【论文翻译】KGAT: Knowledge Graph Attention Network for Recommendation
**【论文翻译】KGAT: Knowledge Graph Attention Network for Recommendation**
-
- 论文题目:KGAT: Knowledge Graph Attention Network for Recommendation
- 论文来源:[KGAT: Knowledge Graph Attention Network for Recommendation](http://arxiv.org/abs/1905.07854v1)
- 翻译人:BDML@CQUT实验室
- Abstract
- 摘要
- Introduction
- 引言
- METHODOLOGY
-
- Embedding Layer
- Attentive Embedding Propagation Layers
- Model Prediction
-
- Optimization
- 模型
-
- 嵌入层
- 注意力传播层
- 预测层
- 优化
- EXPERIMENTS
-
- Dataset Description
- 数据集
-
- Evaluation Metrics.
- Baselines.
- Parameter Settings.
- 实验设置
- Result
-
- Overall Comparison
- 实验结果
-
- 总体比较
- Performance Comparison w.r.t. Interaction Sparsity
- 不同交互稀疏度的比较
论文题目:KGAT: Knowledge Graph Attention Network for Recommendation
论文来源:KGAT: Knowledge Graph Attention Network for Recommendation
翻译人:BDML@CQUT实验室
KGAT: Knowledge Graph Attention Network for Recommendation
Xiang Wang, Xiangnan He, Yixin Cao, Mneg Liu, Tat-Seng Chua
知识图谱注意力推荐网络
Xiang Wang, Xiangnan He, Yixin Cao, Mneg Liu, Tat-Seng Chua
Abstract
To provide more accurate, diverse, and explainable recommendation,it is compulsory to go beyond modeling user-item interactions and take side information into account. Traditional methods like factorization machine (FM) cast it as a supervised learning problem,which assumes each interaction as an independent instance with side information encoded. Due to the overlook of the relations among instances or items (e.g., the director of a movie is also an actor of another movie), these methods are insufficient to distill the collaborative signal from the collective behaviors of users.
In this work, we investigate the utility of knowledge graph
(KG), which breaks down the independent interaction assumption by linking items with their attributes. We argue that in such a hybrid structure of KG and user-item graph, high-order relations — which connect two items with one or multiple linked attributes — are an essential factor for successful recommendation. We propose a new method named Knowledge Graph Attention Network (KGAT) which explicitly models the high-order connectivities in KG in an end-to-end fashion. It recursively propagates the embeddings from a node’s neighbors (which can be users, items, or attributes) to refine the node’s embedding, and employs an attention mechanism to discriminate the importance of the
neighbors. Our KGAT is conceptually advantageous to existing KG-based recommendation methods, which either exploit highorder relations by extracting paths or implicitly modeling them with regularization. Empirical results on three public benchmarks show that KGAT significantly outperforms state-of-the-art methods like Neural FM [11] and RippleNet [29]. Further studies verify the efficacy of embedding propagation for high-order relation modeling and the interpretability benefits brought by the attention mechanism. We release the codes and datasets at https://github. com/xiangwang1223/knowledge_graph_attention_network.
摘要
推荐系统的成功使其在网络应用中越来越广泛,从搜索引擎、电子商务到社交媒体和新闻门户网站——毫不夸张地说,几乎所有向用户提供内容的服务都配备了推荐系统.为了从用户行为数据的关键(和广泛可用的)来源中预测用户偏好,许多工作都致力于研究协同过滤(CF)[12,13,32].尽管CF方法具有有效性和通用性,但它无法对诸如项属性、用户属性文件和上下文之类的边信息进行建模[30,31],因此在用户和项目有很少交互的稀疏情况下性能很差.为了集成这些信息,一个常见的例子是将它们与用户ID和项目ID一起转换为一个通用的特征向量,并将它们输入到一个监督学习(SL)模型中以预测得分.这种基于SL的推荐模型已经在工业界广泛应用[7,24,40],一些有代表性的模型包括因子分解机(FM)[23]、NFM(神经FM)[11]、广度和深度[7]和xDeepFM[18]等.
尽管这些方法提供了很强的性能,但其缺点是它们将每个交互建模为一个独立的数据实例,而不考虑它们之间的关系。这使得它们不能从用户的集体行为中提取基于属性的协作信号。如图1所示,用户u1和电影i1之间有一个交互,由e1导演。CF方法同样关注i1(即u4和u5)的相似用户的历史;而SL方法则强调属性为e1(即i2)的相似项。显然,这两类信息不仅是推荐信息的补充,同时也在目标用户和项目之间形成一种高阶关系。然而,现有的SL方法不能将其统一起来,没有考虑高阶连通性,如黄圈内代表观看由e1导演的电影的用户,灰色圈内表示与e1有其他共同关系的项目。
1、引入一种高阶关系来提供更多的用户-项目间的补充信息
Introduction
The success of recommendation system makes it prevalent in Web applications, ranging from search engines, E-commerce, to social media sites and news portals — without exaggeration, almost every service that provides content to users is equipped with a recommendation system. To predict user preference from the key (and widely available) source of user behavior data, much research effort has been devoted to collaborative filtering (CF) [12, 13, 32]. Despite its effectiveness and universality, CF methods suffer from
the inability of modeling side information [30, 31], such as item attributes, user profiles, and contexts, thus perform poorly in sparse situations where users and items have few interactions. To integrate such information, a common paradigm is to transform them into a generic feature vector, together with user ID and item ID, and feed them into a supervised learning (SL) model to predict the score. Such a SL paradigm for recommendation has been widely deployed in industry [7, 24, 40], and some representative models include factorization machine (FM) [23], NFM (neural FM) [11],Wide&Deep [7], and xDeepFM [18], etc.
