NLP发展的四个范式——Prompt的相关研究
本文主要基于论文《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》对NLP的四个方式和Prompt的相关研究进行介绍和说明。
1. NLP发展的四个范式
1.1 四个范式
- P1:非神经网络时代的完全监督学习(Fully Supervised Learning, Non-Neural Network)
- P2:基于神经网络的完全监督学习(Fully Superivised Learning, Neural Network)
- P3:预训练,精调范式(Pre-train,Fine-tune)
- P4:预训练,提示,预测范式(Pre-train, Prompt, Predict)
1.2 不同范式演变过程中的规律
在这种不同范式变迁过程中,有些东西是不变的,把它们挖掘出来就很有意思
1.2.1 规律1:每个范式都会涉及繁琐的,需要人来参与(提供先验)的工程(engineering)
P1. 非神经网络时代的完全监督学习
- 特征工程(Feature Engineering):我们要进行“无聊”的特征模板定义环节。
P2. 基于神经网络的完全监督学习
- 结构工程(Architecture Engineering):神经网络虽然解放手动配置特征模板所需要的人力,但是是以需要人工去设计合适网络结构为代价的。因此,在这样的研究范式下,研究人员花了很多时间在探究最适配下游任务的结构偏置(Structural Bias)。比如是使用“卷积循环变形金刚(Transformer)网络“,还是使用”卷积变形金刚(Transformer)循环网络“。
P3. 预训练,精调范式
- 目标函数挖掘(Objective Engineering):这个过程研究者往往是通过引入额外的目标函数到预训练语言模型上,以便让其更适配下游任务。这个过程有时候也需要些网络结构的挖掘,但相比较而言,不是这个范式的主旋律,一个实际的原因在于:
- (1)预训练过程本身费时,过度的结构偏置(structural bias)探索开销过大;
- (2)精调的过程中,很多时候 预训练语言模型本身提供的知识已经可以让大家“忘记”使用卷积神经网络和循环神经网络的差异。
P4. 预训练,提示,预测范式
- Prompt挖掘工程:在这个过程我们往往不对预训练语言模型改动太多,我们希望是通过对合适prompt的利用将下游任务建模的方式重新定义。
规律1的应用:
因为有规律1的存在,我们可以更加辩证的看待新的范式,这句话的价值体现在两个场景:
(1) 当我们使用新范式的方法的时候,能够意识到它带来的优异性能是以某种“人力”牺牲(需要一些人工设计加持)为代价的,而如何让这种人力代价将到最低,往往就是新范式里需要解决的核心问题。
(2)当我们某个瞬间突然有些“神奇”的想法,它与现在的主流解决思路很不相同,可是实现它又需要一些很琐碎的操作,那么这个时候,恭喜你,因为你很有可能在接近一个新的范式(或者新的解决框架),假如存在上帝视角的话,可能那个“神”在看着你,期待着你坚持下去,因为你将会给这个领域的发展带来与众不同和进步。
当然,从有想法到真正把它实现出来会成为另一个关键点,而决定能否做成的因素中,比较重要的可能是:信心,坚持,对领域的理解,以及实现能力。
1.2.2 规律2:新范式带来的收益可以让我们暂时“忽略”那些额外需要的人力代价
不过这里值得注意的是,关于“收益”的定义并不唯一,它不只是被定义为某个任务性能的提升,还可以是“帮我们做一些过去框架不能做的事情”,或者是新的研究场景。比如,无论是神经网络早期在NLP的应用,或者是Seq2Seq 早期在翻译上的应用,都没有在性能上讨得便宜(相比于传统统计方法),可是这种颠覆性的想法给了我们太多可以想象的空间(比如既然翻译可以用Seq2Seq,那么其他任务是不是也可以这样呢?那么NLP任务解决框架就可以被统一了吗?)
