【论文阅读】CCNet(IEEE TPAMI 2020 & ICCV 2019)
论文题目:CCNet: Criss-Cross Attention for Semantic Segmentation
论文地址:https://arxiv.org/abs/1811.11721
代码地址:https://github.com/speedinghzl/CCNet
文章贡献:
1. 提出了交叉注意模块Criss-Cross Attention module,可以从全图像上捕获上下文信息,可直接扩展到3D网络中;
2. 提出了类别一致损失category consistent loss,可以使交叉注意模块产生更多的判别特征;
3. 提出的CCNet在多个数据集上取得了先进的性能。
该论文有2个版本,v1是ICCV2019上的,v2是TPAMI2020。相比较v1,v2增加了以下内容:
- 提出了类别一致损失category consistent loss;
- 将CC由2D扩展到3D网络;
- 在更多的数据集上进行了实验。
1 背景和动机
语义分割是计算机视觉领域的一个基本问题,目前基于FCN的各种方法取得了显著的进步。
然而,传统的FCN由于其固定的几何结构,固有地局限于局部接受域,只能提供近距离的上下文信息。语境信息不足的局限性对其分割精度有很大的影响。
目前的解决方法主要有以下问题:
1. 膨胀卷积没有密集的上下文信息,基于池化的方法不能适应于多尺度物体;
2. GNN/PSANet/Non-local方法都需要很多计算力。
为了解决上述问题,论文提出Criss-Cross Attention模块,使用几个连续的稀疏连接图来代替常见的单个密集连接图,可以使得所需计算资源较少。
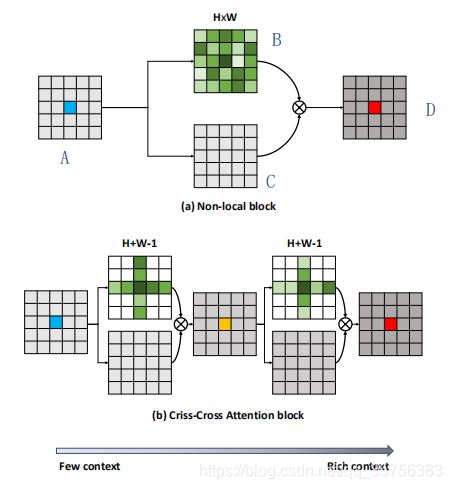
如上图所示,对于特征图上的每个位置(蓝色点),生成一个在全图上的attention map(B),并对输入特征图(A)做某种转化(C)。然后对B和C进行加权和,获得每个位置的上下文信息D。图(a)是非局部模块,图(b)是论文提出的交叉注意模块。
对于每个像素/位置,CCA模块在水平和垂直方向聚合上下文信息,通过2个CCA模块的叠加,每个位置都可以从给定图像的所有像素中收集上下文信息。上述策略使得时空复杂度由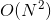 降到
降到![]() 。
。
2 相关工作
语义分割
介绍了一直以来语义分割方面的进展,包括编码-解码结构、改进的卷积操作、实时语义分割、人类解析任务等。
论文借鉴了其中一些点[1,2],去掉了最后的两个下采样层来获取密集预测,并使用膨胀卷积来增加感受野。
上下文信息聚合
常用方法有ASPP聚合多尺度信息、RNN捕获长期依赖、图模型、自注意机制、非局部模块等。
CCNet、Non-Local、GCN[3]的对比:
- 信息聚合范围:GCN只有中心点能够通过全局卷积滤波器感知所有像素的上下文信息;CCNet和Non-Local的任何位置的像素都能从所有像素中感知上下文信息;
- 计算量:CCNet模拟Non-Local来获取密集上下文信息,但时空复杂度低;
- 信息聚合效果:CCNet使用Criss-Cross方式,GCN使用horizontal-vertical separate方式,获取上下文信息更有效;
- GCN是一种传统的卷积神经网络,而CCNet是一种图神经网络,将卷积特征图中的每个像素都视为一个节点,利用节点之间的关系/上下文来生成更好的节点特征。
图神经网络
大量的方法将图结构应用到CNN中,这些方法主要包括两类:基于光谱的方法和基于空间的方法,CCNet属于后者。
3 网络模型
CCNet网络框架
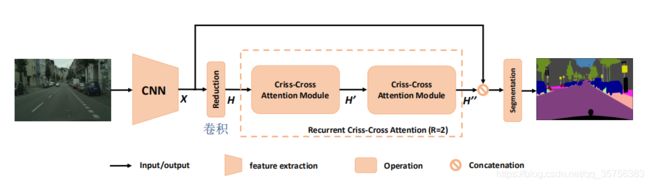
输入图像经过CNN骨干网络提取特征X,shape为HxW。为了保留更多的细节,有效地生成密集的特征图,论文去掉了骨干网络中最后两个下采样操作,并在随后的卷积层中使用膨胀卷积,使得X为输入图像的1/8大小。
特征图X经过卷积操作降维,获得H。H经过CCA模块得到H',H'只包含水平和垂直方向的上下文信息。H'再次经过CCA模块得到H'',H''中的每个位置收集了所有像素的信息。前后两个CCA模块共用相同的参数,避免添加过多的额外参数。
将H''和X concat,再经过一系列的卷积层和激活函数来进行特征融合,最后将融合特征输入分割层以获得最终的预测分割结果。
2D交叉注意模块
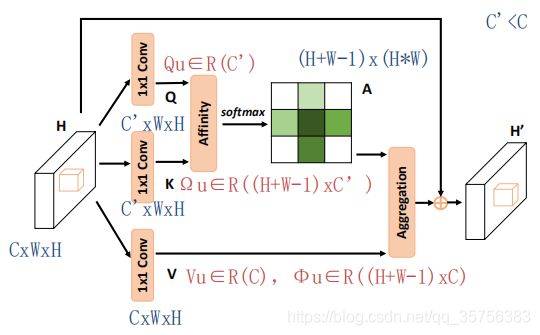
对于给定的特征图H(CxHxW),进行1x1卷积操作,得到Q和K(shape为C‘xHxW,其中C'小于C)。对Q和K进行Affinicy操作,得到注意图A。
对H进行另一个1x1卷积操作,得到V(CxHxW),来进行特征自适应。对A和V进行Aggregation操作,将其结果与原来的H相加,得到融合了上下文信息的特征图H'。
Affinicy操作具体来说,在Q上任意像素点u取得一个通道向量Qu,可认为shape为1x1xC’。同时,在K上像素点u的同行同列所有位置上取得一个特征向量Ωu,有Ωu∈[(H+W-1)xC‘]。Ωi,u 表示Ωu上的第i个像素的通道向量,可认为shape为1x1xC’。有:
![]()
di,u∈D,表示Qu和Ωi,u的相关程度。i=[1,2,...,H+W-1],D∈[(H+W-1)x(WxH)]。在D的通道维度上应用一个softmax层,获得注意图A。
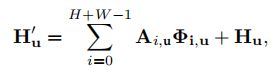
H'u是特征图H'上像素点u处的特征向量,Ai,u是A在通道i位置u的一个scalar value。
RCCA(Recurrent Criss-Cross Attention)
交叉注意模块可以捕捉水平和垂直方向的上下文信息,但一个像素与其周围不在交叉路径中的像素之间的连接仍然缺失。因此作者提出RCCA,即对CCA模块进行多次循环操作,使得RCCA模块可以聚合所有位置的上下文信息。
当循环次数R=2时,特征图H和注意图A有如下关系:

