人工智能与机器学习——人脸表情识别
目录
一、人脸特征提取步骤
二、笑脸数据集训练
三、笑脸识别
四、参考连接
一、人脸特征提取步骤
①数据集
这里我们使用GENKI-4K数据集去进行我们的实验,GENKI-4K一共包含4000个图像,分为“笑”和“不笑”两种,每个图片拥有不同的尺度大小,姿势,光照变化,头部姿态,可专门用于做笑脸识别。这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。
②定义
训练/测试:将图片分为训练集和测试集,训练集中的图片是用来训练模型,测试集的图片是用来对模型进行测试和评价的。
阳性样本:笑脸的图片。
阴性样本:不笑的图片
F1分数:用来衡量你的模型。对于分类任务,用真阳性、真阴性、假阳性和假阴性等词对被测分类器的结果与可信的外部判断进行比较。正和负指的是分类器的预测(有时称为期望),真和假指的是预测1 2 是否对应于外部判断(有时称为观察)。从某些条件下的正实例和负实例中定义一个实验。这四种结果可以用一个2×2列联表或混淆矩阵来表示,如下: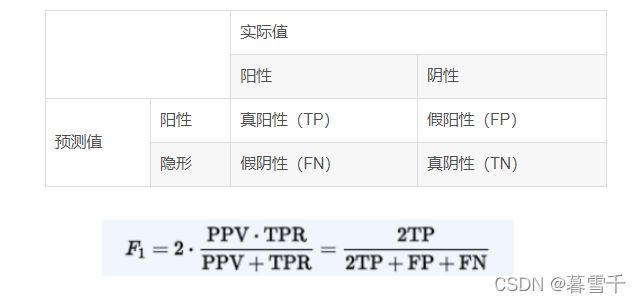
③检测笑脸的过程
首先找到图像中的脸,接下来就是分类这张照片是笑还是不笑,在第一步的操作中,可以直接使用包,比如OpenCV或者dlib中的人脸检测;在下一步的操作中,应该自己训练一个模型,模型的输入是从图像中提取的脸,输出的是测试的结果。结果的分类通常包括了特征提取和特征分类两个步骤,其中有两个特征,HOG和LBP,还有一种分类的方法SVM。
HOG,定向梯度直方图,图像内局部物体的外观和形状可以用强度梯度或边缘方向的分布来描述。该图像被划分为被称为单元的小连接区域,并为每个单元内的像素编译一个梯度方向的直方图。描述符是这些直方图的连接部分。与其他描述符相比,HOG描述符有一些关键的优势。下面是HOG的一个例子。

LBP,本地二进制模式。经常被用于关于人脸的问题。简单的LBP记录像素和周围像素之间的对比度信息。LBP用于描述局部纹理特征。下面是一个例子。
SVM,支持向量机。给定一组训练示例,每个示例标记为属于两个类别中的一个或另一个,SVM训练算法建立一个模型,为一个或另一个类别分配新的例子,使其成为非概率二元线性分类器。SVM模型是空间中点的示例的表示,经过映射,以便单独类别的例子被一个尽可能宽的清晰间隙划分,如下图所示。
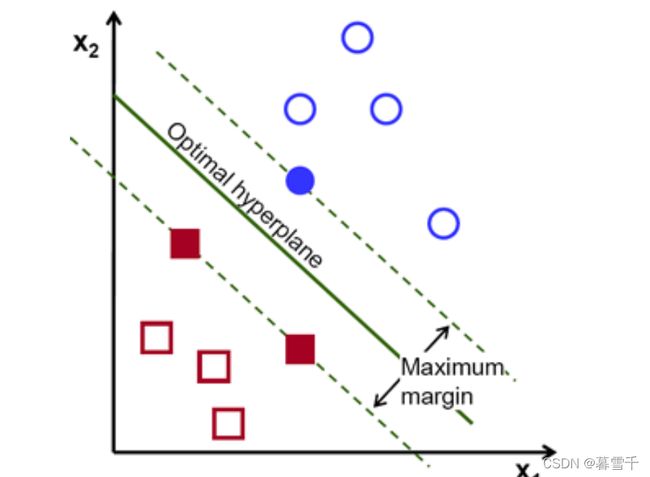
二、笑脸数据集训练
下载地址:mirrors / truongnmt / smile-detection · CODE CHINA
首先准备好GENKI-4K数据集
将文件中的图片重命名(smile)D:\picture\person4\smile-detection-master\datasets\train_folder\1
然后打开Jupyter notebook
划分数据集
import os, shutil #复制文件
# 原始目录所在的路径
# 数据集未压缩
original_dataset_dir0 = r'D:\picture\person4\smile-detection-master\datasets\train_folder\0'
original_dataset_dir1 = r'D:\picture\person4\smile-detection-master\datasets\train_folder\1'
# 我们将在其中的目录存储较小的数据集
base_dir = 'D:\\picture\\person4\\smile-detection-master\\datasets\\train_folder\\smile_small'
os.mkdir(base_dir)
# # 训练、验证、测试数据集的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 笑训练图片所在目录
train_smile_dir = os.path.join(train_dir, 'smile')