当我们回顾P(N) 逐渐 取代 P(N-1)的过程 (这里P是指上面定义的范式)我们突然理解:
- P1->P2: 虽然我们常常吐槽神经网络调参如炼丹,可是也在享受着不用手工配置模板,就能够得到还不错甚至更好结果的福利。与其说“炼丹“,我觉得神经网络的训练更像是“陶艺”,而传统的特征工程更像是“炼丹”,因为它对原材料(特征)的选择以及加入丹炉的顺序(特征组合)的要求几乎非常苛刻。(大家可以感受下,炼丹和陶艺的过程:https://zhidao.baidu.com/question/936545101298430372.html;https://zhidao.baidu.com/question/458169192374974725.html)
- P2->P3: 虽然探究“哪一种损失函数引入到预训练语言模型中更适配下游任务”比较无聊,但比起排列组合各种网络结构,却不一定能获得好性能而言,前者似乎还行。
- P3->P4: 虽然prompt的定义很繁琐,但是如果有个方法可以帮你回答“BERT效果都那么好了 ,我还研究个啥“这个问题,那它也挺有吸引力。并且,Prompt Learning激活了很多新的研究场景,比如小样本学习,这显然可以成为那些GPU资源受限研究者的福音。当然,我理解Prompt Learning最重要的一个作用在于给我们prompt(提示)了NLP发展可能的核心动力是什么。
规律2的应用:
可以帮助我们区分“伪范式“与”真范式“。如果新的建模体系实现的代价过于复杂,或者是收益甚微,那么他可能不是比较有前景的范式了。
1.3 第四范式Prompt learning的相关问题
1.3.1 P4是什么,为什么会在现在发生?
Prompt Learning是指对输入文本信息按照特定模板进行处理,把任务重构成一个更能充分利用预训练语言模型处理的形式。
具体内容在第二部分进行讲解
1.3.2 Prompt Learning所涉及的技术似乎过去不少工作都有涉及?
没错,不管是对输入的模板化处理,还是任务重构的操作,这都不是什么新鲜的事情。在论文《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》的第9小节有很详细比较与Prompt Learning相关的一些(八个)“老“的研究话题,比如”Query Reformulation“,比如 “QA-based Task Reformulation”
1.3.3 既然过去的工作都有涉及,为什么现在的Prompt Learning是一个新范式?
其实如果我们看上面对Prompt Learning的表述,这里面隐含了个不容易被发现的假设,即
“预训练语言模型的知识真的很丰富,为了更好的利用它,我们愿意不惜以重构任务为代价(因为对任务重构本身涉及很多选择决策,需要人来参与)。
这说明,Prompt Learning 的范式里 “任务重构”目的非常明确,即更好的利用预训练语言模型。而这一点,就可以和过去“Query reformulation/QA-based Task reformulation“工作区分开。原因很简单,因为,那个时候的NLP技术还不存在一个这么强大的预训练语言模型让我们为了”迎合“它而去把任务进行重构。
1.3.4 Prompt Learning蕴含的假设(“预训练语言模型的知识真的很丰富,为了更好的利用它,我们愿意不惜以重构任务为代价)成立吗?
它不一定成立,尤其是在预训练语言模型比较弱的时候,比如,早期的一些上下文无关的词向量模型,为它而重构任务可能是一件得不偿失的事情(这同时也回答了上面一个问题,为什么Prompt Learning会在这时候入场)。而从BERT以来,这种上下文相关的预训练模型,他们不仅包含了丰富知识,另一个重要的点在于他们本身已经是个完整的小个体(比如,有输入层,特征提取层,输出层),这意味着在我们给不同下游任务设计模型的时候,拥有了这样一种可能性:不用设计新的网络层,而是完全利用预训练语言模型的网络结构。而为了达到这个目的需要做出一些改变,而这个改变就是利用prompt重构任务的输入。
