XTX+λI)XTα=XTY→(XTXXT+λXT)α=XTY→(XXT+λI)α=Y→α=(K+λI)−1Y
4.2 KNN核化
我们以欧拉距离的 K N N ~KNN~ KNN 模型为例:
dist ( x i , x j ) = ( x i − x j ) T ( x i − x j ) = x i T x i − 2 x i T x j + x j T x j = k ( x i , x i ) − 2 k ( x i , x j ) + k ( x j , x j ) \text{dist}(x_i,x_j)=(x_i-x_j)^T(x_i-x_j)=x_i^Tx_i-2x_i^Tx_j+x_j^Tx_j=k(x_i,x_i)-2k(x_i,x_j)+k(x_j,x_j) dist(xi,xj)=(xi−xj)T(xi−xj)=xiTxi−2xiTxj+xjTxj=k(xi,xi)−2k(xi,xj)+k(xj,xj)
但是上述核化的意义并不大,因此我们一般不对 K N N ~KNN~ KNN 算法进行核化。
4.3 支持向量机核化
线性支持向量机结合核函数是一个很强大的模型,我们往往求解其对偶问题,所以我们需要先了解对偶问题的定义。
4.3.1 拉格朗日乘子法与KKT条件
在求解最优化问题中,拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush Kuhn Tucker)条件是两种最常用的方法。在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件。
我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值,支持向量机模型即为该类最优化为问题。
在求解最优化问题时一般会遇到三种情况:
(1)无约束条件:
这是最简单的情况,解决方法通常是函数对变量求导,令求导函数等于0的点可能是极值点。将结果带回原函数进行验证即可。
(2)等式约束条件:
设目标函数为 f ( x ) ~f(x)~ f(x) ,约束条件为 h k ( x ) ~h_k(x)~ hk(x) ,有 l ~l~ l 个约束条件,则等式约束条件的最优化问题可以表示为:
求解目标: min f ( x ) 约束条件: h k ( x ) = 0 , k = 1 , 2 , . . . l \begin{aligned} &求解目标:\min f(x)\\ &约束条件:h_k(x)=0,k=1,2,...l \end{aligned} 求解目标:minf(x)约束条件:hk(x)=0,k=1,2,...l
我们要用到拉格朗日乘子法处理该最优化问题:首先定义拉格朗日函数:
F ( x . λ ) = f ( x ) + ∑ k = 1 l λ k h k ( x ) F(x.\lambda)=f(x)+\sum_{k=1}^l\lambda_kh_k(x) F(x.λ)=f(x)+k=1∑lλkhk(x)
然后解变量的偏导方程:
∂ F ( x , λ ) ∂ x 1 = 0 , ∂ F ( x , λ ) ∂ x 2 = 0 , . . . , ∂ F ( x , λ ) ∂ x d = 0 ∂ F ( x , λ ) ∂ λ 1 = 0 , ∂ F ( x , λ ) ∂ λ 2 = 0 , . . . , ∂ F ( x , λ ) ∂ λ k = 0 \frac{\partial F(x,\lambda)}{\partial x_1}=0,\frac{\partial F(x,\lambda)}{\partial x_2}=0,...,\frac{\partial F(x,\lambda)}{\partial x_d}=0\\ \frac{\partial F(x,\lambda)}{\partial \lambda_1}=0,\frac{\partial F(x,\lambda)}{\partial \lambda_2}=0,...,\frac{\partial F(x,\lambda)}{\partial \lambda_k}=0 ∂x1∂F(x,λ)=0,∂x2∂F(x,λ)=0,...,∂xd∂F(x,λ)=0∂λ1∂F(x,λ)=0,∂λ2∂F(x,λ)=0,...,∂λk∂F(x,λ)=0
(3)不等式约束条件:
设目标函数为 f ( x ) ~f(x)~ f(x) ,不等式约束条件为 g k ( x ) ~g_k(x)~ gk(x) ,有 q ~q~ q 个不等式约束条件,等式约束条件为 h j ( k ) ~h_j(k)~ hj(k) ,有 p ~p~ p 个等式约束条件:
求解目标: min f ( x ) 约束条件: h j ( x ) = 0 , j = 1 , 2 , . . . , p g k ( x ) ≤ 0 , k = 1 , 2 , . . . , q \begin{aligned} &求解目标:\min f(x)\\ &约束条件:h_j(x)=0,j=1,2,...,p\\ &~~~~~~~~~~~~~~~~~g_k(x)\le0,k=1,2,...,q \end{aligned} 求解目标:minf(x)约束条件:hj(x)=0,j=1,2,...,p gk(x)≤0,k=1,2,...,q