其中,![]() 是H中的任意一个像素点,
是H中的任意一个像素点,![]() 是像素点u的十字交叉位置的所有点,f是从H到A的一个映射关系。uCC对应的是Ai,u中的第i行,u对应的是A中的列。
是像素点u的十字交叉位置的所有点,f是从H到A的一个映射关系。uCC对应的是Ai,u中的第i行,u对应的是A中的列。![]()
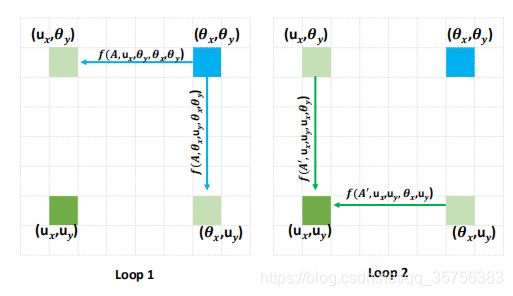
当点u(ux, uy)在点θ(θx, θy)的十字交叉位时,很明显θ可以捕获到u的上下文信息;
当u不在θ的十字交叉位时,如上图所示。经过第一个循环,点θ将信息传递到点(ux, θy)和(θx, uy);第二个循环时,点(ux, θy)和(θx, uy)再将信息传递给u。因此R=2时,RCCA可以从所有像素中获取密集的上下文信息。
损失函数
类别一致性(category consistency):在语义分割任务中,属于同一类别的像素应该有相似的特征,而不同类别的像素应该有相差很远的特征。
实例分割任务中,自下而上的思路是,首先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。而图神经网络中,聚合特征可能存在过平滑问题。因此论文除了交叉熵损失L(seg),进一步引入了category consistent loss。其前身来自于论文[4,5]:
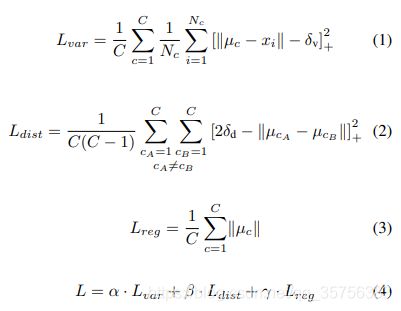
C是类别总数,Nc是类别c的像素个数,xi是特征图H上位置i的特征向量,µc是类别c的mean feature。有:
- 拉力L(var):惩罚同一实例中相隔距离远的点;
- 推力L(dist):惩罚不同实例但是相隔距离近的点;
- 正则化L(reg):中心点不应该离原点太远。

