CCNet:交叉注意力语义分割
论文地址:https://arxiv.org/pdf/1811.11721.pdf
目录
0、摘要
1、CCA、RCCA模块
2、网络结构
3、损失函数
4、结论
0、摘要
上下文信息对视觉理解问题十分重要,如在语义分割和目标检测领域。提出了交叉网络(CCNet),通过一种有效且高效的方式来获取全图上下文信息。具体地,对每个像素,使用了一种新颖的交叉注意力模块在该像素交叉路径上收集所有像素的上下文信息。通过进一步的循环操作,每个像素最终能够获取全图依赖关系。此外,还提出了一种类别一致性损失,用于强制交叉注意力模块获取更多有差异性的特征。总的来说,CCNet有以下优点:(1)GPU显存友好,与non-local模块相比,所提出的循环交叉注意模块的GPU内存使用量减少了11倍;(2)高计算效率:循环交叉注意力显著的将non-local的FLOPS降低了85%;(3)SOTA的性能:我们在Cityscapes、ADE20K、人体解析基准LIP、实例分割基准COCO、视频分割基准CamVid等语义分割基准上进行了大量的实验,实验结果显示,CCNet在Cityscapes测试集、ADE20K验证集和LIP验证集上分别获得了81.9%、45.76%和55.47%的mIoU得分,这是最新的最先进的结果。
官方代码:https://github.com/speedinghzl/CCNet.
1、CCA、RCCA模块
基于FCN的语义分割方法无法利用更多的上下文信息,因此有很多方法致力于扩展网络对上下文信息的利用,如DeepLab系列的ASPP、PSPNet的PPM。但是这些方法要么使用的上下文信息有限,要么不能满足不同像素获取不同上下文信息的要求。
一些全连接的图神经网络(GNN)被提出,以利用密集的、像素级的上下文信息。如PSANet是通过一个预测注意力map来聚合每个位置的上下文信息,Non-local网络利用自注意力(self-attention)使得每个像素都能够感知其他所有位置从而有了全局上下文信息。
Non-local可以看做一个注意力机制下的密集连接的GNN,虽然能够捕获全局上下文信息,但是其计算复杂度是 。为了解决计算复杂度过高的问题,本文的CCNet就提出了一种更加高效的注意力模块——交叉注意力模块(criss-cross attention module,CCA),其与Non-local的对比可见图1:
。为了解决计算复杂度过高的问题,本文的CCNet就提出了一种更加高效的注意力模块——交叉注意力模块(criss-cross attention module,CCA),其与Non-local的对比可见图1:
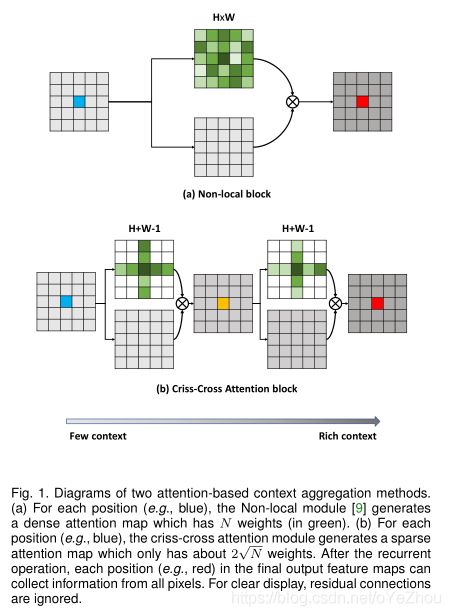
图1(a)为Non-local的注意力模块,(b)为CCNet提出的交叉注意力模块。可见:Non-local生成的是密集的attention map,而 criss-cross attention module生成attention map的只利用了十字交叉路径上的特征,这种操作大大降低了计算复杂度。交叉注意力模块的结构如下图:
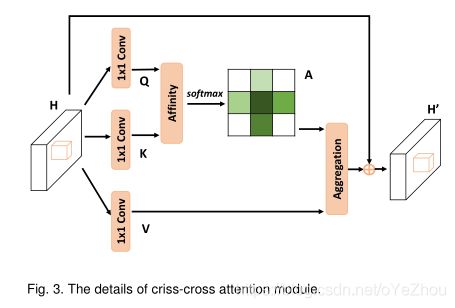
可以看出,和Non-local的self-attention过程是十分相似的。
但是有一个问题,由于单次的 criss-cross attention module只能捕获十字路径的特征,那么其他地方的特征难道就不用了吗?作者的解决方案是用两次 criss-cross attention module就行了!这也就是所提出的RCCA模块。
为什么用两个交叉注意力模块就能捕获全局上下文信息,看下图和解释就明白了:

具体解释如下:
- 在loop1时,深绿色的特征可以捕获其十字路径上的所有特征的依赖关系,其中就包括浅绿色的两个特征,而浅绿色的两个特征又分别能捕获蓝色特征的依赖关系;
- 在loop2时,深绿色特征再次捕获浅绿色位置上的特征依赖时,浅绿色的特征已经包含了蓝色特征的依赖关系,从而使得深绿色特征间接地获取到了蓝色特征的依赖关系;
- 同理,对于其他不在深绿色特征十字路径上的特征,其同样也能捕获依赖关系,如此就实现了和Non-local一样的全局上下文信息的获取。
2、网络结构
对于语义分割,其通用的网络结构如下图所示:
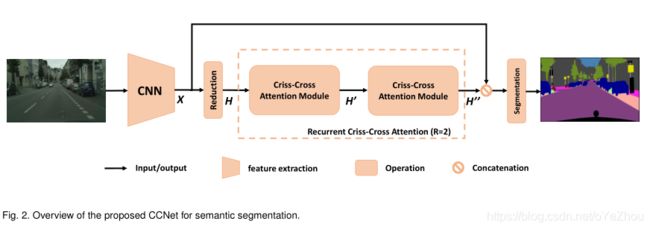
可以看出网络结构还是非常简洁的:通过一系列DCNN提取feature maps之后,就送入了RCCA模块进行全局上下文信息的提取,然后将提取的全局上下文信息和从DCNN出来的feature maps拼接起来,最后就用于生成分割map了。
有几点细节需要注意:
- DCNN为了获取高分辨率的输出,去掉了最后的两个下采样层,所以获取的输出feature maps尺寸是原图的1/8,;
- 从DCNN得到的feature maps通过一个卷积层进行了通道降维,这是为了降低attention模块的计算量;
- 进行通道降维后,送入RCCA,该模块可以包含多个(2个及以上)的CCA(PS:其实两个CCA就能够获取全局上下文了,多个可能效果更好,但计算量也更大,需要权衡下);
- 后面的concatation操作之后,需要一个或者多个带有BN和激活函数的卷积层,来进行信息融合,然后才生成的分割结果。
此外,CCA模块还被作者扩展到了3D,这里不做解析,看看就行了:
3、损失函数
RCCA模块可以捕获全局上下文信息,但同样有可能存在过度平滑的问题(over-smoothing),这也是GNN中的常见问题。而对于语义分割这类任务来说,同一个类别的像素应该具有更相似的特征,不同类别的像素应该具有差别更大的特征,作者称之为“类别一致性”。为了解决这个潜在的问题,除了用交叉熵损失的来惩罚最终预测结果和GTs之间的不匹配,进一步引入类别一致损失来强迫RCCA模块直接学习类别一致的特征。
受Semantic instance segmentation with a discriminative loss function的用于实例分割的损失函数启发,作者提出了用于语义分割的损失函数。不同之处在于:为了提高鲁棒性,不再使用二次函数来处理不匹配问题,而是设计了一个分段距离函数。
设C为一个minibatch中出现的类别数,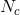 是属于
是属于![]() 的有效元素个数,
的有效元素个数,![]() 是空间位置
是空间位置 的特征向量,
的特征向量,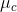 是类别
是类别![]() 的平均特征(聚类中心)。
的平均特征(聚类中心)。
Semantic instance segmentation with a discriminative loss function中的损失函数有三项:![]() ,分别代表了三种情况下的惩罚:
,分别代表了三种情况下的惩罚:
(1)类别相同,特征距离较远;(2)不同类别,特征距离较近;(3)所有类别与原点损失的平均。
相应的,CCNet的损失如下:
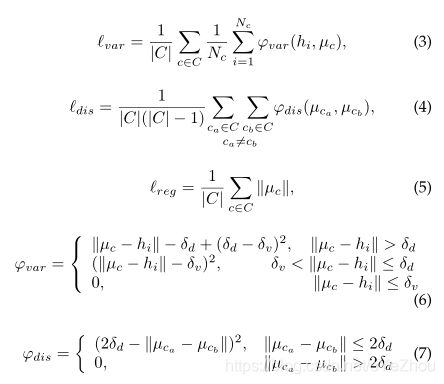
![]()
4、结论
本文主要是为了解决Non-local中自注意力模的的计算复杂度过大的问题,提出了CCA模块以及RCCA模块,既降低了计算复杂度,又降低了内存的使用率,并以此模块为基础构建了CCNet网络。此外还提出了了类别一致性损失,用于建模类内、类间特征之间的距离损失。