目标检测中的尺度--An Analysis of Scale Invariance in Object Detection – SNIP
An Analysis of Scale Invariance in Object Detection – SNIP
Code will be made available at http://bit.ly/2yXVg4c
小伙伴们,知道 Larry S. Davis 是谁吗?
本文主要对目标检测中的尺度问题进行深入分析,如何实现多尺度目标检测,尤其是小目标检测。
结论:1)combining them with features from shallow layers would not be good for detecting small objects
1 Introduction
在图像分类这个问题上,深度学习的进步飞速,top-5 error on ImageNet classification 从 15% 降到 2%,这是一个 super-human level performance 在1000类图像分类问题上。但是在目标检测这个问题上,最好的检测器在 COCO 检测器只有 62%,即使在 50%的重合率上。那么为什么目标检测比图像分类难这么多了?
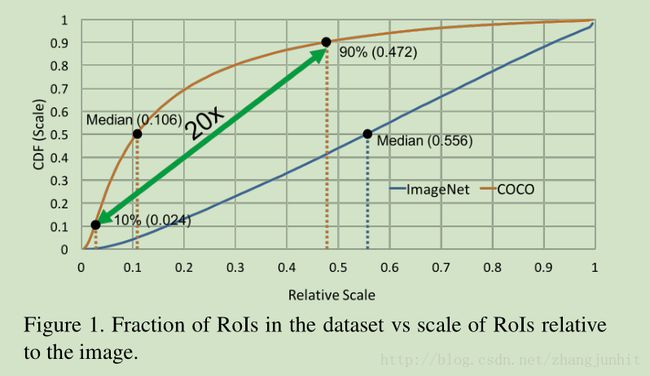
目标在图像中的大尺度变化范围,尤其是小目标检测的挑战是目标检测诸多难点中的显著一个。有意思的是在 ImageNet (classification) vs COCO (detection) 其中等尺度目标在图像中的占比分别是 0.554 and 0.106 respectively。所以在COCO 中大部分目标在图像中小于 1% 的面积。更糟糕的是在 COCO 最小最大10%的目标在图像中的占面积比是 0.024 and 0.472 respectively(导致尺度相差近20倍)。这种大尺度范围的变化导致目标检测需要 enormous and represents an extreme challenge to the scale invariance properties of convolutional neural networks,更糟糕的是我们的检测器一般都是在图像分类数据库上预训练,再进行微调得到的,但是检测和分类中的目标尺度差异很大,这有导致了一个大的 domain-shift 。本文首先提出上述问题的证据,然后提出一个 Scale Normalization for Image Pyramids 来解决这个问题。
前人是如何解决这个多尺度问题的了?1) 使用多尺度特征做检测,2)dilated/deformable convolution用于增加大目标的感受野,3) independent predictions at layers of different resolutions,4)context,5)多尺度训练,6)多尺度检测
虽然这些思路提升了目标检测的性能的,但是下面的问题仍然没有被解决?
1)放大图像对于目标检测的性能至关重要吗?尽管检测数据库中图像的尺寸大多是 480x640,为什么在实际中将图像放大到 800x1200?我们可以 在ImageNet 预训练时对小尺寸图像可以采用小的 strides,然后在检测数据库中微调来提升小目标的检测 吗?
2)当我们对预训练的分类模型在检测上进行微调得到一个检测器时,在对输入图像尺寸归一化后,训练的目标尺度需要限定在一个小的范围吗(from 64x64 to 256x256), 或者是 在放大输入图像后,需要对所有尺度目标参与训练吗? (from 16x16 to 800x1000, in the case of COCO)
2 Related Work
Scale space theory 提倡学习尺度不变的特征来解决这个多度问题。
当前CNN模型中的 deeper layers 具有较大的 strides (32 pixels),这导致了输入图像对应了一个 very coarse representation,这时的小目标检测很难做。为了解决这个问题,有人使用 dilated/atrous convolutions 来增加 feature map 的尺寸。Dilated/deformable 卷积也保留了预训练网络的 weights and receptive fields,所以对大目标检测性能没有下降。 在训练时将图像放大 1.5 to 2 ,在 inference 是 输入图像放大 4 倍 也是一个常用的增加 feature map 的尺寸的方法。因为考虑输入图像的网络层 feature map 的尺寸大,所以有人讲各个网络层的 feature map 结合起来做检测,也有分别在这些 feature map 上做检测。 方法如 FPN,Mask-RCNN,RetinaNet 采用了一个 pyramidal representation,将多网络层 feature map 结合起来检测。但是当目标尺寸为 25x25 像素时,即使在训练时放大 2倍,目标也只有 50x50 像素。通常在图像分类预训练的图像尺寸为 224x224,the high level semantic features (at conv5) generated even by feature pyramid networks will not be useful for classifying small objects (a similar argument can be made for large objects in high resolution images). 所以 将 shallow layers 的特征结合起来做检测,对于小目标检测效果不好。 尽管 feature pyramids 有效的综合了多卷积层特征图信息,但是对于very small/large objects 检测效果不是很好。

