【论文阅读笔记】Cross-Lingual Abstractive Summarization with Limited Parallel Resources
使用有限的平行语料来做跨语言的生成式摘要
Abstract
平行的跨语言的摘要数据是稀缺的,需要模型更好地利用有限的可用跨语言资源。
现有的方法通常采用带有多任务框架的seq2seq网络。这种方法用多个解码器,每个解码器用于特定的任务。然而,这些独立的解码器之间没有共享参数,因此无法捕获不同语言中摘要的离散短语之间的关系,从而破坏了能够将高资源语言的知识转移到低资源语言的连接。【背景】
为了利用这些连接,我们提出了一个新的多任务框架,用于低资源环境下的跨语言生成式摘要(MCLAS)。MCLAS采用统一的解码器生成单语和跨语摘要的顺序拼接,使单语摘要任务成为跨语摘要任务的前提条件。通过这种方式,共享解码器学习涉及跨语言对齐和总结模式的交互,这鼓励实现知识转移。【模型】
在两个CLS数据集上的实验表明,我们的模型在低资源和全数据集情况下都显著优于三个基线模型。此外,对生成的摘要和注意力头的深入分析证实,使用MCLAS可以很好地学习交互,有利于在有限并行资源下完成CLS任务。【实验】
1.Intro
跨语言摘要(CLS)可以帮助人们有效地从外语文章中获取重要信息。用神经学方法研究CLS需要包含数百万个跨语言文档-摘要对的大规模数据集。然而,这些方法带来了两个挑战:1)大多数语言都是低资源的,因此缺乏文档-摘要配对数据;2)用于基于神经网络的CLS的跨不同语言的大型并行数据集是罕见和昂贵的,特别是在当前神经网络的趋势下。因此,对于跨语言摘要来说,低资源设置更实际,也更具挑战性。据我们所知,在低资源环境下的跨语言总结还没有得到很好的研究和探索。因此,在本文中,我们将建立一个在有限监督下的跨语言文摘的新模型。
对于低资源环境,多任务学习已被证明是一种有效的方法,因为它可以从其他相关任务中借用有用的知识,并在目标任务中使用。跨语言摘要可被视为两项任务的结合,即单语摘要(MS)和跨语言翻译(Zhu et al, 2019)。在MS和CLS任务的目标摘要之间存在大量的关系,例如翻译对齐和摘要模式。在图1中,“叙利亚”被映射到“Syria”,别的短语也有类似的映射。显然,利用这些关系对于将摘要知识从高资源语言转移到低资源语言是至关重要的。不幸的是,现有的多任务框架只是利用独立的解码器分别执行MS和CLS任务,这导致捕捉这些关系失败。