1.3.5 Prompt Learning的主要研究点是什么?现有工作都做了哪些探讨?有价值的方向是什么?
话不多说,直接放图
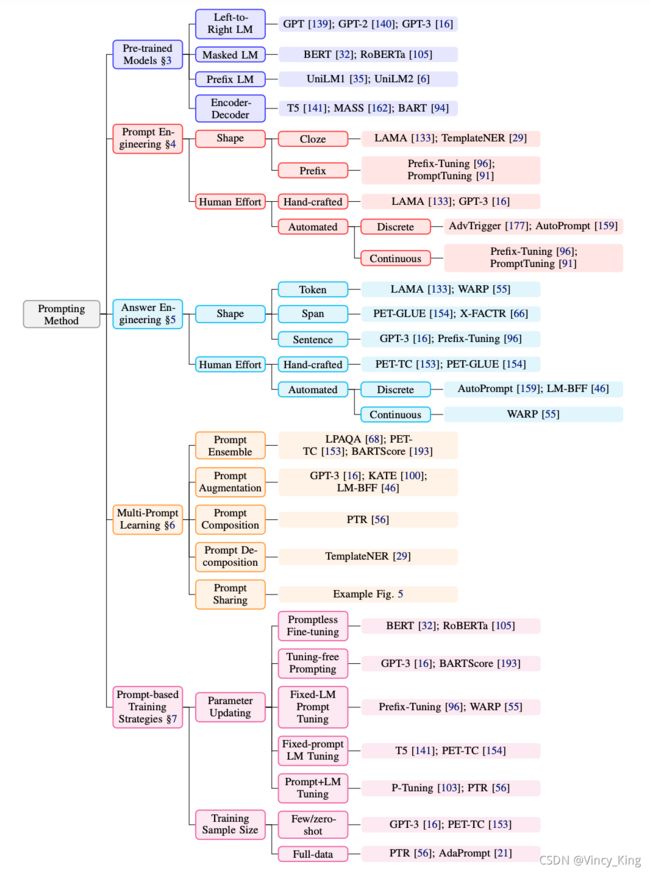
1.3.6 发生在第三个阶段的的语言模型Fine-tuning范式和第四个范式的Prompting范式有什么关系?
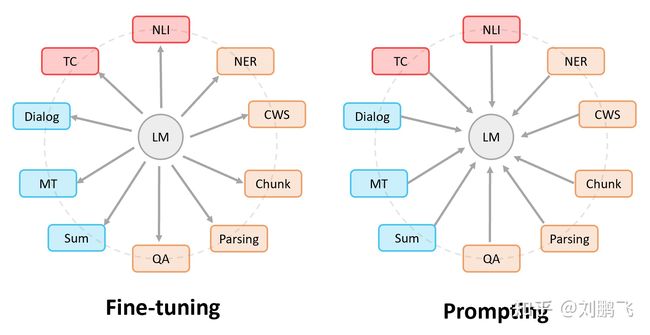
图中,圆形表示预训练语言模型,矩形框表示的是各种下游NLP任务。那么,我们就有这样一句话:大家都是希望让 预训练语言模型和下游任务靠的更近,只是实现的方式不一样,
**Fine-tuning中:是预训练语言模型“迁就“各种下游任务。**具体体现就是上面提到的通过引入各种辅助任务loss,将其添加到预训练模型中,然后继续pre-training,以便让其更加适配下游任务。总之,这个过程中,预训练语言模型做出了更多的牺牲。