Although these methods have provided strong performance, a deficiency is that they model each interaction as an independent data instance and do not consider their relations. This makes them insufficient to distill attribute-based collaborative signal from the collective behaviors of users. As shown in Figure 1, there is an interaction between user u1 and movie i1, which is directed by the person e1. CF methods focus on the histories of similar users who also watched i1, i.e., u4 and u5; while SL methods emphasize the similar items with the attribute e1, i.e., i2. Obviously, these two types
of information not only are complementary for recommendation,
引言
为了解决基于特征的SL模型的局限性,提出了一种基于项目附加信息图的解决方案。知识图[3,4],考虑到构建的预测模型。将知识图和用户项图的混合结构称为协同知识图(CKG),如图1所示。成功推荐的关键是充分利用CKG中的高阶关系,例如,远程连接:
- u1→i1→e1→i2→{u2,u3}
- u1→i1→e1→{i3,i4}
上面的表示分别代表通往黄色和灰色圆圈的道路。然而,要利用这样的高阶信息,也存在挑战:1)与目标用户具有高阶关系的节点随着阶数的增加而急剧增加,这给模型带来了计算过载;2)高阶关系对预测的贡献是不平等的,这需要模型仔细地权衡(或选择)它们。
 最近有几项试图利用CKG结构进行推荐的工作,大致可分为两类:基于路径的[14,25,29,33,37,39]和基于正则化的[5,15,33,38]:
最近有几项试图利用CKG结构进行推荐的工作,大致可分为两类:基于路径的[14,25,29,33,37,39]和基于正则化的[5,15,33,38]: - 基于路径的方法提取带有高阶信息的路径,并将其输入到预测模型中。为了处理两个节点之间的大量路径,它们要么应用路径选择算法来选择突出的路径[25,33],要么定义元路径模式来约束路径[14,36]。这种两阶段方法的一个问题是,路径选择的第一阶段对最终性能有很大的影响,但并没有针对推荐目标进行优化。此外,定义有效的元路径需要领域知识,对于具有不同类型关系和实体的复杂KG来说,这可能是相当劳动密集的,因为必须定义许多元路径才能保持模型的保真度.
- 基于正则化的方法设计额外的损失项来捕获KG结构,以正则化推荐模型学习,例如,KTUP[5]和CFKG[1]使用共享项嵌入联合训练完成推荐和KG两项任务,这些方法没有直接将高阶关系插入到为推荐而优化的模型中,而是以隐式方式对它们进行编码。由于缺乏显式的建模,既不能保证捕捉到长程关联,也不能解释高阶建模的结果。
考虑到现有方法的局限性,我们认为开发一个能够以高效、明确且端到端的方式利用KG中高阶信息的模型至关重要。为此,我们从图神经网络的最新发展中得到启发[9,17,28],这些网络具有实现目标的潜力,但是对于基于KG的推荐还没有进行太多的探索。具体地说,我们提出了一种新的知识图注意力网络(KGAT)方法,它具有两种设计来相应地解决高阶关系建模中的挑战:1)递归嵌入传播,它基于邻域的嵌入更新节点的嵌入,并递归地执行这种嵌入传播以捕获线性时间复杂性中的高阶连接;和2)基于注意的聚集,它利用神经注意机制[6,27]来学习传播过程中每个邻居的权重,使得级联传播的注意权重能够揭示高阶连接的重要性。与基于路径的方法相比,KGAT避免了路径物化的繁琐过程,因而使用起来更加高效和方便;与基于正则化的方法相比,KGAT直接将高阶关系引入到预测模型中,因此,所有相关参数都是为优化推荐目标而定制的。
本文工作的贡献总结如下: - 本文强调了在协作知识图中显式建模高阶关系的重要性,以提供更好的项目辅助信息推荐。
- 本文开发了一种新的方法KGAT,它在图神经网络框架下,以显式和端到端的方式实现高阶关系建模。
- 在三个公共基准上进行了广泛的实验,证明了KGAT在理解高阶关系重要性方面的有效性及其可解释性。
用到的技术有GCN、知识图谱、embedding、attention
METHODOLOGY
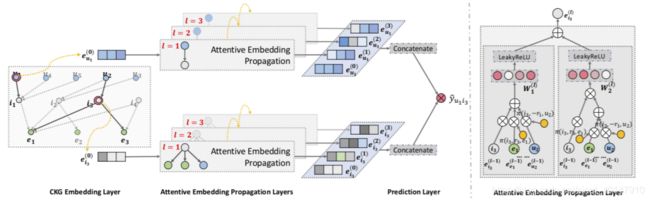
We now present the proposed KGAT model, which exploits highorder relations in an end-to-end fashion. Figure 2 shows the model framework, which consists of three main components: 1) embedding layer, which parameterizes each node as a vector by preserving the structure of CKG; 2) attentive embedding propagation layers, which recursively propagate embeddings from a node’s neighbors to update its representation, and employ knowledge-aware attention mechanism to learn the weight of each neighbor during a propagation; and 3) prediction layer, which aggregates the representations of a user and an item from all propagation layers, and outputs the predicted matching score.