可以理解为,对于上图中叶子的实例分割,(第一行)首先是一堆五颜六色的点,有一个拉力将所有颜色相同的点都聚合在一起,这会产生很多颜色中心点。之后推力将不同颜色的点远离不属于它们的中心点。最后是让所有颜色的中心点不要太过于偏离原本散点的原点。
作者将论文[4]中L(var)和L(dist)的二次函数换成了分段函数:

对L(var)设置了2个分界值δv<δd,对L(dist)设置了一个分界值δd。
为了减少计算量,该论文首先在RCCA模块的输出上使用1×1卷积进行降维,然后在通道较少的feature map上应用这三种损失。实验中,论文设置δv=0.5,δd=1.5,α = β = 1, γ = 0.001 ,降维后的维度为16。
3D交叉注意模块
和2D交叉注意模块类似,引入了时间维度T:
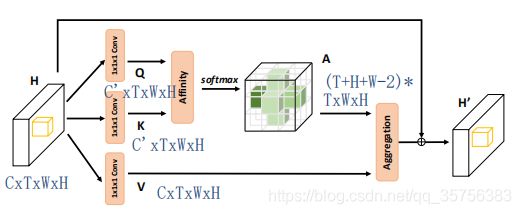
卷积为1x1x1,注意图A的shape为(T+H+W-2)*(TxHxW)。
4 实验结果
在Cityscapes、ADE20K、COCO、LIP、CamVid数据集上进行了实验。(加粗表明该论文方法效果最好)
论文选择resnet101作为骨干网络,去掉它的最后两个down-sampling操作,并在之后的卷积层中使用膨胀卷积,导致输出步幅为8。
1. Cityscapes:将训练图片随机缩放(倍率为0.75-2.0),再将其中大的图片裁剪为769x769的大小。
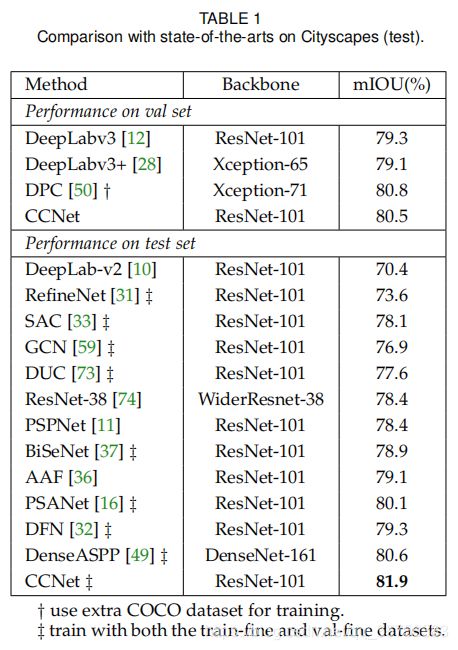
- CCNet与其他先进方法的比较:
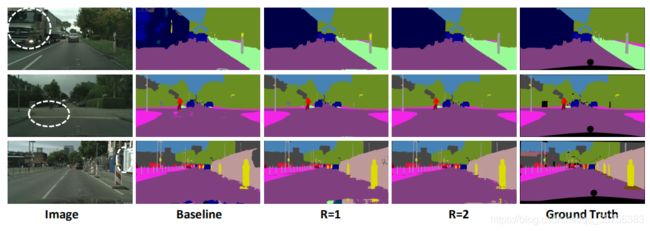
- RCCA模块的效果:

R=1和baseline的对比证明了交叉注意模块的显著性,R=2和R=1对比证明了密集上下文信息的有效性。随着循环次数R的增加,浮点运算次数和GPU内存使用也在增加。为了平衡性能和资源的使用,论文设定R=2。
RCCA与Non-Local资源使用的比较:

- 损失函数CCL的效果&与其他上下文聚合方法的比较:
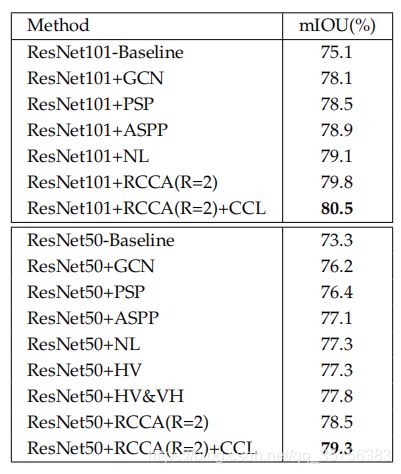
CCL可以带来0.7%的增益。
分段与否的对比:

使用ResNet50对每种损失函数进行10次训练过程。当损失值为NaN时,则认为训练失败。可以看到,使用分段函数比原函数有更高的成功率,且性能更好。
- 注意图的可视化:

在R不同时对应选取绿点的注意图,R=1时只有十字交叉的信息,R=2时有全局信息。
2. ADE20K:将训练图片中的短边随机调整为以下长度{300, 375, 450, 525, 600},长边按比例缩放。
与其他先进方法的比较:
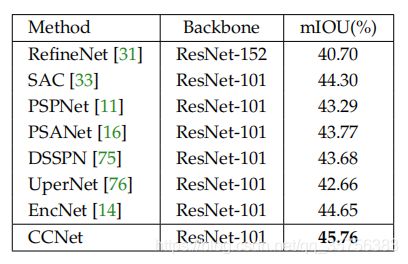
损失函数CCL的效果:

3. LIP(人类解析数据集):选择CE2P作为基线,将Context Embedding模块由PSP替换为RCCA。训练图片大小为473x473。


前2行分割正确,第3行类别分类错误,将裙子误分为裤子。
4. COCO(实例分割):选择Mask-RCNN作为基线,修改了骨干网络,在最后一个卷积块res4前加入了RCCA模块。
为了公平比较,未使用CCL损失,只比较了RCCA模块使用与否:


5. CamVid(视频语义分割):使用3D RCCA。在每个训练视频中随机抽取连续的T帧,图片大小为504x504。

在每一帧图像上应用CNN提取特征,并对特征进行串联和重构,以满足3D RCCA需求的形状。T表示输入帧的长度,设置R=3。
T=5时比T=1效果好,说明3D RCCA有效的提取了时间上下文信息。
5 相关文献
[1] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” ICLR, 2015. 3, 7, 10
[2] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” ICLR, 2016. 3, 12
[3] C. Peng, X. Zhang, G. Yu, G. Luo, and J. Sun, “Large kernel mattersimprove semantic segmentation by global convolutional network,” in CVPR, 2017, pp. 1743–1751. 3, 7, 9
[4] B. De Brabandere, D. Neven, and L. Van Gool, “Semantic instance segmentation with a discriminative loss function,” arXiv preprint arXiv:1708.02551, 2017. 5, 6
[5] https://zhuanlan.zhihu.com/p/102231853?utm_source=qq