则我们可以定义不等式约束条件下的拉格朗日函数为:
L ( x , λ , μ ) = f ( x ) + ∑ j = 1 p λ j h j ( x ) + ∑ k = 1 q μ k g k ( x ) L(x,\lambda,\mu)=f(x)+\sum_{j=1}^p\lambda_jh_j(x)+\sum_{k=1}^q\mu_kg_k(x) L(x,λ,μ)=f(x)+j=1∑pλjhj(x)+k=1∑qμkgk(x)
常用的方法是 K K T ~KKT~ KKT 条件:即最优值(局部最小值)必须满足以下条件:
① ∂ L ( x , λ , μ ) ∂ x ∣ x = x ∗ = 0 ② h j ( x ∗ ) = 0 ③ μ k g k ( x ∗ ) = 0 \begin{aligned} &①~\frac{\partial L(x,\lambda,\mu)}{\partial x}|_{x=x^*}=0\\ &②~h_j(x^*)=0\\ &③~\mu_kg_k(x^*)=0 \end{aligned} ① ∂x∂L(x,λ,μ)∣x=x∗=0② hj(x∗)=0③ μkgk(x∗)=0
4.3.2 对偶问题的核化
我们首先回顾支持向量机的模型:为了便于计算我们引入一个常系数 1 2 ~\frac12~ 21
求解目标: ( w , b ) = a r g m i n w , b 1 2 ∣ ∣ w ∣ ∣ 2 2 约束条件: ∀ i , y i ( w T x i + b ) ≥ 1 \begin{aligned} &求解目标:(w,b)=\underset{w,b}{argmin}~\frac12||w||^2_2\\ &约束条件:\forall i~,~y_i(w^Tx_i+b)\ge 1 \end{aligned} 求解目标:(w,b)=w,bargmin 21∣∣w∣∣22约束条件:∀i , yi(wTxi+b)≥1
则拉格朗日函数为:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 + ∑ i = 1 n α i ( 1 − y i ( w T x i + b ) ) L(w,b,\alpha)=\frac12||w||_2^2+\sum_{i=1}^n\alpha_i\big(1-y_i(w^Tx_i+b)\big) L(w,b,α)=21∣∣w∣∣22+i=1∑nαi(1−yi(wTxi+b))
根据 K K T ~KKT~ KKT 条件可得:
∂ L ( w , b , α ) ∂ w = w − ∑ i = 1 n α i y i x i = 0 ∂ L ( w , b , α ) ∂ b = − ∑ i = 1 n α i y i = 0 \begin{aligned} &\frac{\partial L(w,b,\alpha)}{\partial w}=w-\sum_{i=1}^n\alpha_iy_ix_i=0\\ &\frac{\partial L(w,b,\alpha)}{\partial b}=-\sum_{i=1}^n\alpha_i y_i=0 \end{aligned} ∂w∂L(w,b,α)=w−i=1∑nαiyixi=0∂b∂L(w,b,α)=−i=1∑nαiyi=0
我们同时也知道,在 w , b ~w,b~ w,b 取得最优值时有: y i ( w T x i + b ) = 1 ~y_i(w^Tx_i+b)=1~ yi(wTxi+b)=1 满足了 K K T ~KKT~ KKT 条件
综上,我们可得:
w = ∑ i = 1 n α i y i x i ∑ i = 1 n α i y i = 0 \begin{aligned} &w=\sum_{i=1}^n\alpha_iy_ix_i\\ &\sum_{i=1}^n\alpha_iy_i=0 \end{aligned} w=i=1∑nαiyixii=1∑nαiyi=0
我们上述条件代入原式可得:
( w , b ) = a r g m i n w , b 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j + ∑ i = 1 n α i − ∑ i = 1 n ∑ j = 1 n α i y i y j x i T x j − b ⋅ ∑ i = 1 n α i y i → ( w , b ) = a r g m i n w , b ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j \begin{aligned} &(w,b)=\underset{w,b}{argmin}~\frac12\sum_{i=1}^n\sum_{j=1}^n\alpha_i\alpha_jy_iy_jx_i^Tx_j+\sum_{i=1}^n\alpha_i-\sum_{i=1}^n\sum_{j=1}^n\alpha_iy_iy_jx_i^Tx_j-b\cdot\sum_{i=1}^n\alpha_iy_i\\ &\rightarrow(w,b)=\underset{w,b}{argmin}~\sum_{i=1}^n\alpha_i-\frac12\sum_{i=1}^n\sum_{j=1}^n\alpha_i\alpha_jy_iy_jx_i^Tx_j \end{aligned} (w,b)=w,bargmin 21i=1∑nj=1∑nαiαjyiyjxiTxj+i=1∑nαi−i=1∑nj=1∑nαiyiyjxiTxj−b⋅i=1∑nαiyi→(w,b)=w,bargmin i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxj
由此我们得到了支持向量机模型的对偶问题:
求解目标: α = a r g m a x α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j 约束条件: ∑ i = 1 n α i y i = 0 \begin{aligned} &求解目标:\alpha=\underset{\alpha}{argmax}~\sum_{i=1}^n\alpha_i-\frac12\sum_{i=1}^n\sum_{j=1}^n\alpha_i\alpha_jy_iy_jx_i^Tx_j\\ &约束条件:\sum_{i=1}^n\alpha_iy_i=0 \end{aligned} 求解目标:α=αargmax i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxj约束条件:i=1∑nαiyi=0
显然我们可以对该对偶问题进行核化:
α = a r g m a x α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j k ( x i , x j ) \alpha=\underset{\alpha}{argmax}~\sum_{i=1}^n\alpha_i-\frac12\sum_{i=1}^n\sum_{j=1}^n\alpha_i\alpha_jy_iy_jk(x_i,x_j) α=αargmax i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjk(xi,xj)
最终的模型为:
h ( x ) = sign ( w T x + b ) = sign ( ∑ i = 1 n α i y i k ( x i , x ) + b ) h(x)=\text{sign}(w^Tx+b)=\text{sign}\big(\sum_{i=1}^n\alpha_iy_ik(x_i,x)+b\big) h(x)=sign(wTx+b)=sign(i=1∑nαiyik(xi,x)+b)
从支持向量的角度对对偶问题有一个很好的解释:对于原始公式,我们知道只有支持向量满足等式约束:
y i ( w T ϕ ( x i ) + b ) = 1 y_i\big(w^T\phi(x_i)+b\big)=1 yi(wTϕ(xi)+b)=1
在对偶问题中我们可以使得支持向量所对应的 α i > 0 ~\alpha_i>0~ αi>0 ,而其他的输入向量对应的 α i = 0 ~\alpha_i=0~ αi=0 ,在测试时我们只需要计算支持向量上 h ( x ) ~h(x)~ h(x) 的和,并在训练后丢弃所有 α i = 0 ~\alpha_i=0~ αi=0 的特征向量。
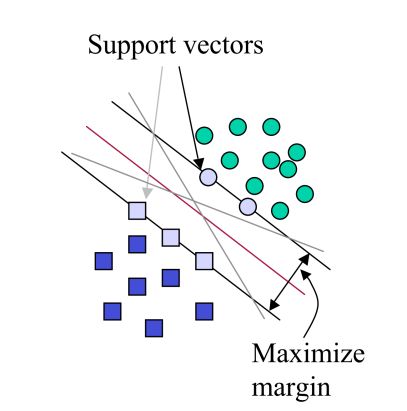
对偶有一个明显的问题,就是 b ~b~ b 不再是优化的一部分了,但是我们需要它来进行分类,在对偶中支持向量是那些 α i > 0 ~α_i>0~ αi>0 的向量,因此我们可以推导出 b ~b~ b :
y i ( w T ϕ ( x i ) + b ) = 1 , y i ∈ { − 1 , + 1 } → b = y i − w T ϕ ( x i ) → b = y i − ∑ j = 1 n α j y j k ( x j , x i ) \begin{aligned} &y_i(w^T\phi(x_i)+b)=1,y_i\in\{-1,+1\}\rightarrow b=y_i-w^T\phi(x_i)\\ &\rightarrow b=y_i-\sum_{j=1}^n\alpha_jy_jk(x_j,x_i) \end{aligned} yi(wTϕ(xi)+b)=1,yi∈{−1,+1}→b=yi−wTϕ(xi)→b=yi−j=1∑nαjyjk(xj,xi)
同时如果使用软间隔模型,则仅需添加一个新的约束:
0 ≤ α i ≤ C 0\le\alpha_i\le C 0≤αi≤C
由于正文字数限制,模型的实现原码和SMO算法就去掉了,可以查阅我的个人博客文章 核函数,这里有详细的原码与算法解析!