Embedding Layer
Knowledge graph embedding is an effective way to parameterize entities and relations as vector representations, while preserving the graph structure. Here we employ TransR [19], a widely used method, on CKG. To be more specific, it learns embeds each entity and relation by optimizing the translation principle ehr + er = etr, if a triplet (h,r,t) exists in the graph. Herein, eh, et ∈ Rd and er ∈ Rk are the embedding for h, t, and r, respectively; and ehr, etr are the projected representations of eh and et in the relation r’s space.
Hence, for a given triplet (h,r,t), its plausibility score (or energy score) is formulated as follows:
![]()
where Wr ∈ Rk×d is the transformation matrix of relation r, which projects entities from the d-dimension entity space into the kdimension relation space. A lower score of д(h,r,t) suggests that the triplet is more likely to be true true, and vice versa.
The training of TransR considers the relative order between
valid triplets and broken ones, and encourages their discrimination through a pairwise ranking loss:
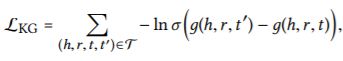
where T = {(h,r,t,t′)|(h,r,t) ∈ G, (h,r,t′) ̸∈ G}, and (h,r,t′) is a
broken triplet constructed by replacing one entity in a valid triplet randomly; σ(·) is the sigmoid function. This layer models the entities and relations on the granularity of triples, working as a regularizer and injecting the direct connections into representations, and thus increases the model representation ability.
Attentive Embedding Propagation Layers
Next we build upon the architecture of graph convolution
network [17] to recursively propagate embeddings along highorder connectivity; moreover, by exploiting the idea of graph attention network [28], we generate attentive weights of cascaded propagations to reveal the importance of such connectivity. Here we start by describing a single layer, which consists of three components: information propagation, knowledge-aware attention, and information aggregation, and then discuss how to generalize it to multiple layers.
Information Propagation: One entity can be involved in
multiple triplets, serving as the bridge connecting two triplets
and propagating information. Taking ![]()
and
![]()
as an example, item i2 takes attributes e1 and e2 as inputs to enrich its own features, and then contributes user u2’s preferences, which can be simulated by propagating information from e1 to u2. We build upon this intuition to perform information propagation between an entity and its neighbors.
Considering an entity h, we use Nh = {(h,r,t)|(h,r,t) ∈ G} to
denote the set of triplets where h is the head entity, termed egonetwork[21]. To characterize the first-order connectivity structure of entity h, we compute the linear combination of h’s ego-network:
![]()
where π(h,r,t) controls the decay factor on each propagation on edge (h,r,t), indicating how much information being propagated from t to h conditioned to relation r.
Knowledge-aware Attention: We implement π(h,r,t) via relational attention mechanism, which is formulated as follows:
![]()
where we select tanh [28] as the nonlinear activation function. This makes the attention score dependent on the distance between eh and et in the relation r’s space, e.g., propagating more information for closer entities. Note that, we employ only inner product on these representations for simplicity, and leave the further exploration of the attention module as the future work.
Hereafter, we normalize the coefficients across all triplets
connected with h by adopting the softmax function:
![]()
As a result, the final attention score is capable of suggesting
which neighbor nodes should be given more attention to capture collaborative signals. When performing propagation forward, the attention flow suggests parts of the data to focus on, which can be treated as explanations behind the recommendation.
Distinct from the information propagation in GCN [17] and
GraphSage [9] which set the discount factor between two nodes as 1/p |Nh||Nt| or 1/|Nt|, our model not only exploits the proximity structure of graph, but also specify varying importance of neighbors. Moreover, distinct from graph attention network [28] which only takes node representations as inputs, we model the relation er between eh and et, encoding more information during propagation.
Model Prediction
After performing L layers, we obtain multiple representations
for user node u, namely {e(1)u , · · · , e(L)u }; analogous to item node i, {e(1)i, · · · , e(L)i } are obtained. As the output of the l-th layer is the message aggregation of the tree structure depth of l rooted at u (or i) as shown in Figure 1, the outputs in different layers emphasize the connectivity information of different orders. We hence adopt the layer-aggregation mechanism [34] to concatenate the representations at each step into a single vector, as follows:
![]()
where ∥ is the concatenation operation. By doing so, we not
only enrich the initial embeddings by performing the embedding propagation operations, but also allow controlling the strength of propagation by adjusting L.