图1:跨不同语言摘要的对齐示例。每一种颜色都代表有特定含义的短语。
为了解决这个问题,我们在MS和CLS任务之间建立依赖连接,使单语言任务成为跨语言任务的先决条件。具体来说,MS和CLS任务共享一个解码器;这是通过将生成目标设置为单语言摘要和相应的跨语言摘要的顺序连接来实现的。解码器依次生成单语和跨语摘要,并在两者之间执行翻译任务,增强了不同语言之间的互动性。这些交互隐式地涉及翻译对齐、语义单位的相似性以及不同语言摘要之间的摘要模式。为了演示这些解码器交互,我们通过探测模型中的Transformer注意头来进一步可视化它们。基于此过程,具有这些高级交互的新结构增强了低资源场景,这些场景要求模型能够将概要知识从高资源语言转移到低资源语言。在有限的资源条件下,我们将模型命名为多任务跨语言生成式摘要(MCLAS)。
在资源有限的情况下,我们首先对MCLAS进行大规模单语言文档摘要并行数据集的预训练,使解码器具备一般摘要能力。给定少量并行跨语言摘要样本,然后对模型进行优化,并能够将学到的摘要功能转移到低资源语言,利用共享解码器所揭示的交互。
在Zh2EnSum (Zhu等人,2019)和一个新开发的En2DeSum数据集上的实验表明,在低资源场景和全数据集场景下,与最先进的跨语言摘要模型相比,MCLAS提供了显著的改进。与此同时,我们还在En2ZhSum数据集中取得了具有竞争力的性能。人工评价结果表明,在有限的并行资源下,MCLAS比基线模型生成了更流畅、简洁和信息量更大的摘要。此外,我们分析了生成摘要的长度和单语生成的成功程度,以验证识别语言之间的交互所提供的优势。我们进一步研究了所提出的多任务结构的可解释性,通过探测统一译码器中的注意力头,证明MCLAS可以学习两种语言之间的对齐和交互,这有助于在译码阶段进行翻译和总结。我们的分析清楚地解释了为什么MCLAS能够在有限的资源下支持CLS。我们的实现和数据在这里。
2.Related Work
2.1 Cross-Lingual Summarization/跨语言摘要
近年来,随着跨语言信息需求的增加,跨语言摘要研究受到了广泛关注。
传统的CLS系统基于管道范式。这些管道系统首先翻译文档,然后总结文档,或者反过来。Shen等提出使用伪摘要训练跨语言生成式摘要模型。相比之下,Duan等和Ouyang等生成伪源来构建跨语言摘要数据集。
第一个大规模跨语言摘要数据集是通过使用往返翻译策略获得的。此外,Zhu等人提出了一个多任务框架来改进他们的跨语言总结系统。继Zhu等人之后,提出了更多的方法来改进CLS任务。Zhu等使用指针-生成器网络来开发跨语言摘要中的翻译模式。Cao等人利用两个编码器和两个解码器共同学习对齐和总结。与以前的方法相比,MCLAS生成单语和跨语摘要的串联,从而建模它们之间的关系。
2.2 Low-Resource Natural Language Generation/低资源自然语言生成
低资源语言或领域的自然语言生成(NLG)已经引起了广泛关注。Gu等人利用元学习改进低资源神经机器翻译。与此同时,许多经过预先训练的NLG模型已经被提出,并适用于低资源场景。然而,这些模型需要大规模的预训练。我们的工作不需要任何大的预先训练的生成模型或转换模型,这使得训练成本大大降低。
3.Backgroud
3.1 Neural Cross-lingual Summarization
给定一个A语言的源文档![]() ,单语言摘要系统将源文档转换为摘要
,单语言摘要系统将源文档转换为摘要![]() ,其中m和n分别为
,其中m和n分别为![]() 和
和 的长度。跨语言摘要系统产生一个摘要
的长度。跨语言摘要系统产生一个摘要![]() ,由目标语言B中的token
,由目标语言B中的token ![]() 组成,其中n'是
组成,其中n'是![]() 的长度。注意,前面提到的
的长度。注意,前面提到的![]() 都是token。
都是token。
Zhu等人提出使用Transformer进行跨语言总结任务。Transformer由堆叠的编码器层和解码器层组成。编码器层由自注意层和前馈层组成。除额外的编码器-解码器注意层外,解码器层与编码器共享相同的体系结构,该注意层对堆叠的编码器层的输出执行多头注意。训练整个Transformer模型θ使目标序列![]() 的条件概率最大化,如下所示:
的条件概率最大化,如下所示:
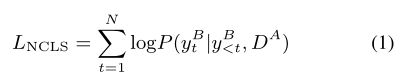
3.2 Improving NCLS with Multi-Task Frameworks
考虑到CLS和MS之间的关系,它们都有总结文档中重要信息的共同目标,Zhu等提出使用一对多的多任务框架来增强基本的Transformer模型。在该框架中,使用一个编码器对源文档![]() 进行编码。两个独立的解码器同时生成一个单语言摘要
进行编码。两个独立的解码器同时生成一个单语言摘要![]() 和一个跨语言摘要
和一个跨语言摘要![]() ,导致如下损失:
,导致如下损失:

这个多任务框架共享编码器表示,以增强跨语言摘要。然而,该模型中的独立解码器无法在跨语言摘要之间建立对齐和连接。
4.MCLAS with Limited Parallel Resources
为了加强上述的联系,我们建议通过建模交互,使单语任务成为跨语言任务的先决条件。根据以前的工作,跨语言摘要之间的相互作用(重要的短语对齐、句子长度和摘要模式等)对最终摘要的质量至关重要。我们利用这些互动来进一步转移丰富的语言知识资源。以下部分将详细描述此步骤。
4.1 Multi-Task Learning in MCLAS
为了建模语言之间的交互,我们需要共享解码器的参数。受Dong等人的启发,我们提出共享整个解码器来执行翻译和摘要任务。具体来说,我们将生成目标![]() 替换为
替换为![]() 和
和![]() 的顺序拼接:
的顺序拼接:

其中[BOS]和[EOS]分别是输出摘要的开始和结束token。[LSEP]是用来分隔![]() 和
和![]() 的特殊token。
的特殊token。
有了新的生成目标,解码器学会首先生成![]() ,然后生成以
,然后生成以![]() 和
和![]() 为条件的
为条件的![]() 。整个生成过程如图2所示。
。整个生成过程如图2所示。

图2: MCLAS的总体框架。统一的解码器同时生成单语言(绿色)和跨语言(红色)摘要。绿色和红色的线分别代表单语和跨语摘要的注意力。
形式上,我们将单语和跨语摘要的联合概率最大化:
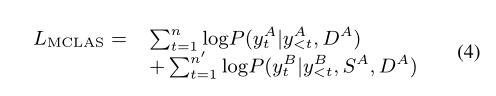
损失函数可以分为两项。在生成![]() 时,解码器基于
时,解码器基于![]() 执行MS任务,对应于式(4)中的第一项。在生成
执行MS任务,对应于式(4)中的第一项。在生成![]() 时,解码器已经知道相应的单语摘要信息。通过优化式(4)中的第二项,我们的模型可以很容易地捕捉到跨语言摘要之间的相互作用。经过训练的模型在对齐摘要方面显示出了有效性。不仅输出的token,而且注意力分布也是一致的。我们设计的模型利用了这一现象,使单语言知识能够在低资源场景下转移。详细的调查将在第6节中介绍。
时,解码器已经知道相应的单语摘要信息。通过优化式(4)中的第二项,我们的模型可以很容易地捕捉到跨语言摘要之间的相互作用。经过训练的模型在对齐摘要方面显示出了有效性。不仅输出的token,而且注意力分布也是一致的。我们设计的模型利用了这一现象,使单语言知识能够在低资源场景下转移。详细的调查将在第6节中介绍。
我们采用Transformers作为我们的基础模型。此外,我们使用多语言BERT来初始化编码器,提高其产生多语言表示的能力。此外,在尝试了许多不同的位置嵌入和语言分割嵌入方法后,我们发现[LSEP]足以让模型区分它是否正在生成![]() 。因此,保持原始的位置嵌入和不使用分割嵌入是性能和效率最好的。
。因此,保持原始的位置嵌入和不使用分割嵌入是性能和效率最好的。
4.2 Learning Schemes for MCLAS under Limited Resources
由于我们提议的框架强制跨多语言摘要之间的交互,它对低资源场景有进一步的好处,因为跨语言中只有少数培训摘要样本可用。例如,简单地从头开始训练并不能在低资源情况下使我们提出的模型发挥最佳效果。因此,我们使用预训练和微调范式来转移资源丰富的语言知识。
首先,我们在单语言摘要数据集中训练模型。在这一步中,模型学习如何为给定的文档生成单语言摘要。然后,用较少的训练样本联合学习MS和CLS,优化式(4)。我们采用与现有CLS方法类似的初始化方法,这将在5.3节中介绍。
5.Experiments
5.1 Datasets
我们在En2ZhSum、Zh2EnSum数据集和一个新构建的En2DeSum数据集上进行了实验。En2ZhSum是一个包含364,687个训练样本、3000个验证样本和3000个测试样本的英汉数据集。数据集由CNN/DM和MSMO的并集使用往返翻译策略进行转换。由LCSTS数据集转换而来的Zh2EnSum包含1,693,713个中英训练样本、3,000个验证样本和3,000个测试样本。为了更好地验证MCLAS的CLS能力,我们使用Zhu等人提出的相同方法,构建了一个新的英语-德语数据集(En2DeSum)。
我们使用WMT’19英德winner作为翻译模型来处理英语Gigaword数据集。我们设置阈值T1 = 0.6, T2 = 0.2。最终的En2DeSum包含429,393个训练样本、4,305个验证样本和4,099个测试样本。
所有训练示例都包含一个源文档、一个单语言摘要和一个跨语言摘要。对于全数据集场景,我们使用整个数据集来训练模型。对于低资源场景,我们为所有数据集随机选择3个不同数量的训练样本(最小、中、最大值),以评估我们的模型在低资源场景下的性能。具体数字见表1。