os.mkdir(train_smile_dir)
# 不笑训练图片所在目录
train_unsmile_dir = os.path.join(train_dir, 'unsmile')
os.mkdir(train_unsmile_dir)
# 笑验证图片所在目录
validation_smile_dir = os.path.join(validation_dir, 'smile')
os.mkdir(validation_smile_dir)
# 不笑验证数据集所在目录
validation_unsmile_dir = os.path.join(validation_dir, 'unsmile')
os.mkdir(validation_unsmile_dir)
# 笑测试数据集所在目录
test_smile_dir = os.path.join(test_dir, 'smile')
os.mkdir(test_smile_dir)
# 不笑测试数据集所在目录
test_unsmile_dir = os.path.join(test_dir, 'unsmile')
os.mkdir(test_unsmile_dir)
# 将前1000张笑图像复制到train_smile_dir
fnames = ['smile ({}).jpg'.format(i) for i in range(1,1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir1, fname)
dst = os.path.join(train_smile_dir, fname)
shutil.copyfile(src, dst)
# 将下500张笑图像复制到validation_smile_dir
fnames = ['smile ({}).jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir1, fname)
dst = os.path.join(validation_smile_dir, fname)
shutil.copyfile(src, dst)
# 将下500张笑图像复制到test_smile_dir
fnames = ['smile ({}).jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir1, fname)
dst = os.path.join(test_smile_dir, fname)
shutil.copyfile(src, dst)
# 将前1000张不笑图像复制到train_unsmile_dir
fnames = ['unsmile ({}).jpg'.format(i) for i in range(1,1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir0, fname)
dst = os.path.join(train_unsmile_dir, fname)
shutil.copyfile(src, dst)
# 将500张不笑图像复制到validation_unsmile_dir
fnames = ['unsmile ({}).jpg'.format(i) for i in range(700, 1200)]
for fname in fnames:
src = os.path.join(original_dataset_dir0, fname)
dst = os.path.join(validation_unsmile_dir, fname)
shutil.copyfile(src, dst)
# 将500张不笑图像复制到test_unsmile_dir
fnames = ['unsmile ({}).jpg'.format(i) for i in range(700, 1200)]
