复现KGAT: Knowledge Graph Attention Network for Recommendation(三)
复现KGAT: Knowledge Graph Attention Network for Recommendation(三)
昨天写了复现KGAT系列的第二篇文章,准确的说那片文章里第二部分是昨天写的,第三部分是今天写的。如果再连着写下去就太长了,不如正好把第四部分单拿出来写,正好第四部分是实验部分,也是我复现论文需要关注的主要部分。
能挤出很多时间来复现论文真的很不容易,估计今天写完明天就没有什么时间来继续写了,也不知道再写又会是什么时候了。
4.EXPERIMENTS
我们在三个真实数据集上估计了我们提出的方法,特别是嵌入传播层,我们的目标是回答以下三个研究问题:
RQ1:KGAT与最先进的知识感知推荐方法比表现如何?
RQ2:不同的内容(比如说,知识图谱嵌入(konwledge graph embedding),注意力机制(attention mechanism)和聚集器选择(aggregator selection))对KGAT的影响如何?
RQ3:KGAT可以为用户对于物品的的偏好做出合理的解释吗?
4.1 Dataset Description
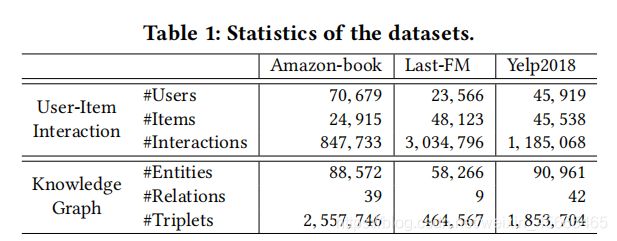
为了评估KGAT的效果,我们利用了三个分支数据集:Amazon-book,Last-FM和Yelp2018,这三个数据集都是公开可获得的并且在域、大小和稀疏程度上都是不同的。
Amazon-book: Amazon-review是被产品推荐广泛使用的数据集。我们从这个集合中选取了Amazon-book数据集。为了保证数据集的质量,我们使用了10-core的设置,即保留至少有10个交互的用户和物品。
Last-FM: 这是音乐收听数据集,收集自Last.fm 在线音乐系统。其中,tracks被视作items。特别的,我们使用时间从2015.1 到2015. 6期间的数据子集。同样的,我们使用10-core的设置保证数据质量。
Yelp2018: 这个数据集收集自2018版的黄色挑战。因此我们将当地的商业,比如说餐馆和酒吧看作是item。同样的,我们使用了10-core设置来确保用户和物品有最少10词交互。
除了用户和物品的交互,我们需要对每个数据集构造物品的知识。对于Amazon-book和Last-fm,如果有映射,我们通过标题匹配将项目映射到freebase entity(自由基础实体)。特别的,我们考虑与和物品对齐的实体直接相关的三元组,无论他是subject还是object。和仅提供物品一跳实体的知识感知数据集不同,我们将包括两跳邻居的实体的三元组也考虑在内。对于Yelp2018,我们从当地商业的信息网络(比如说,分类,地点和属性)中提取物品的知识作为KG数据。为了确保KG的质量,我们通过过滤掉不常用的实体(在两个数据集中都低于10)和保持至少在50个三元组中出现的关系来处理三个KG部分。我们总结了三个数据集的的特性(见下表)然后将数据集发布在了t https://github.com/xiangwang1223/knowledge_graph_attention_network.这个网址上。
对于每个数据集,我们随机选取交互历史的80%作为训练集,剩下的部分作为测试集。对于训练集,我们随机选取10%的交互作为验证集来调整超参数。对于每一个观测到的uesr-item交互,我们将他们看作是正样本,然后执行负采样策略来为正样本配对,这个负样本是用户之前没有消费过的。
4.2 Experimental Settings
4.2.1 Evaluation Metrics(评估指标):对于测试集中的每一个用户,我们将用户没有交互过的物品看作是负样本。然后,每一个方法都输出用户对于每一个不在训练集中的正样本的偏好分数。为了评估top-K推荐的效率和喜爱度的排名,我们采用了两种广泛使用的评估策略:recall@K、ndcg@K。默认的,K=20。我们报告了对于所有用户在测试集中的平均指标。
4.2.2 Baseline:为了证明有效性,我们对比了我们提出的KGAT和SL(FM和NFM)、基于正则化的方法(CFKG和CKE)、基于路径的方法(MCRec和RippleNet)和基于图神经网络的方法(GC-MC),如下:
1)FM: factorization model的简写,矩阵分解。FM考虑了在输入之间的两级特征交互。这里我们将用户ID、物品的ID以及物品的知识(也就是和他关联的实体)作为输入。
2)NFM: 这个方法是现在很流行的矩阵分解模型,将FM归入到了神经网络下面。特别的,按照建议,我们在输入特征部署了一个隐藏层。
3)CKE: 这是一种典型的正则化方法,它探索了起源于TransR的语义嵌入增强了矩阵分解。
4)CFKG: 这个模型在包括了用户、物品、实体和关系的统一图上应用了TransE,并将推荐系统转化为了三元组的合理性预测。
5)MCRec: 这是基于路径的模型,在用户和和项目之间提取了符合条件的元路径作为连接。
6)RippleNet: 这个模型结合了基于正则化和基于路径的的方法,通过在根于每个用户的路径中添加项来丰富用户的表示。
7)GC-MC: 这个模型设计是为了在基于图结构的数据上部署GCN编码器,特别是对于user-item的二部图。特别的,按照建议我们部署了一个图卷积层,这里的隐藏层维度和嵌入层维度是相同的。
**4.2.3 Parameter Settings:**参数设置。我们在tensorflow上部署了我们的KGAT模型。对于所有模型,嵌入层的大小固定为64,但是由于RippleNet的高计算代价,我们在RippleNet上使用了16。对于所有模型,我们均使用了Adam优化器,batch大小均为1024,默认的初始化参数的初始化器为Xavier 初始化器。我们对于超参数使用了网格搜索:学习率被调整的范围是{0.05,0.01,0.005,0.001},L2正则化系数搜索范围是:![]() 对于NFM,GC-MC,KGAT的dropout率取值范围是{0.0,0.1,……,0.8}。除此之外,我们在GC-MC和KGAT上部署了节点dropout技术(node dropout technique),dropout的率取值范围也是{0.0,0.1,……,0.8}。对于MCRec,我们手动定义一些用户-物品-属性-物品的元路径类型,比如说,user-book-author-user和user-book-genre-user对于Amazon-book数据集;按照建议我们设置了塔形结构的隐藏层,该结构的维度为:512,256,128,64。对于RippleNet,我们将跳的数值设置为2,将记忆大小设置为8。更多的,我们使用了早停策略(early stopping strategy),也就是说,在验证集上成功执行了50个epochs后,如果召回率recall@20不再增长了那就提早执行终止。为了对三阶连接进行建模,我们将KGAT的深度设置为3,并且隐藏层的维度设置为64,32,16。我们在4.4.1节中报告了层深的影响。对于每一层我们执行Bi-Interaction aggregator。
对于NFM,GC-MC,KGAT的dropout率取值范围是{0.0,0.1,……,0.8}。除此之外,我们在GC-MC和KGAT上部署了节点dropout技术(node dropout technique),dropout的率取值范围也是{0.0,0.1,……,0.8}。对于MCRec,我们手动定义一些用户-物品-属性-物品的元路径类型,比如说,user-book-author-user和user-book-genre-user对于Amazon-book数据集;按照建议我们设置了塔形结构的隐藏层,该结构的维度为:512,256,128,64。对于RippleNet,我们将跳的数值设置为2,将记忆大小设置为8。更多的,我们使用了早停策略(early stopping strategy),也就是说,在验证集上成功执行了50个epochs后,如果召回率recall@20不再增长了那就提早执行终止。为了对三阶连接进行建模,我们将KGAT的深度设置为3,并且隐藏层的维度设置为64,32,16。我们在4.4.1节中报告了层深的影响。对于每一层我们执行Bi-Interaction aggregator。
4.3 Performance Comparison(RQ1)
[ RQ1:KGAT与最先进的知识感知推荐方法比表现如何? ]