表1:不同低资源场景的样本大小。为每个数据集创建三个具有不同样本大小的低资源场景。Minimum、Medium和Maximum分别表示最小低资源场景、中等低资源场景和最大低资源场景下的样本容量。
5.2 Training and Inference
我们使用多语言BERT (mBERT) 来初始化我们的Transformer编码器。该解码器是一个具有6层的变压器解码器。每个注意模块有8个不同的注意头。
解码器的自注意隐藏大小为768,前馈网络的隐藏大小为2048。
最终模型包含296,046,231个参数。
因为编码器是在随机初始化解码器时预先训练的,所以我们为编码器和解码器使用了两个独立的优化器(Liu和Lapata, 2019)。编码器的学习率![]() 设为0.005,解码器的学习率
设为0.005,解码器的学习率![]() 设为0.2。编码器的预热步骤为10,000,解码器为5,000。我们在两个TITAN RTX gpu上训练了一天的模型,每5步进行梯度积累。在所有线性层之前应用概率为0.1的Dropout。我们发现目标词汇类型对最终结果没有太大的影响。因此,我们直接使用mBERT的子词词汇作为我们的目标词汇。然而,为了防止用错误的语言生成标记,我们为每一种目标语言构建了一个目标标记词汇表。在所有线性层之前应用概率为0.1的Dropout。我们发现目标词汇类型对最终结果没有太大的影响。因此,我们直接使用mBERT的子词词汇作为我们的目标词汇。然而,为了防止用错误的语言生成标记,我们为每一种目标语言构建了一个目标标记词汇表。
设为0.2。编码器的预热步骤为10,000,解码器为5,000。我们在两个TITAN RTX gpu上训练了一天的模型,每5步进行梯度积累。在所有线性层之前应用概率为0.1的Dropout。我们发现目标词汇类型对最终结果没有太大的影响。因此,我们直接使用mBERT的子词词汇作为我们的目标词汇。然而,为了防止用错误的语言生成标记,我们为每一种目标语言构建了一个目标标记词汇表。在所有线性层之前应用概率为0.1的Dropout。我们发现目标词汇类型对最终结果没有太大的影响。因此,我们直接使用mBERT的子词词汇作为我们的目标词汇。然而,为了防止用错误的语言生成标记,我们为每一种目标语言构建了一个目标标记词汇表。
在推断阶段,我们只从相应的词汇表中生成标记。在解码阶段,我们使用波束搜索(大小为5)和三元块来避免重复。长度惩罚设置在0.6到1之间。所有超参数都使用PPL和验证集上的精度度量手动调优。
5.3 Baselines
我们将低资源场景中的MCLAS与以下基线进行比较:
NCLS:Zhu等(2019)提出的CLS模型。在资源不足的情况下,我们使用预训练的MS模型初始化我们的模型,然后使用少量样本对式(1)进行优化。
NCLS+MS:Zhu等人(2019)提出的多任务框架。我们发现,当NCLS+MS被预训练的MS模型部分初始化(CLS解码器被随机初始化)时,NCLS+MS不能收敛。因此,我们使用预先训练的MS模型完全初始化多任务模型。具体地说,这两个独立的解码器都由预先训练的单语解码器初始化。然后利用式(2)对模型进行优化。
TLTran:基于变压器的后期转换是一种管道方法。首先,单语言摘要模型总结源文档。然后应用一个翻译模型来翻译摘要。摘要模型使用三种数据集中的单语言文档-摘要对进行训练。具体来说,我们继续使用WMT’19英德译本作为En2DeSum的翻译模型。
最近提出的一些模型提高了CLS任务的性能。方法NCLS+MT、TETran和Ouyang等提出的系统需要外部长文档机器翻译(MT)语料库。Cao等人提出的方法不仅需要并行摘要,还需要MT系统翻译的文档对。Zhu等人提出的另一种方法需要从大型并行MT数据集中提取双语词汇。
我们选择不使用这些模型作为基线,因为将MCLAS与它们进行比较是不公平的。
5.4 Automatic Evaluation Results
低资源场景和全数据集场景下的总体结果如表2所示。我们重新实现了各种模型,并使用标准ROUGE度量的F1得分(ROUGE-1、ROUGE-2和ROUGE)和BERTScore4 (Zhang等人,2019b)对它们进行评估。以下分析来自我们的观察。