**Prompting中,是各种下游任务“迁就“预训练语言模型。**具体体现也是上面介绍的,我们需要对不同任务进行重构,使得它达到适配预训练语言模型的效果。总之,这个过程中,是下游任务做出了更多的牺牲。
1.3.7 Prompt Learning 给了我们哪些Prompts (剧透了哪些NLP发展可能的核心动力)?
Prompting 本身不是目的,它是一种实现让下游任务和预训练语言模型更加接近的途径,如果我们有其它更好的方式,那就可以引领下一个范式。
2. 浅谈Prompt的前世今生
2.1 Prompt的产生和兴起
近几年来,有关预训练语言模型(PLM)的研究比比皆是,自然语言处理(NLP)也借着这股春风获得了长足发展。尤其是在2017-2019年间,研究者们的重心逐渐从传统task-specific的有监督模式转移到预训练上。基于预训练语言模型的研究思路通常是**“pre-train, fine-tune”**,即将PLM应用到下游任务上,在预训练阶段和微调阶段根据下游任务设计训练对象并对PLM本体进行调整。
随着PLM体量的不断增大,对其进行fine-tune的硬件要求、数据需求和实际代价也在不断上涨。除此之外,丰富多样的下游任务也使得预训练和微调阶段的设计变得繁琐复杂,因此研究者们希望探索出更小巧轻量、更普适高效的方法,Prompt就是一个沿着此方向的尝试。
2.2 Prompt的概念
在“pre-train+fine-tune”的范式中,有两个阶段:pre-train、fine-tune。为了能够让模型在下游任务的表现足够好,我们往往在pre-train阶段引入各种辅助任务loss,以便让其更加适配下游任务,继而达到目的。
在“prompt-based learning”的范式中,有三个阶段:pre-train、prompt、predict。为了能够让模型在下游任务的表现足够好,我们考虑在prompt阶段对下游任务进行重构,以便让其更加适配pre-train的语言模型,继而达到目的。
融入了Prompt的新模式大致可以归纳成”pre-train, prompt, and predict“,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model, 在文本情感分类任务中,对于 “I love this movie.” 这句输入,可以在后面加上prompt “The movie is ___” 这样的形式,然后让PLM用表示情感的答案填空如 “great”、“fantastic” 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。
因此,合适的prompt对于模型的效果至关重要。大量研究表明,prompt的微小差别,可能会造成效果的巨大差异。研究者们就如何设计prompt做出了各种各样的努力——自然语言背景知识的融合、自动生成prompt的搜索、不再拘泥于语言形式的prompt探索等等,笔者将会在第三节进行进一步讨论。
那么Prompt是如何对下游任务进行重构的呢?
Prompt刚刚出现的时候,还没有被叫做Prompt,是研究者们为了下游任务设计出来的一种输入形式或模板,它能够帮助PLM“回忆”起自己在预训练时“学习”到的东西,因此后来慢慢地被叫做Prompt了。
对于输入的文本 x x x,有函数 f p r o m p t ( x ) f_{prompt}(x) fprompt(x),将 x x x转换成prompt的形式 x ′ x' x′,即
x ′ = f p r o m o t ( x ) x'=f_{promot}(x) x′=fpromot(x)
该函数通常会进行两步操作:
- 使用一个模板,模板通常为一段自然语言,并包含两个空位置:一个用于填输入 x x x的位置 [ X ] [X] [X],一个用于填生成答案文本 z z z的位置 [ Z ] [Z] [Z]。
- 把输入 x x x填到 [ X ] [X] [X]的位置。
在文本情感分类任务中,假设输入是 x = x= x="I love this movie." 使用的模板则是"[X] Overall, it was a [Z] movie.“那么得到的 x ′ x' x′就应该是"I love this movie. Overall, it was a [Z] movie.”
在实际的研究中,prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。[X] 和[Z] 的位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。
另外,上面的例子中prompts都是有意义的自然语言,但实际上其形式并不一定要拘泥于自然语言。现有相关研究使用虚拟单词甚至直接使用向量作为prompt。