我们首先报告了所有方法的表现,然后研究了高阶关联模型(the modeling of high-order connectivity)如何减轻稀疏问题。
4.3.1 Overall Comparison (总体比较)
表现比较结果呈现在了表2中,有以下观察:
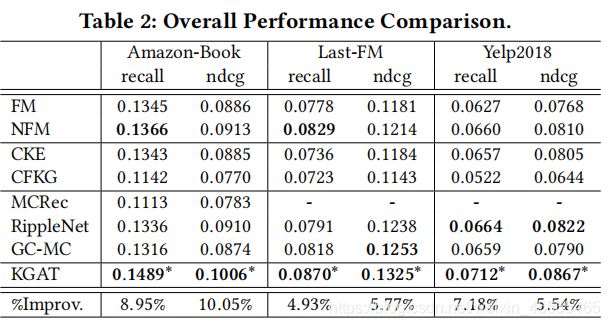
1)KGAT始终在所有数据集上有最佳表现。特别的,KGAT提升了最强基线recall@20在Amazon-book上是8.95%,Last-FM是4.93%,Yelp2018是7.18%。 通过叠加多个注意力嵌入传播层,KGAT能够使用显式的方式探索高阶关连关系,所以能够有效的捕捉协同信号。这个方式验证了传递知识时捕捉协同过滤信号的重要性。更多的,和GC-MC相比,KGAT证明了注意力机制的有效性,制定了注意力的权重也就是组合语义关系,而不是像GC-MC一样使用了固定的权重。
2)SL方法(FM、NFM)在很多案例下都取得了比CFKG和CKE更好的表现,这表明了基于正则化的方法很可能没有充分利用物品的知识。特别的,为了丰富物品的表现,FM和NFM探索了和他关联的实体的嵌入层,而CFKG和CKE只是用了和他对齐的实体。更多的,在FM和NFM中的交叉特征实际上充当了用户和实体之间的第二阶关联关系,然而CFKG和CKE在对三元组的关联关系建模的粒度并没有使用高阶关联关系。
3)和FM相比,RippleNet的表现证实了混合了两跳邻居对于丰富用户表现是很重要的。他也因此指出了对于高阶关联关系和邻居进行建模是有积极效果的。然而,在Amazon-book数据集上RippleNet表现有一点不如NFM和Last-FM,但是比Yelp2018表现的好一点。一个可能的原因是NFM有更强的表达,隐藏层允许NFM去捕捉用户、物品和实体之间非线性和混合交互特征。
4)RippleNet在亚马逊数据集上比MCRec表现要好得多。一个可能的原因是MCRec很强的依赖于元路径的质量,这个需要大量的域知识才能去定义。
5)GC-MC和RippleNet在Last-FM和Yelp2018数据集上表现效果相当。当像用户和物品表现引入高阶关联的时候,GC-MC放弃了节点之间的语义关系,然而RippleNet利用了这个关系引导了用户表现的探索。
4.3.2 Performance Comparison w.r.t. Interaction Sparsity Level
利用KG的一个目的是解决稀疏性的问题,稀疏性常常限制了推荐系统的表现。很难对有很少交互数据的用户有很好的表示。因此我们研究探索关联关系信息是否有助于解决稀疏性问题。
朝着这个目标,我们用关于用户不同稀疏程度的数据组来进行实验。特别的,我们根据每个用户的交互数据量将数据集分为四组,同时尝试使每个组的交互数据总量是相同的。以Amazon-book数据集作为例子,每个用户交互数据量分别小于7,15,48,4475。图三(下图)说明了关于ndcg@20在Amazon-book,Last-FM和Yelp2018在不同用户组上的结果。

我们可以看到:
1)KGAT在大多数案例下表现都比其他模型好,尤其是在Amazon-Book和Yelp2018的两个最稀疏的用户组上。这再次证明了高阶关联关系模型的重要性,一个是包含了低阶关联关系在基线上的使用,其二通过递归地嵌入传播丰富了不活跃用户的表现。
2)值得指出的是,KGAT在一些密度很大的群组上表现的比基线稍微好一些。一个可能的原因,交互过多的偏好过于普遍,无法捕捉。高阶关连关系可能会在用户偏好上引入噪声,从而使模型表现下降。
4.4 Study of KGAT(RQ2)
[ RQ2:不同的内容(比如说,知识图谱嵌入(konwledge graph embedding),注意力机制(attention mechanism)和聚集器选择(aggregator selection))对KGAT的影响如何? ]
为了深入了解KGAT的专注嵌入传播层,我们研究了它的影响。我们首先研究了层数的影响。然后我们探索了聚合器对模型表现影响有什么不同。接着,我们检查了知识图谱嵌入和注意力机制的影响。
4.4.1 Effect of Model Depth