表2:Zh2EnSum、En2DeSum和En2ZhSum数据集的ROUGE和BERTScore的F1得分。R-1、R-2、R-L分别代表ROUGE-1、ROUGE-2、ROUGE-l。
在Zh2EnSum和En2DeSum数据集中,MCLAS在所有低资源场景中都比基线取得了显著的改进。值得注意的是,在我们的实验中结合NCLS+MS并没有给NCLS模型带来太大的改进。我们认为这是因为mBERT已经为我们的模型提供了多语言编码。
然而,我们发现,在En2ZhSum数据集中,MCLAS的表现不如在其他两个数据集中。我们推测,这是由于英语参考和汉语参考的不平衡所致。En2ZhSum中SA和SB的平均长度分别为55.21和95.96(Zhu et al, 2019)。这种情况在很大程度上破坏了语言之间的对齐,导致了MCLAS表现略弱。尽管如此,En2DeSum和Zh2EnSum的结果表明,我们提出的MCLAS模型对有限资源下的CLS是有效的。
最后,在拥有完整训练数据集的情况下,我们提出的模型也比基线模型具有更好的性能,在En2DeSum和Zh2EnSum数据集中获得了最佳的ROUGE得分。
5.5 Human Evaluation
除了自动评估之外,我们还进行人工评估以验证模型的性能。我们从Zh2EnSum测试数据集中随机选择了60个示例(每个低资源场景20个)。7名中英文流利程度较高的研究生被要求从独立的角度:信息性、流畅性和简洁性来评估生成的摘要和黄金摘要。我们遵循最佳-最差比例法(Kiritchenko和Mohammad, 2017)。参与者被要求指出从每个角度来看最好和最差的项目。结果分数是根据每个系统被选为最佳的次数减去被选为最差的次数的百分比计算的。因此,最终分数从-1(最差)到1(最好)不等。结果如表3所示。