最近在文献【15】中提出一个金字塔方式检测人脸,对每个尺度的目标梯度 back-propagated,对于不同尺寸目标在分类层使用不同的滤波器。这个方法只适用于人脸检测,不适用于广义的目标检测 , because training data per class in object detection is limited and the variations in appearance, pose etc. are much larger compared to face detection。 这里我们的思路是 selectively back-propagate gradients for each scale and use the same filters irrespective of the scale of the object, thereby making better use of training data
3 Image Classification at Multiple Scales
首先我们来分析一下 the effect of domain shift,这是由 训练和检测图像尺寸不一样导致的:一般训练的图像尺寸是 800x1200 ,inference 的图像尺寸是 1400x2000(为了检测小目标)
首先我们对 original ImageNet database图像进行降采样 获得不同尺寸的图像 48x48, 64x64, 80x80, 96x96 and 128x128,然后再归一化到 224x224,用这个尺寸训练一个 CNN网络 referred to as CNN-B,我们得到的结论是: as the difference in resolution between training and testing images increases, so does the drop in performance,所以 testing on resolutions on which the network was not trained is clearly sub-optimal, at least for image classification

基于上述观察结果,一个提升小目标检测性能的方法就是 pre-train classification networks with a different stride on ImageNet,毕竟 在 CIFAR10 [17] (which contains small objects) 最好的网络结构不同于 ImageNet 上的。这个思路训练得到的网络为 CNN-S,明显比 CNN-B 要好。所以: it is tempting to pre-train classification networks with different architectures for low resolution images and use them for object detection for low resolution objects.
另一个提升小目标检测性能的方法是 fine-tune CNN-B on up-sampled low resolution images to yield CNN-B-FT,由此得出结论是: the filters learned on high-resolution images can be useful for recognizing low-resolution images as well

上面两个思路我们都可以提升小目标检测,我们如何选择了?放大图像比使用多个网络结构要好
Since pre-training on ImageNet (or other larger classification datasets) is beneficial and filters learned on larger object instances help to classify smaller object instances, upsampling images and using the network pre-trained on high resolution images should be better than a specialized network for classifying small objects.
首先预训练是有帮助的,毕竟可以给网络参数提供合理的初始化。第二就是大目标的训练样本 有助于 小目标的分类。为什么了? 主要是样本的多样性可以提升分类器性能。如果去除这些大中目标训练样本,小目标分类器的性能的会下降,毕竟大中目标在整个训练数据库中占比很大。
所以 放大输入图像+使用高分率图像预训练 要优于 专门针对小目标训练一个分类器
4 Background
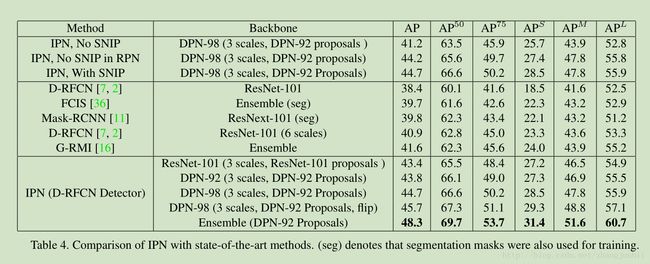
我们使用了 Deformable-RFCN [7] detector 作为我们的基准检测器。
5 Data Variation or Correct Scale?
这里我们主要分析 图像尺寸、目标尺寸、尺度范围对检测器性能的影响
This section analyses the effect of image resolution, the scale of object instances and variation in data on the performance of an object detector.

800all 对应的训练图像尺寸为 800x1200
1400all 对应的训练图像尺寸为 1400x2000
1400 <80px 对应 在 1400x2000 尺寸上训练,将大、中目标去除
MST: randomly sampled images at multiple resolutions during training
SNIP: training is only performed on objects that fall in the desired scale range and the remainder are simply ignored during back-propagation
结论:
1) 1400all 比 800all 效果要好,但是这种提升很小,为什么了? training at higher resolutions scales up small objects for better classification, but blows up the medium-to-large objects which degrades performance. 照顾了小目标,没能照顾上大中目标
2) 1400 <80px 效果最差,为什么了?失去了太多的重要训练样本
We lost a significant source of variation in appearance and pose by ignoring medium-to-large objects (about 30% of the total object instances) that hurt performance more than it helped by eliminating extreme scale objects
3) MST 性能和 800all 相当
We conclude that it is important to train a detector with appropriately scaled objects while capturing as much variation across the object instances as possible
SNIP
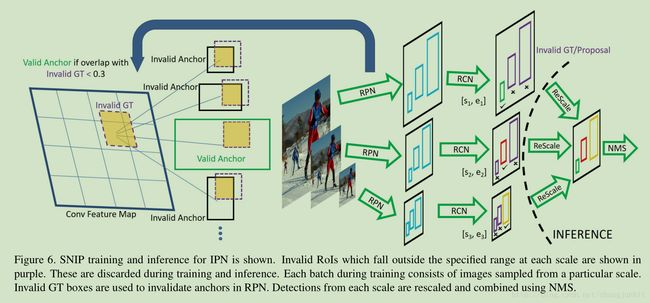
只训练合适尺寸的目标样本,太小太大的目标都不要,输入图像多尺度,总有一个尺寸是合适的。
7 Datasets and Evaluation