Finally, we conduct inner product of user and item representations, so as to predict their matching score:
![]()
Optimization
To optimize the recommendation model, we opt for the BPR
loss [22]. Specifically, it assumes that the observed interactions,which indicate more user preferences, should be assigned higher prediction values than unobserved ones:
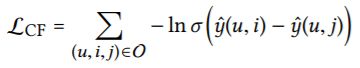
where O = {(u,i, j)|(u,i) ∈ R+, (u, j) ∈ R−} denotes the training set,R+ indicates the observed (positive) interactions between useru and item j while R− is the sampled unobserved (negative) interaction set; σ(·) is the sigmoid function.
Finally, we have the objective function to learn Equations (2)
and (13) jointly, as follows:
![]()
where Θ = {E, Wr,∀l ∈ R, W(l)1, W(l)2,∀l ∈ {1, · · · , L}} is the model parameter set, and E is the embedding table for all entities and relations; L2 regularization parameterized by λ on Θ is conducted to prevent overfitting. It is worth pointing out that in terms of model size, the majority of model parameters comes from the entity embeddings,which is almost identical to that of FM; the propagation layer weights are lightweight (e.g., 5.4 thousand for the tower structure of three layers, i.e., 64 − 32 − 16 − 8, on the Amazon dataset).
模型
本文提出了KGAT模型,它利用高阶关系以端到端的方式进行训练。图2显示了模型框架,它由三个主要部分组成:1)嵌入层,通过保留CKG的结构将每个节点参数化为一个向量;2)注意力嵌入传播层,递归地从节点的邻居传播嵌入以更新其表示,并使用知识感知关注在传播过程中学习每个邻居的权重的机制;以及3)预测层,该预测层聚合来自所有传播层的用户和项目的表示,并输出预测的匹配得分。

嵌入层
知识图谱嵌入是一种在保持图结构不变的情况下,将实体和关系参数化为向量表示的有效方法。对CKG使用TransR[19],这是一个广泛被使用的方法。更具体地说,如果图中存在一个三元组(h,r,t),它通过优化erh+er≈ert的平移原理来学习嵌入每个实体和关系。这里,eh,et∈Rd,er∈Rk,三者分别是h,t,r的嵌入;erh,ert是在关系r空间中eh和et的投影表示。因此,对于给定的三元组(h,r,t),其似然性得分(或能量得分):
![]()
其中Wr∈Rk×d是关系变换矩阵,它将实体从d维实体空间投影到k维关系空间,分数(h,r,t)越低表明三元组更可能是真的,反之亦然.
TransR的训练考虑了有效三元组和无效三元组之间的相对顺序,并用BPR损失来对两者进行区分:
![]()
其中,T={(h,r,t,t‘)|(h,r,t)∈G,(h,r,t‘) ∉G},(h,r,t‘)是通过随机替换有效三元组中的一个实体而构造的无效三元组;σ(·)是sigmoid函数。该层在三元组的粒度上对实体和关系进行建模,充当正则化器并将直接连接注入到表示中,从而提高了模型表示能力.
注意力传播层
接下来,我们在图卷积网络[17]的基础上,沿着高阶连通性递归地传播嵌入;此外,通过利用图注意力网络[28]的思想,我们生成级联传播的关注权重,以揭示这种连通性的重要性。在这里,我们首先描述一个由三个部分组成的单层:信息传播、知识感知关注和信息聚合,然后讨论如何将其推广到多层。
**信息传播:**一个实体可以参与多个三元组,作为连接两个三元组和传播信息的桥梁,基于此在一个实体和它的邻居之间进行信息传播。考虑到一个实体h,我们使用Nh={(h,r,t)|(h,r,t)∈G}来表示其中h是头实体的三元组,称为自我网络[21]。为了刻画实体h的一阶连通结构,我们计算了h的自我网络的线性组合:
![]()
其中π(h,r,t)控制着在三元组(h,r,t)上每次传播的衰减因子,指示从t到h传播的信息有多少是以关系r为条件的。
**知识感知注意:**通过注意力机制来计算π(h,r,t):
![]()
选择tanh[28]作为非线性激活函数。这使得注意力得分依赖于关系r空间中eh和et之间的距离,例如,为更接近的实体传播更多的信息。为了简单起见,我们只在这些表示上使用内积,并将注意力模块的进一步探索留作以后的工作。此后,通过采用softmax函数对与h相连的所有三元组的系数进行规范化:
![]()
因此,最后的注意得分能够提示哪些邻居节点应该给予更多的注意来捕获协作信号。当执行向前传播时,注意流建议关注部分数据,这可以视为建议背后的解释。
与GCN[17]和GraphSage[9]中将两个节点之间的衰减因子设置为1/ | Nh | Nt |或1/| Nt |的信息传播不同,我们的模型不仅利用了图的邻近结构,而且还指定了邻域的不同重要性。此外,与文献[28]仅以节点表示为输入的图注意网络不同,我们建立了节点之间的关系er模型,对传播过程中的更多信息进行编码。
**信息聚合:**最后将实体表示e h及其自我网络表征eNh聚合为实体h的新表达-更正式地说,eh(1)=f(eh,eNh)。我们使用以下三种聚合器实现f(·):
- GCN聚合器[17]将两个表示相加并应用非线性变换:

其中,我们将激活函数设为LeakyReLU[20];W∈Rd′×d是可训练权重矩阵,用来提取有用的传播信息,d′是变换大小。 - GraphSage聚合器[9]拼接两个表示,然后是非线性转换:
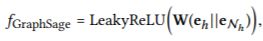
其中||是拼接操作. - 双交互聚合器,考虑eh和eNh之间的两种特征交互:

W1,W2∈Rd′×d为可训练权重矩阵,⊙表示元素乘积。与GCN和GraphSage聚合器不同,我们还对eh和eNh之间的特征交互进行了编码,这使得传播的信息对eh和eNh之间的关联性敏感,例如,从相似的实体传递更多的消息.