表3:Zh2EnSum数据集的人工评价结果。最好的结果是粗体字。
随着数据量的增加,所有模型都能获得更好的结果。我们提出的MCLAS在所有指标上都优于NCLS和NCLS+MS。我们注意到,MCLAS在简洁性方面特别强。这一现象将在5.7节中进行分析。
我们在表4中展示了我们进行的人工评估的Fleiss的Kappa分数,这表明参与者之间有良好的相互认同。
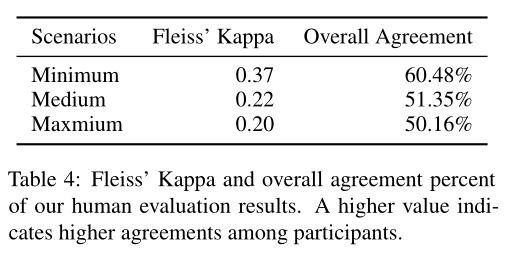
表4:弗雷斯的Kappa和我们人类评估结果的总体一致性百分比。数值越高,表示参与者的认同程度越高。
5.6 Analysis on Initialization Methods
我们使用单语言摘要模型来初始化我们的模型。然而,这种初始化方法是否有效仍是一个问题。因此,我们将我们的模型与未初始化的模型进行比较,如图3所示。在这三个数据集中,初始化方法对所有模型都有很大的改进。

图3:En2DeSum和Zh2EnSum结果的线柱图。行表示用预训练的单语摘要模型初始化的模型。列表示从零开始训练的模型。
5.7 Analysis on Summary Length
自动摘要的目标之一是生成简短的文本。许多神经自回归模型倾向于产生一个较长的摘要来改进召回度量。表5中的结果显示,交互使MCLAS能够生成比其他模型更短的摘要,这更接近于人类摘要。我们可以有把握地得出结论,MCLAS可以保持摘要的长度相当合适,从而生成简洁的摘要。我们推测,这是因为它能够捕捉语言之间的互动,使跨语言摘要与相对精确的单语摘要相适应。

表5:由各种模型生成的目标摘要长度。最好的结果是粗体字。
5.8 Analysis on Monolingual Summarization
语言之间的交互建模带来了许多好处。具体而言,我们发现在低资源调优过程中,MCLAS可以比NCLS+MS模型保留更多的单语言摘要知识,甚至可以提高其性能。我们使用在最大低资源场景下训练的模型生成单语言摘要。在表6中,我们可以清楚地看到,MCLAS在Zh2EnSum数据集中保留了更多的单语摘要知识。在En2DeSum数据集中,单语言摘要性能甚至得到了显著提高。我们推测这是由于MCLAS能够提供语言之间的交互。

表6:在Zh2EnSum和En2ZhSum数据集中的单语总结结果。MS-Pretrain是指单语摘要的预训练模型。
我们特别关注于挖掘En2DeSum中的结果,评估其详细的ROUGE和平均摘要长度,如表7所示。结果表明,鲁棒性能的提高主要来自于记忆精度的提高,而记忆率的降低则不明显。这和平均长度度量表明,MCLAS在保留大多数重要信息的同时产生了更精确的摘要,导致了ROUGE度量的增加。

表7:用En2DeSum数据集训练MCLAS的单语摘要生成能力分析。
5.9 Case Study
在图4中,在Zh2EnSum数据集上,有一个列表,比较了在最大低资源场景下训练的模型的参考摘要和输出。显然,NCLS模型丢失了“两辆车”的信息,生成了错误的信息“No.2工厂”。NCLS+MS模型在描述受伤人数时不准确,遗漏了重要信息“more than”。此外,NCLS+MS模型还存在流畅性和重复性问题:“在郑州”在生成的摘要中出现了两次。相比之下,MCLAS在中文和英文输出中都捕获了所有这些信息,并且英文摘要与中文摘要非常一致。最后,所有的模型都忽略了“富士康印在车身上”的信息。

图4:生成跨语言摘要的示例。重要的短语用粗体显示,每个模型生成的错误信息用斜体显示。句子中不流畅的部分用粗体和斜体。
更多示例见附录A。
6.Probing intno Attention Heads/探究注意力头
(懒得写了)
8.Conclusion
在本文中,我们提出了一个新的多任务学习框架MCLAS,以在有限的并行资源下实现跨语言抽象总结。我们的模型共享一个统一的解码器,可依次生成单语和跨语摘要。在两个跨语言汇总数据集上的实验表明,我们的框架在低资源和全数据集场景下优于所有基线模型。