下一步会进行答案搜索,顾名思义就是LM寻找填在[Z]处可以使得分数最高的文本 z ^ \hat z z^。最后是答案映射。有时LM填充的文本并非任务需要的最终形式,因此要将此文本映射到最终的输出 y ^ \hat y y^。例如,在文本情感分类任务中,“excellent”, “great”, “wonderful” 等词都对应一个种类 “++”,这时需要将词语映射到标签再输出。
2.3 Prompt的设计方法
2.3.1 Prompt Shape
Prompt的形状主要指的是[X]和[Z]的位置和数量。上文提到cloze prompt和prefix prompt的区别,在实际应用过程中选择哪一种主要取决于任务的形式和模型的类别。cloze prompts和Masked Language Model的训练方式非常类似,因此对于使用MLM的任务来说cloze prompts更加合适;对于生成任务来说,或者使用自回归LM解决的任务,prefix prompts就会更加合适;Full text reconstruction models较为通用,因此两种prompt均适用。另外,对于文本对的分类,prompt模板通常要给输入预留两个空 [ X 1 ] [X_1] [X1] 和 [ X 2 ] 和[X_2] 和[X2]。
2.3.2 Manual Template Engineering
Prompt最开始就是从手工设计模板开始的。手工设计一般基于人类的自然语言知识,力求得到语义流畅且高效的模板。例如,Petroni等人在著名的LAMA数据集中为知识探针任务手工设计了cloze templates;Brown等人为问答、翻译和探针等任务设计了prefix templates。手工设计模板的好处是较为直观,但缺点是需要很多实验、经验以及语言专业知识,代价较大。
2.3.3 Automated Template Learning
为了解决手工设计模板的缺点,许多研究开始探究如何自动学习到合适的模板。自动学习的模板又可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。离散的主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续的则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning。
1. Discrete Prompts
自动生成离散Prompts指的是自动生成由自然语言的词组成的Prompt,因此其搜索空间是离散的。目前大致可以分成下面几个方法:
1) Prompt Mining. 该方法需要一个大的文本库支持,例如Wikipedia。给定输入 x x x和 y y y输出,要找到 x x x和 y y y之间的中间词或者依赖路径,然后选取出现频繁的中间词或依赖路径作为模板,即“[X] middle words [Z]”。
2) Prompt Paraphrasing. Paraphrasing-based方法是基于释义的,主要采用现有的种子prompts(例如手动构造),并将其转述成一组其他候选prompts,然后选择一个在目标任务上达到最好效果的。一般的做法有:将提示符翻译成另一种语言,然后再翻译回来;使用同义或近义短语来替换等。
3) Gradient-based Search. 梯度下降搜索的方法是在单词候选集里选择词并组合成prompt,利用梯度下降的方式不断尝试组合,从而达到让PLM生成需要的词的目的。
4) Prompt Generation. 既然Prompt也是一段文本,那是否可以用文本生成的方式来生成Prompt呢?该类方法就是将标准的自然语言生成的模型用于生成prompts了。例如,Gao等人将T5引入了模板搜索的过程,让T5生成模板词;Ben-David 等人提出了一种域自适应算法,训练T5为每个输入生成一种唯一的域相关特征,然后把输入和特征连接起来组成模板再用到下游任务中。
5) Prompt Scoring. Davison等人在研究知识图谱补全任务的时候为三元组输入(头实体,关系,尾实体)设计了一种模板。首先人工制造一组模板候选,然后把相应的[X]和[Z]都填上成为prompts,并使用一个双向LM给这些prompts打分,最后选取其中的高分prompt。
2. Continuous Prompts
既然构造Prompt的初衷是能够找到一个合适的方法,让PLM更“听话”地得出我们想要的结果,那就不必把prompt的形式拘泥于人类可以理解的自然语言了,只要机器可以理解就好了。因此,还有一些方法探索连续型prompts——直接作用到模型的embedding空间。连续型prompts去掉了两个约束条件:
- 模板中词语的embedding可以是整个自然语言的embedding,不再只是有限的一些embedding。
- 模板的参数不再直接取PLM的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整。
目前的连续prompts方法大致可以分为下面几种:
1) Prefix Tuning. Prefix Tuning最开始由Li等人提出,是一种在输入前添加一串连续的向量的方法,该方法保持PLM的参数不动,仅训练合适的前缀(prefix)。