总之,嵌入传播层的优点在于显式地利用一阶连接信息来关联用户、项和知识实体表示。
**高阶传播:**可以进一步堆叠更多的传播层来探索高阶连接性信息,收集从更高跳邻居传播的信息。更正式地说,在第l步中,我们递归地将实体的表示形式表示为:
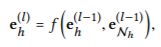
其中,在l-自我网络中为实体h传播的信息定义:

et(l-1)是从先前的信息传播步骤生成的实体t的表示,它存储来自其(l-1)跳邻居的信息;eh(0)集作为初始信息传播迭代的eh。它进一步有助于实体h在层l上的表示。因此,在嵌入传播过程中,可以捕获高阶连接。显然,高阶嵌入传播可以将基于属性的协作信号无缝地注入到表示学习的过程中。
预测层
在执行L层之后,我们获得了用户节点u的多层表示,即{eu(1),··,eu(L)};类似于项目节点i,{ei(1),···,ei(L)}。由于第l层的输出是图1所示根在u(或i)处的l层树结构深度的消息聚合,因此不同层的输出强调不同阶的连接信息。因此,我们采用层聚合机制[34]将每一步的表示连接成一个向量:
![]()
其中||是拼接操作,通过这样做,我们不仅可以通过执行嵌入传播操作来丰富初始嵌入,还可以通过调整L来控制传播强度。
最后,我们对用户和项目表示进行内积,以预测它们的匹配得分:![]()
优化
为了优化推荐模型,我们选择BPR损失[22]。具体地说,它假设观察到的交互(表示更多的用户偏好)应分配比未观察到的更高的预测值:
式中O={(u,i,j)|(u,i)∈R+,(u,j)∈R-}表示训练集,R+表示用户u和项目j之间观察到的(正)交互作用,R-是采样未观察到的(负)交互作用集;σ(·)是sigmoid激活函数。
最后,我们得到了共同学习的目标函数:
![]()
式中,Θ={E,W r,∀l∈R,W1(l),W2(l),∀l∈{1,····,L}是模型参数集,E是所有实体和关系的嵌入表;在Θ上进行由λ参数化的L2正则化以防止过度拟合。值得指出的是模型大小,大多数模型参数来自实体嵌入(例如,实验Amazon数据集上的650万),这几乎与FM相同;传播层权重是轻量级的(例如,Amazon数据集上的三层塔结构,即64-32-16-8,为5400)。
我们对LKG和LCF进行了交叉优化,采用小批量Adam[16]对嵌入损耗和预测损耗进行了优化。Adam是一种应用广泛的优化算法,它能够自适应地控制学习速率和梯度的绝对值。特别地,对于一批随机抽样的节点(h,r,t,t′),我们更新所有节点的嵌入;此后,我们随机抽样一批(u,i,j),在传播L步后检索它们的表示,然后使用预测损失的梯度更新模型参数。
EXPERIMENTS
Dataset Description
To evaluate the effectiveness of KGAT, we utilize three benchmark datasets: Amazon-book, Last-FM, and Yelp2018, which are publicly accessible and vary in terms of domain, size, and sparsity.
Amazon-book: Amazon-review is a widely used dataset for
product recommendation [10]. We select Amazon-book from this collection. To ensure the quality of the dataset, we use the 10-core setting, i.e., retaining users and items with at least ten interactions.
Last-FM: This is the music listening dataset collected from Last.fm online music systems. Wherein, the tracks are viewed as the items. In particular, we take the subset of the dataset where the timestamp is from Jan, 2015 to June, 2015. We use the same 10-core setting in order to ensure data quality.
Yelp2018: This dataset is adopted from the 2018 edition of the Yelp challenge. Here we view the local businesses like restaurants and bars as the items. Similarly, we use the 10-core setting to ensure that each user and item have at least ten interactions.
