基于数据挖掘的触诊成像乳腺癌智能诊断模型和方法
基于数据挖掘的触诊成像乳腺癌智能诊断模型和方法
张旭东, 孙圣力, 王洪超
北京大学软件与微电子学院,北京 100089
北京先通康桥医药科技有限公司,北京 101300
摘要:为了辅助医护人员利用触诊成像技术判定乳腺癌,提出了触诊成像乳腺癌智能诊断模型和方法。采用乳腺癌早期筛查及风险评估的临床数据,以触诊成像诊断结果为对比数据,通过决策树等机器学习算法以及投票法,对乳腺肿瘤的良恶性质进行判定。使用SMOTE算法对数据进行处理,建立了诊断模型和方法,自动完成对乳腺肿瘤性质的诊断。实验结果表明,乳腺癌正确筛查的准确性达到98%,提出的方法具有很好的应用价值。
关键词: 智能诊断 ; 临床数据 ; 机器学习 ; SMOTE算法
![]()
论文引用格式:
张旭东, 孙圣力, 王洪超. 基于数据挖掘的触诊成像乳腺癌智能诊断模型和方法. 大数据[J], 2019, 5(1): 68-76
ZHANG X D, SUN S L, WANG H C. Intelligent diagnosis model and method of palpation imaging breast cancer based on data mining. Big data research[J], 2019, 5(1): 68-76
![]()
1 引言
近年来,乳腺癌已成为威胁女性健康的恶性疾病,发病年龄集中于45~55岁,发病率则随着年龄的增长呈上升态势。提高广大妇女的乳腺健康意识,加强和规范乳腺癌筛查工作,以便早诊早治,对于降低乳腺癌死亡率至关重要。在乳腺癌筛查中应以较少的人力、物力取得较大的社会效益,即选择灵敏、经济的检测手段,制定最佳的筛查方案。
鉴于触诊成像在大规模人群筛查中体现出的快速高效的独特优势,本文结合机器学习相关技术,采用乳腺触诊诊断仪收集的临床数据,进行诊断模型训练,以乳腺癌临床病理诊断结果为判读标准,建立了一套基于触诊成像的乳腺癌智能诊断方法,以实现乳腺癌的智能化判定,进而提高大规模人群乳腺癌筛查的效率。
在医疗领域,大数据的取得及应用至关重要。大部分数据是通过文献、临床数据、结构化数据、非结构化数据及第三方数据库等渠道获取的。医疗数据存在以下特点和问题。首先,医疗数据具有显著的特殊性及复杂性,要在短时间内积累大量有价值的数据,难度和成本很高;其次,医疗数据往往面临不平衡数据集的问题,样本种类不平衡会导致整个数据集难以有效地运用,数据无法发挥其最大效能。因此,从不同渠道获取数据后,应进行数据清洗,确保数据质量,并在数据转换、重新建构后,将数据存入数据库以供使用。医疗智能诊断旨在帮助医疗机构或医生个人利用信息技术对医学数据进行收集、管理及分析。本文通过积累相关医学知识,利用数据清洗、数据增强等方式提升数据的价值,并运用相关机器学习算法进行乳腺癌预测,建立了一套触诊成像乳腺癌智能诊断方法。
2 乳腺癌智能诊断建模流程
笔者参与的乳腺触诊成像健康体检人群乳腺癌早期筛查研究项目积累了多家医院的临床数据。本文基于这些数据,以触诊成像诊断结果为对比数据,进行相关的预测研究。所有触诊成像被诊断为乳腺癌的阳性标本均经过病理诊断验证,在乳腺癌样本数据中随机选择3个数据集(分别表示为数据集1、数据集2、数据集3),数据量分别为13 428条、1 554条、902条,总计15 884条数据样本。
综合考虑各方面因素和临床数据的特点,运用机器学习中常用的决策树、神经网络、支持向量机(support vector machine,SVM)、逻辑回归及贝叶斯网络5种算法,再结合多种投票法,进行乳腺肿瘤的形态预测和判定。
数据在经过预处理等相关操作后,运用合成少数类过采样技术(synthetic minority over-sampling technique, SMOTE),将阳性样本进行合理范围的增量,以解决不平衡数据集问题。对模型进行测试及改进,选择最佳分类模型和方法,并综合利用准确率、召回率等指标,评估分类模型的优劣,得到高质量的乳腺诊断模型,提升总体辅助诊断水平。
整个建模流程如图1所示。