我们改变了KGAT的深度(也就是L)来研究使用多个嵌入传播层的效率。特别的,层数在{1,2,3,4}之间探索,我们使用KGAT-1来表示只有一层的模型,其他的符号相似。我们将结果总结在了Table3上(如下图),有如下的观察:

1)增加KGAT的深度能够大大提高性能。显然,KGAT-2和KGAT-3全面实现了比KGAT-1连续的提升。我们将这种提升归因为在用户、物品、实体之间有效的高阶关系建模,这分别由二阶、三阶的关联关系实现。
2)在KGAT-3上继续叠加一层,我们观察到KGAT-4只获得了很少的提升。这说明了在实体间使用三阶关系就能有效地捕捉协同信号。
3)将表2和表3连起来分析,在大多数案例下KGAT-1表现的不错。他再次证明了注意力嵌入传播的有效性,实验结果证明他对一阶关系建模更好。
4.4.2 Effect of Aggregators
为了探索聚合器的影响,我们讨论使用不同设置的KGAT-1的变体,特别的,GCN,GraphSage和Bi-Interaction被称为KGAT-1GCN,KGAT-1GraphSage和KGAT-1Bi-Interaction。表4(见下图)总结了实验结果,有如下发现:

1)KGAT-1GCN表现持续优于KGAT-1GraphSage。一个可能的原因是GraphSage没有在实体表示eh和它的ego-network表示之间有交互。他也因此证明了在信息传播和聚集中特征交互的重要性。
2)和KGAT-1GCN相,比KGAT-1Bi证实了将额外的特征交互混合进来可以提高表示学习,他再次证明了Bi-Interaction聚合器的合理性和有效性。
4.4.3 Effect of Koneledge Graph Embedding and Attention Mechanism 知识图谱嵌入和注意力机制的效果
为了证实知识图谱嵌入和注意力机制的影响,我们在考虑了三个不同KGAT-1的情况下做了消融实验。特别地,我们使KGAT中TransR的嵌入内容失效,将这个模型叫做KGAT-1 w/o KGE,我们将注意力机制失效,并且将pai(h,r,t)的值设置为1/|Nh|,这个模型叫做 KGAT-1 w/o Att。更多的,我们将另一种将两个内容都去掉的模型种类叫做KGAT-1 w/o K&A。我们在列表5中总结了以下发现:
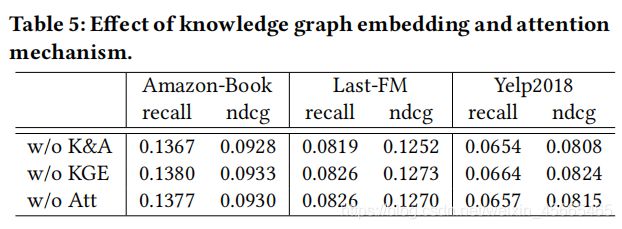
1)将知识图嵌入和注意力内容都移走会降低模型表现。KGAT-1 w/o K&A 比KGAT-1 w/o KGE和KGAT-1 w/o Att表现得都不好。 这表示了KGAT-1 w/o K&A不能在三元组三元组力度上显示地对相关表示进行建模。
2)和KGAT-1 w/o Att相比,KGAT-1 w/o KGE在大多数案例下表现的好,一个可能的原因是,将邻居们平等的看待可能会引入噪声并且误导嵌入传播过程。他证明了图注意力机制的重要影响。
4.5 Case Study(RQ3)
受益于注意力机制,我们可以推理高阶连接来推断用户目标项的偏好,并提供解释。为了这个目标,我们从Amazon-Book中选取了一个用户u208,和一个相关的物品i4293(来自测试集,在训练阶段不可见)。我们根据注意力分数抽取了基于行为和基于属性的连接了用户-物品对的高阶关系,图4(下图)展示了高阶关联关系的可视化表示。这里有两个关键的发现:
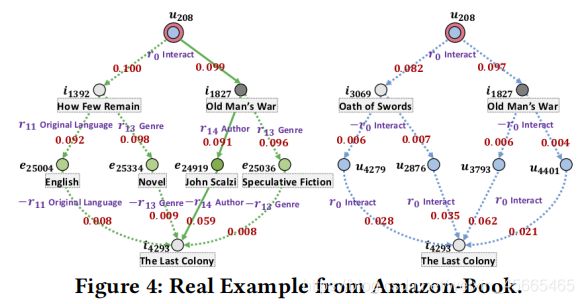
1)KGAT捕捉了基于行为的和基于属性的高阶关联,该关联对于推断用户的偏好起着十分重要的作用。恢复的路径可以看作是物品满足用户偏好的证据。正如我们看到的,如下关联有着最好的注意力分值。
![]()
该路径在Figure4左边子图中用实线标出来了。因此我们可以解释The last Colony会被推荐出来是因为看过了John Scalzi写的Old Man‘s War。
2)物品知识的质量至关重要。因为我们可以看到,实体English和关系Original Language在同一条路径中。这激励我们在未来的工作中努力过滤信息较少的实体。
总结
文章读完了,从开始读到读完总共花了13.5个小时,这个速度还是可以接受的。接下来要开始真的复现了。代码,啊,是代码。。。今天周三,这周还能搞KGAT的时间应该是寥寥无几了,准确的说应该是没有时间做他了,事情,啊,事情,啊,好多事情。。。