Besides the user-item interactions, we need to construct item
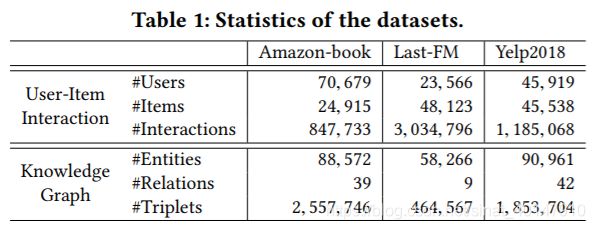
knowledge for each dataset. For Amazon-book and Last-FM, we map items into Freebase entities via title matching if there is a mapping available. In particular, we consider the triplets that are directly related to the entities aligned with items, no matter which role (i.e., subject or object) it serves as. Distinct from existing knowledgeaware datasets that provide only one-hop entities of items, we also take the triplets that involve two-hop neighbor entities of items into consideration. For Yelp2018, we extract item knowledge from the local business information network (e.g., category, location, and attribute) as KG data. To ensure the KG quality, we then preprocess the three KG parts by filtering out infrequent entities (i.e., lowever than 10 in both datasets) and retaining the relations appearing in at least 50 triplets. We summarize the statistics of three datasets in Table 1 and publish our datasets at https://github.com/xiangwang1223/knowledge_graph_attention_network.
For each dataset, we randomly select 80% of interaction history of each user to constitute the training set, and treat the remaining as the test set. From the training set, we randomly select 10% of interactions as validation set to tune hyper-parameters. For each observed user-item interaction, we treat it as a positive instance, and then conduct the negative sampling strategy to pair it with one negative item that the user did not consume before.
数据集
为了评估KGAT的有效性,我们使用了三个基准数据集:Amazon book、Last FM和Yelp2018,这些数据集是可以公开访问的,并且在域、大小和稀疏性方面有所不同。
Amazon-book:亚马逊网站评是一个广泛使用的产品推荐数据集[10],我们从中选择亚马逊图书评论信息。为了确保数据集的质量,我们使用10个核心设置,即保留至少有10个交互的用户和项。
Last FM:Last FM在线音乐系统。其中,轨迹被视为项,我们取数据集的子集,时间戳是从2015年1月到2015年6月,我们为了确保数据质量使用相同的10核设置。
Yelp2018:该数据集取自2018年的Yelp比赛。将当地的餐馆和酒吧等企业视为商品,类似地,我们使用10核设置来确保每个用户和项至少有10个交互。
除了用户-项目交互之外,我们还需要为每个数据集构造项目知识。对于Amazon book和Last FM,如果有可用的映射,我们通过标题匹配将项目映射到Freebase实体中。特别是,我们考虑与与项对齐的实体直接相关的三元组,不管它充当哪个角色(即主体或对象)。与现有只提供项的一跳实体的知识感知数据集不同,我们还考虑了包含项的两跳邻居实体的三元组。对于Yelp2018,我们从本地业务信息网络(如类别、位置和属性)中提取项目知识作为KG数据。为了保证KG的质量,我们通过过滤掉不经常出现的实体(即两个数据集中低于10个)并保留至少50个三元组中出现的关系,对这三个KG部分进行预处理。如表1所示。

对于每个数据集,我们随机选择每个用户80%的交互历史来构成训练集,并将剩余的作为测试集。从训练集中,我们随机选择10%的交互作为验证集来优化超参数。对于每个观察到的用户项交互,我们将其视为一个正实例,然后执行负抽样策略,将其与用户以前未消费的一个负项配对。
Evaluation Metrics.
For each user in the test set, we treat all the items that the user has not interacted with as the negative items. Then each method outputs the user’s preference scores over all the items, except the positive ones in the training set. To evaluate
the effectiveness of top-K recommendation and preference ranking, we adopt two widely-used evaluation protocols [13, 35]: recall@K and ndcg@K. By default, we set K = 20. We report the average metrics for all users in the test set.
Baselines.
To demonstrate the effectiveness, we compare our proposed KGAT with SL (FM and NFM), regularization-based (CFKG and CKE), path-based (MCRec and RippleNet), and graph
neural network-based (GC-MC) methods, as follows:
• FM [23]: This is a bechmark factorization model, where considers the second-order feature interactions between inputs. Here we treat IDs of a user, an item, and its knowledge (i.e., entities connected to it) as input features.
• NFM [11]: The method is a state-of-the-art factorization model, which subsumes FM under neural network. Specially, we employed one hidden layer on input features as suggested in [11].
• CKE [38]: This is a representative regularization-based method, which exploits semantic embeddings derived from TransR [19] to enhance matrix factorization [22].
• CFKG [1]: The model applies TransE [2] on the unified graph including users, items, entities, and relations, casting
the recommendation task as the plausibility prediction of
(u, Interact,i) triplets.
• MCRec [14]: This is a path-based model, which extracts qualified meta-paths as connectivity between a user and an item.
• RippleNet [29]: Such model combines regularization- and pathbased methods, which enrich user representations by adding that of items within paths rooted at each user.
• GC-MC [26]: Such model is designed to employ GCN [17]
encoder on graph-structured data, especially for the user-item
bipartite graph. Here we apply it on the user-item knowledge
graph. Especially, we employ one graph convolution layers as
suggested in [26], where the hidden dimension is set equal to the embedding size.