图1 乳腺癌智能诊断建模流程
3 数据清洗与准备
依据数据清洗(data cleaning)的原则,按图2所示过程进行数据清洗。

图2 数据清洗流程
原始临床数据有位置、象限、压力值、肋骨干扰、3D峰值、2D颜色、3D峰顶形状、3D形状、3D基底、3D动态、2D形状、2D动态颜色分布、血流灌注指数(PI)诊断结果及病理结果14个属性。其中,压力值及肋骨干扰两个属性对智能诊断系统并无显著影响,故而剃除。为确保数据的完整性,将36个含有缺失值及62个含有噪音值的数据样本剔除。各属性数据缺失量与噪音数据量如图3所示。
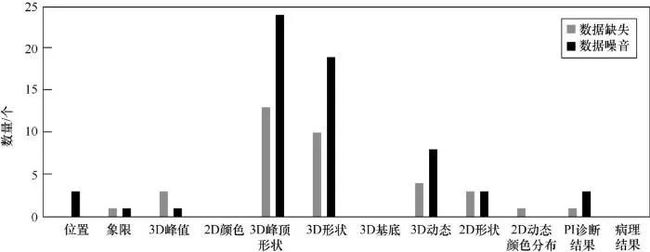
图3 各属性数据缺失量与噪音数据量
整个数据集内初始的阳性样本有135个,占所有数据的0.85%。由于阳性数据与阴性数据的比例极不平衡,故而进行了样本数据的整理。在数据查重时,发现排除位置及象限两个不影响结果的属性后,有168个阴性数据与阳性数据属性相同。为避免错失恶性病例情况的发生,将这168个原本标为阴性而实则为阳性的数据样本更改成阳性,以提高数据的准确性。查重前后阳性数据数量见表1。
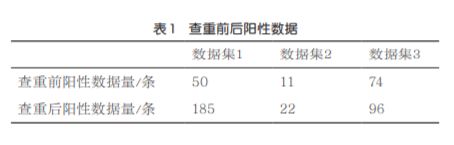
SMOTE算法通过采样操作解决类别间比例相差悬殊的问题。当数据集类别不均衡时,一般采取随机欠采样和随机过采样两种方式来处理。本研究中抽取新值的SMOTE算法示意如图4所示,依次遍历数据集中每个集合,直到处理完所有数据为止。最后,将新增加点的集合加至原有数据集的恶性病例类别中,并构成新的数据集。该算法避免了随机过采样复制样本带来的样本数据不准确的问题,解决了模型学习到的信息过于特别而不够泛化的问题。
图4 SMOTE算法示意
本研究依 据混淆矩阵的分类指标进行模型定量评估,包括准确率(accuracy)、精确度(precision)、召回率(recall)、真阳性率(true positive rate)、F值,其中,召回率又被称为灵敏度(sensitivity)。机器学习中常用准确率与召回率作为参考指标,各指标定义如下:TP为将阳性样本预测为阳性样本的样本数,FN为将阳性样本预测为阴性样本的样本数,FP为将阴性样本预测为阳性样本的样本数,TN为将阴性样本预测为阴性样本的样本数。准确率(正确率)=(TP+TN)/总样本数,精确率=TP/(TP+FP),召回率=TP/(TP+FN),F值=正确率×召回率×2/(正确率+召回率)。
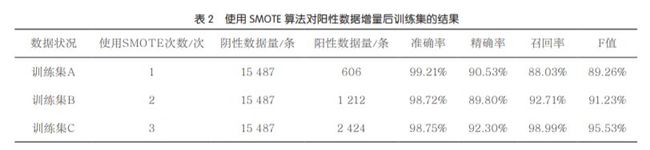
本文使用SMOTE算法进行阳性样本增量,数据总量为15 790条(阳性数据303条),使用SMOTE算法第1次和第2次处理数据后,阴性样本与阳性样本的比例分别为25:1和13:1,比例依然不平衡。使用SMOTE算法第3次处理数据后,阳性数据增加至2 424条,阴性样本和阳性样本比例约为6:1,数据集的样本种类较先前数据集更合理且平衡。详细结果见表2。
通过使用SMOTE算法3次处理数据后,近邻点K值在1到7中选择并比较结果。近邻点K值是SMOTE算法中生成新样本的参数。经过对比发现,K=7时呈现过拟合的现象,即分类结果有明显下滑的趋势,故选择结果表现较优秀的值,即K=6值。
4 模型训练与预测
随后进行数据集抽取。乳腺癌分类属二元分类问题,故将数据内容定义为标准型数值{N,P},符合数据集要求。在实验设计过程中,将数据集分为训练集及测试集两部分。首先从数据清洗及查重后的数据集内抽取90%的数据作为训练集;在经数据清洗后的数据集内,随机抽取6份数据组成测试集(A~F),每份抽取10%的数据样本,特殊测试集1、特殊测试集2由两份单独的数据集组成,进行最后的模型评估。数据分布见表3。

本文选用决策树、神经网络、SVM、逻辑回归、贝叶斯网络作为基分类器,基于训练集进行模型训练。然后,基于上述分类模型进行乳腺癌预测,并根据预测结果进行模型筛选和优化。各基分类器具体预测结果见表4。