类似地,Lester等人在输入序列前面加上特殊的token来组成一个模板,然后直接调整这些token的embedding。 和上面的Prefix Tuning的方法相比,他们的方法相对来说参数较少,因为没有在每一层网络中引入额外的参数。
2) Tuing Initialized with Discrete Prompts. 这类方法中连续prompts是用已有的prompts初始化的,已有的prompts可以是手工设计的,也可以是之前搜索发现的离散prompts。Zhong 等人先用一个离散prompt搜索方法定义了一个模板,然后基于该模板初始化虚拟的token,最后微调这些token的embedding以提高准确率。
3) Hard-Soft Prompt Hybrid Tuning. 这类方法可以说是手工设计和自动学习的结合,它通常不单纯使用可学习的prompt模板,而是在手工设计的模板中插入一些可学习的embedding。Liu等人提出了“P-Tuning”方法,通过在input embedding中插入可训练的变量来学习连续的prompts。并且,该方法使用BiLSTM的输出来表示prompt embeddings,以便让prompt tokens之间有一定的交互。P-tuning还引入了任务相关的anchor tokens(例如关系提取中的“capital”)来进一步提高效果,这些anchor tokens不参与后续的调优。Han等人提出了Prompt Tunning with Rules(PTR)方法,使用手工指定的子模板按照逻辑规则组装成完整的模板。为了增强生成的模板的表示能力,该方法还插入了几个虚拟token,这些虚拟token的embeddings可以和PLM的参数一起被调整,PTR的模板token既有实际token也有虚拟token 。实验结果证明了该方法在关系分类任务中的有效性。
2.4 Prompt-based Training Strategies
在很多情况下,prompt-based learning是无需显式训练的,也即,可以做到zero-shot learning。不过,依然有一些情况,需要对模型进行训练,例如,某些自动生成prompt的方式中,包含着待训练的prompt params。
依据不同部分的参数是否需要训练,下图总结了5种常用的训练策略:
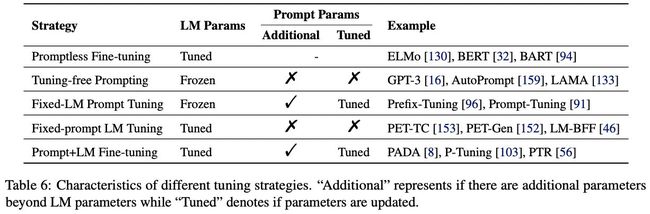
2.5 Prompt面临的挑战
尽管Prompt相关研究搞得如火如荼,但目前仍存在许多问题,值得研究者们去探索。
- Prompt的设计问题。目前使用Prompt的工作大多集中育分类任务和生成任务,其它任务则较少,因为如何有效地将预训练任务和prompt联系起来还是一个值得探讨的问题。另外,模板和答案的联系也函待解决。模型的表现同时依赖于使用的模板和答案的转化,如何同时搜索或者学习出两者联合的最好效果仍然很具挑战性。
- Prompt的理论分析和可解释性。尽管Prompt方法在很多情况下都取得了成功,但是目前prompt-based learning的理论分析和保证还很少,使得人们很难了解Prompt为什么能达到好的效果,又为什么在自然语言中意义相近的Prompt有时效果却相差很大。
- Prompt在PLM debias方面的应用。由于PLM在预训练过程中见过了大量的人类世界的自然语言,所以很自然地受到了影响。拿一个简单的例子来说,可能不太恰当,比如说训练语料中有很多的"The capital of China is “Beijing.”,导致模型认为下次看到"capital" 的时候都会预测出"Beijing",而不是着重看到底是哪个国家的首都。在应用的过程中,Prompt还暴露了PLM学习到的很多其它bias,比如种族歧视、恐怖主义、性别对立等等。已有相关研究关注是否可以利用Prompt来对这些bias进行修正,但还处在比较初级的阶段,这也会是一个值得研究的方向。
参考
知乎 闵映乾
知乎 刘鹏飞
知乎 Pikachu5808
写在最后
“弟弟弟弟,掂量自己
生活怎能,纸上谈兵”
完成这篇文章的时候,是四字弟弟二十又一的生日,一路走来,他的努力,他的成就,千纸鹤们都看在眼里。
记得双十一前夕,跑完步在操场看着手机里弟弟的天猫舞台和疯狂地弹幕,一个人在健身器材面前傻傻地露出姨母般的笑容,我不知道他都经历过什么,但我很庆幸,他都坚持下来了,真的,刚开始是有多少不看好不相信的声音和质疑,但千纸鹤们很给力,四叶草们很团结。
天天老师曾经问过我:“你有没有偶像?”
我毫不犹豫地说了千玺,“与其说是偶像,不如称为信仰。”
从喜欢上弟弟,喜欢上TFboys,至今,也七年有余。不知不觉,对我来说,千玺已经逐渐成为了一种信仰,无论是中考、高考,还是现在,低落难过时能够给予我鼓励的人中,也包括千玺,那是一种来自精神上的动力。
“千玺,我知道,你在努力成为优秀的自己,而我也会努力,愿我们都能在各自的领域闪闪发光,变得更加优秀!”