Parameter Settings.
We implement our KGAT model in Tensorflow. The embedding size is fixed to 64 for all models, except RippleNet 16 due to its high computational cost. We optimize all models with Adam optimizer, where the batch size is fixed at 1024.
The default Xavier initializer [8] to initialize the model parameters. We apply a grid search for hyper-parameters: the learning rate is tuned amongst {0.05, 0.01, 0.005, 0.001}, the coefficient of L2 normalization is searched in {10−5, 10−4, · · · , 101, 102}, and the dropout ratio is tuned in {0.0, 0.1, · · · , 0.8} for NFM, GC-MC, and KGAT. Besides, we employ the node dropout technique for GC-MC and KGAT, where the ratio is searched in {0.0, 0.1, · · · , 0.8}. For MCRec, we manually define several types of user-item-attributeitem
meta-paths, such as user-book-author-user and user-book-genreuser for Amazon-book dataset; we set the hidden layers as suggested in [14], which is a tower structure with 512, 256, 128, 64 dimensions.For RippleNet, we set the number of hops and the memory size as 2 and 8, respectively. Moreover, early stopping strategy is performed, i.e., premature stopping if recall@20 on the validation set does
not increase for 50 successive epochs. To model the third-order connectivity, we set the depth of KGAT L as three with hidden dimension 64, 32, and 16, respectively.
实验设置
**评估指标:对于测试集中的每个用户,我们将用户未与之交互的所有项视为负项。然后每种方法输出用户对所有项目的偏好得分,除了训练集中的正的项目。为了评估top-K推荐和偏好排序的有效性,我们采用了两个广泛使用的评估协议[13,35]:召回率@K以及归一化累计折损@K。默认情况下,我们设置K=20,报告了测试集中所有用户的平均度量。
基线:为了证明其有效性,将本文提出的KGAT与SL(FM和NFM)、基于正则化的(CFKG和CKE)、基于路径(MCRec和RippleNet)和基于图神经网络(GC-MC)的方法进行了比较。
参数设置: 在Tensorflow中实现了我们的KGAT模型。所有模型的嵌入大小都固定为64,只有RippleNet 是16,因为它的计算成本很高。我们使用Adam优化器优化所有模型,其中批大小固定为1024。用Xavier来初始化参数[8]。我们对超参数应用网格搜索:**学习率在{0.05,0.01,0.005,0.001}之间调整,L2归一化系数在{10−5,10−4,····,101,102}中搜索,对于NFM、GC-MC和KGAT,丢失率在{0.0,0.1,···,0.8}中调整。此外,我们还对GC-MC和KGAT采用了节点丢失技术,其中丢失率率在{0.0,0.1,···,0.8}中搜索。对于MCRec,我们手动定义了几种类型的用户项属性元路径,如用户-书-作者-用户和用户-书-类型-用户;我们按照[14]中的建议设置隐藏层,这是一个512、256、128、64维的塔式结构。对于RippleNet,我们分别将跃点数和内存大小设置为2和8。此外,执行早停策略。即,如果召回率@20在验证集上,连续50个时间段不会增加则停止更新。为了模拟三阶连接性,我们将KGAT中的L的深度分别设置为3,隐藏维度分别为64、32和16。
Result
Overall Comparison
The performance comparison results are presented in Table 2. We have the following observations:

• KGAT consistently yields the best performance on all the datasets. In particular, KGAT improves over the strongest baselines w.r.t. recall@20 by 8.95%, 4.93%, and 7.18% in Amazon-book, LastFM,and Yelp2018, respectively. By stacking multiple attentive embedding propagation layers, KGAT is capable of exploring the high-order connectivity in an explicit way, so as to capture collaborative signal effectively. This verifies the significance of capturing collaborative signal to transfer knowledge. Moreover, compared with GC-MC, KGAT justifies the effectiveness of the attention mechanism, specifying the attentive weights w.r.t. compositional semantic relations, rather than the fixed weights used in GC-MC.
• SL methods (i.e., FM and NFM) achieve better performance than the CFKG and CKE in most cases, indicating that regularization based methods might not make full use of item knowledge. In particular, to enrich the representation of an item, FM and NFM exploit the embeddings of its connected entities, while CFKG and CKE only use that of its aligned entities. Furthermore, the cross features in FM and NFM actually serve as the second-order connectivity between users and entities, whereas CFKG and CKE model connectivity on the granularity of triples, leaving highorder
connectivity untouched.
• Compared to FM, the performance of RippleNet verifies that
incorporating two-hop neighboring items is of importance to
enrich user representations. It therefore points to the positive
effect of modeling the high-order connectivity or neighbors.
However, RippleNet slightly underperforms NFM in Amazonbook and Last-FM, while performing better in Yelp2018. One possible reason is that NFM has stronger expressiveness, since the hidden layer allows NFM to capture the nonlinear and complex feature interactions between user, item, and entity embeddings.