在基分类器参数最优的前提下,本文将神经网络[15]由原来的单一隐含层调整为两个隐含层,提高了网络的分类能力。结构优化前后的结果对比见表5。

在上述基分类器模型预测的基础上,再进行预测算法和模型的优化选择。
组合分类技术是最主要的提高分类器精确度的方法。将通过多个分类器得出的结果作为最终判断的依据,从而避免单一分类器产生的判断误差或片面性信息,以优化分类效果。本文提出的乳腺癌组合预测诊断方法的处理流程如图5所示。
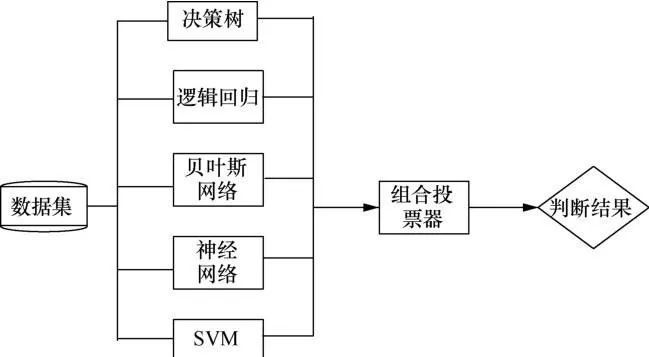
图5 乳腺癌组合预测诊断方法流程
通过上述实验,笔者发现决策树、SVM及神经网络3种算法在乳腺癌智能诊断系统中呈现较好的结果,故将贝叶斯网络及逻辑回归两种算法剃除,仅保留决策树、SVM及神经网络3种算法。由表6可以得知,仅以3种算法作为模型,其准确率及精确率都有显著提升。

在以3种算法作为模型的基础上,笔者构建了一种基于投票选择的组合预测优化方法。在本文乳腺癌预测诊断的方法中,设计了4种投票组合法,包含一票确定法、两票确定法、多票确定法和加权投票法A。因优化的模型中只有3种算法,多票确定法与两票确定法的结果相同,所以删除了多票确定法。
表7结果显示,在优先保证召回率的前提下,加权投票法A与一票确定法结果相同。综合考虑先前阶段的实验对比,选择加权投票法A作为优化后模型的投票方法。

5 实验结果和分析
将使用SMOTE算法的次数设为3、近邻点K设为6,采用3种算法(决策树、SVM、神经网络)及加权投票法A进行最终的训练并建模。随机测试集A~F、特殊数据集1和特殊数据集2对训练集模型验证的结果见表8。
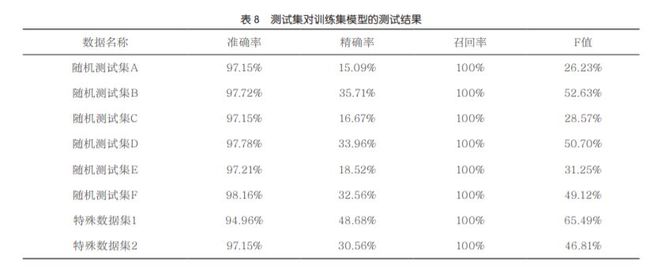
图6的结果是8份测试集的平均结果,包括召回率、精确率、准确度及F值4项结果。表8结果显示,8份测试集的准确率达97%,说明模型对数据的判断能力很高。此外,随机测试集A~F、特殊数据集1和特殊数据集2的召回率皆达100%,即所有阳性样本都能被正确地判断出来,说明预测方法的判断结果具有良好的临床辅助诊断应用价值。
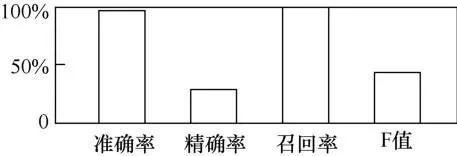
图6 测试集平均结果
6 结束语
本文构建了基于触诊成像的乳腺癌智能诊断模型,给出了5种主要分类算法,通过数据预处理、样本调优等操作,整理出训练和测试数据集。在此数据集的基础上,抽取训练集与测试集,通过训练集训练,建立分类模型及组合投票器,最终判断结果。基于前期预备与调研工作,在保证数据质量的前提下,运用特殊数据进行实验,最终结果在召回率与准确度指标上表现优异。鉴于医疗诊断模型的结果关系重大,笔者后续将持续追加新数据组成新的数据集,不断对模型进行训练,使模型更加完善,以期提供更加高效的临床诊断工具。
作者简介
张旭东(1991- ),男,北京大学软件与微电子学院硕士生,主要研究方向为深度学习、计算机视觉等。
孙圣力(1979- ),男,北京大学软件与微电子学院副教授,主要研究方向为大数据管理、数据挖掘、图数据库、智慧医疗等。
王洪超(1968- ),男,就职于北京先通康桥医药科技有限公司,主要研究方向为乳腺触诊成像技术的开 发和临床应用研究。
《大数据》期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的中文科技核心期刊。

关注《大数据》期刊微信公众号,获取更多内容
往期文章回顾
数据安全治理的几个基本问题
“全息数字人”——健康医疗 大数据应用的新模式
医疗数据治理——构建高质量医疗大数据智能分析数据基础
基于深度学习的异构时序事件患者数据表示学习框架
人工智能在医学影像中的研究与应用