for fname in fnames:
src = os.path.join(original_dataset_dir0, fname)
dst = os.path.join(test_unsmile_dir, fname)
shutil.copyfile(src, dst)检测数据长度
print('total training cat images:', len(os.listdir(train_smile_dir)))
print('total training dog images:', len(os.listdir(train_unsmile_dir)))
print('total validation cat images:', len(os.listdir(validation_smile_dir)))
print('total validation dog images:', len(os.listdir(validation_unsmile_dir)))
print('total test cat images:', len(os.listdir(test_smile_dir)))
print('total test dog images:', len(os.listdir(test_unsmile_dir)))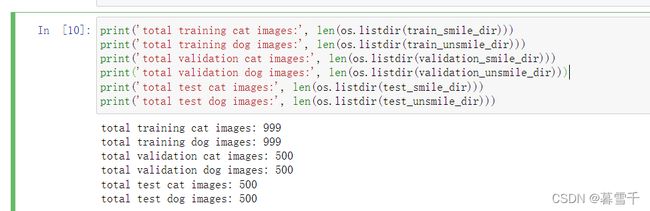
查看特征贴图的尺寸如何随每个连续层变化
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()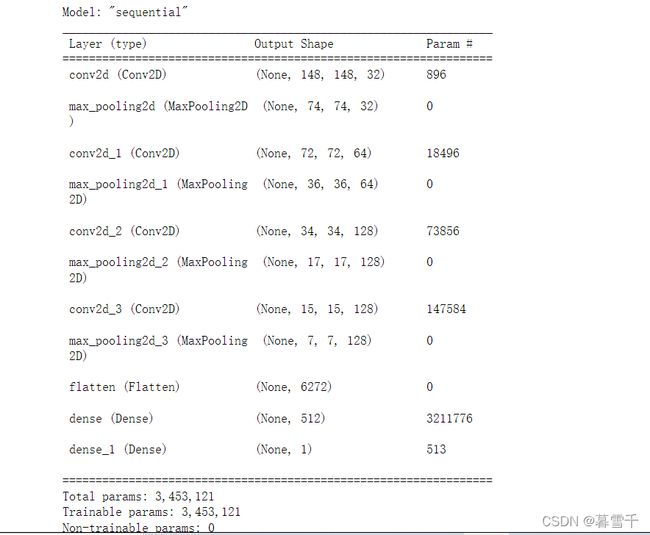
数据预处理
from tensorflow import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
生成器的输出
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break 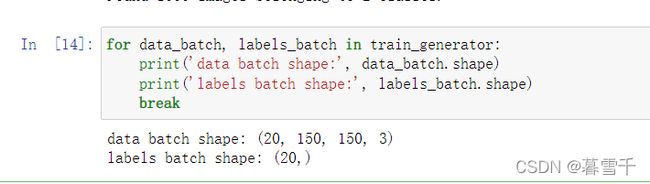
模型训练
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)训练模型的时候一共有30组,跑的时候很慢
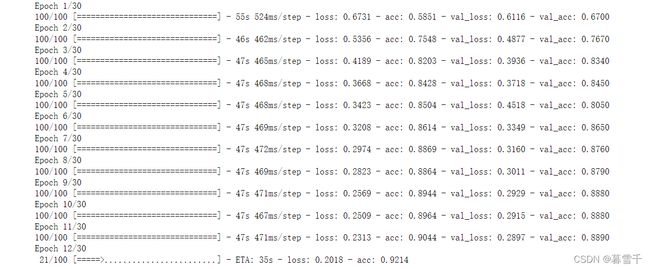
跑完数据之后保存模型
model.save('smile_and_unsmile_small_2.h5')
在训练和验证数据上绘制模型的损失和准确性
import os
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()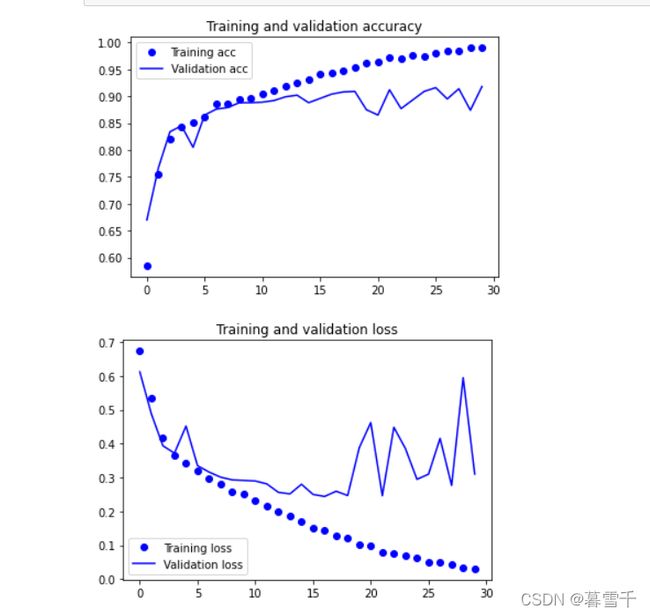
三、笑脸识别
摄像头调用识别笑脸
#检测视频或者摄像头中的人脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model(r'C:\Users\DEDSEC\smile_and_unsmile_small_2.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
if prediction[0][0]>0.5:
result='unsmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
##按q退出
if cv2.waitKey(5) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()运行结果

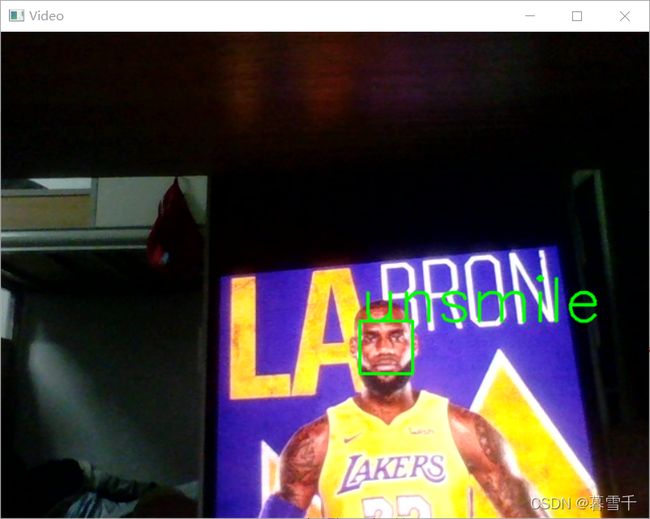
四、参考连接
Python-人脸识别并判断表情 笑脸或非笑脸 使用笑脸数据集genki4k_君琴 的博客-CSDN博客