• RippleNet outperforms MCRec by a large margin in Amazonbook. One possible reason is that MCRec depends heavily on the quality of meta-paths, which require extensive domain knowledge to define. The observation is consist with [29].
• GC-MC achieves comparable performance to RippleNet in LastFM and Yelp2018 datasets. While introducing the high-order connectivity into user and item representations, GC-MC forgoes the semantic relations between nodes; whereas RippleNet utilizes relations to guide the exploration of user preferences.
实验结果
先报告了所有方法的性能,然后研究高阶连接性建模如何缓解稀疏性的问题。
总体比较
性能比较结果见表2,分析如下:

- KGAT在所有数据集上都始终获得最佳性能。特别是,KGAT与最好的基线相比也有所提高。召回率@20在Amazon book、LastFM和Yelp2018分别增长8.95%、4.93%和7.18%。通过叠加多个注意嵌入传播层,KGAT能够以显式的方式探索高阶连通性,从而有效地捕获协同信号,这验证了捕获协同信号传递知识的重要性。此外,与GC-MC相比,KGAT证明了注意力机制的有效性,跟GC-MC中使用的固定权重不同,它指定了注意力权重。
- SL方法(即FM和NFM)在大多数情况下比CFKG和CKE方法获得更好的性能,这表明基于正则化的方法可能无法充分利用项目知识。特别是,为了丰富一个项的表示,FM和NFM利用其连接实体的嵌入,而CFKG和CKE只使用其对齐实体的嵌入。此外,FM和NFM中的交叉特性实际上充当了用户和实体之间的二阶连接,而CFKG和CKE则在三重粒度上建立了连接模型,使得高阶连接不受影响。
- 与FM相比,RippleNet的性能验证了合并两跳相邻项对于丰富用户表示的重要性。因此,它指出了建模高阶连通性或邻域的积极作用。然而,RippleNet在Amazonbook和Last FM中的表现稍逊于NFM,而在Yelp2018中表现更好。一个可能的原因是NFM具有更强的表现力,因为隐藏层允许NFM捕捉用户、项和实体嵌入之间的非线性和复杂的特征交互。
- RippleNet在Amazon book中的表现远远优于MCRec。一个可能的原因是MCRec在很大程度上依赖于元路径的质量,这需要大量的领域知识来定义。
- GC-MC在LastFM和Yelp2018数据集中实现了与RippleNet相当的性能。GC-MC在将高阶连通性引入用户和项目表示时,放弃了节点间的语义关系;而RippleNet则利用关系来指导用户偏好的探索。
Performance Comparison w.r.t. Interaction Sparsity
One motivation to exploiting KG is to alleviate the sparsity
issue, which usually limits the expressiveness of recommender systems. It is hard to establish optimal representations for inactive users with few interactions. Here we investigate whether exploiting connectivity information helps alleviate this issue.
Towards this end, we perform experiments over user groups of different sparsity levels. In particular, we divide the test set into four groups based on interaction number per user, meanwhile try to keep different groups have the same total interactions. Taking Amazon-book dataset as an example, the interaction numbers per user are less than 7, 15, 48, and 4475 respectively. Figure 3 illustrates the results w.r.t. ndcg@20 on different user groups in Amazon-book, Last-FM, and Yelp2018. We can see that:

• KGAT outperforms the other models in most cases, especially on the two sparsest user groups in Amazon-Book and Yelp2018.It again verifies the significance of high-order connectivity modeling, which 1) contains the lower-order connectivity used in baselines, and 2) enriches the representations of inactive users via recursive embedding propagation.
• It is worthwhile pointing out that KGAT slightly outperforms
some baselines in the densest user group (e.g., the < 2057 group of Yelp2018). One possible reason is that the preferences of users with too many interactions are too general to capture. High-order connectivity could introduce more noise into the user preferences, thus leading to the negative effect.
不同交互稀疏度的比较
利用KG的一个动机是缓解稀疏性问题,这通常限制了推荐系统的表达能力。对于交互较少的非活动用户,很难建立最佳表示。在此,我们将研究利用连接信息是否有助于缓解此问题。
为此,我们对不同稀疏级别的用户组进行了实验。特别是,我们根据每个用户的交互次数将测试集分为四组,同时尝试保持不同的组具有相同的总交互。以Amazon图书数据集为例,每个用户的交互次数分别小于7、15、48和4475。图3显示了归一化累计折损@20在Amazon book、Last FM和Yelp2018中的不同用户组上的结果,可以得到:
- KGAT在大多数情况下都优于其他模型,特别是在最稀疏的两个用户组Amazon Book和Yelp2018上,再次验证了高阶连通性建模的意义:1)包含基线中使用的低阶连通性;2)通过递归嵌入传播丰富了非活动用户的表示。
- 值得指出的是,在最密集的用户组(例如Yelp2018的<2057组)中,KGAT稍微优于一些基线。一个可能的原因是,交互过多的用户的偏好过于笼统,无法捕捉。高阶连通性会在用户偏好中引入更多的噪声,从而导致负效应。