应用机器学习(四):Logistic 回归
Logistic 回归,也称logit 回归,是一个因变量是类别型变量的回归模型。
在这里,我们介绍0-1型因变量的情况,即,因变量只取0或1,可以表示例如
成功/失败、输/赢、存活/死亡、健康/患病等状态。Logistic 回归广泛应用
于机器学习、医学和社会科学领域。例如,在临床医疗中,根据观测的患者各项指标,如性别、年龄、身体质量指数(BMI )和血液检测等,预测该患者是否患糖尿病。再例如,在美国选举的民调预测,根据选民的年龄、性别、种族、收入、居住地和以往选举的投票情况,预测选民将投票支持民主党还是共和党。
Logit 回归模型
设自变量组成的输入向量 x ,因变量 y 是二值的,即,y∈{0,1}. 回归模型
在随机误差 ε 零均值的假设下,即, E(ε)=0 ,有
易见,回归函数 f(x)∈[0,1] ,所以使用 logit 函数代替。
Logit 函数,也称 sigmoid 函数,定义为
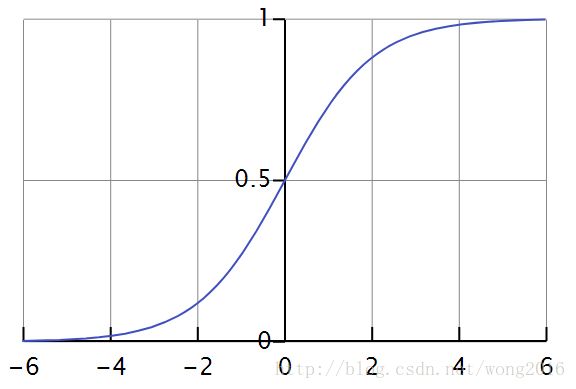
显然, logit 函数在 R 上是单调增加的,不妨设
则反函数为 η=lnζ1−ζ
现在,假设 η 是输入向量 x 的线性组合,即, η=βTx ,有
简记 p=P(y=1|x)=logit(βTx) .
现在,定义 logit 函数的逆 y ,得到
这样,就得到了一般的线性回归。
交叉熵误差函数
- 熵 (Entropy )
设一个随机变量 X ,分布为 p,定义
称 H(X) 为 X 的熵(entropy ),有时也记为 H(p),用它来度量 X (或分布 p )的不确定性。
- 交叉熵 (cross entropy )
设定义在相同事件集上的两个概率分布 p,q ,称
为分布 p,q 的交叉熵。
交叉熵在信息论的意义是,当我们用分布 q 作为“代码书”,编码来自分布 p 的数据所用的平均比特(bit )数。
- 交叉熵最小原则
交叉熵最小化(cross-entropy minimization )经常用于模型优化和稀有事件概率估计。
假设比较分布 q 和一个固定的参考分布 p,可以证明
因此,在 logistic 回归中,可以用交叉熵作为损失函数来优化模型。
参数的最大似然估计
已知样本 (xi,yi) , i=1,2,…,n.yi∈{0,1} . 则
由 yi 的概率函数 P(yi)=pyii(1−pi)1−yi , i=1,2,…,n .
真实概率用类标签 {yi,1−yi} 代替,近似概率用 logit 函数 {pi,1−pi} 代替。
则
这样, n 个实例的总损失为 ∑i=1nH(yi,pi),这恰好是
负对数似然(negative log-likelihood ),简记为
Logistic 回归的最优解
关于 β 的梯度和 Hessian 矩阵分别为
令设计矩阵 X=(x1,x2,…,xn)′ , y=(y1,y2,…,yn)′ ,
p=(p1,p2,…,pn)′ , 则
其中, S=diag(pi(1−pi)) ,
由于 H 是正定的,所以 NLL 是凸函数,存在唯一的全局最小值。与普通线性回归不同的是,找不到 β 闭形式的解,因此,通常采用优化算法解决。下面介绍几种常用的优化算法。
- 梯度下降法
梯度下降(Gradient descent)也称最速下降(Steepest descent), 是一阶迭代优化算法。它的基本原理是,为了找到一个函数的局部最小值,沿该函数在当前点的梯度的反方向以一定的步长搜索。
设多元函数 F(x) 在 a 点的邻域内有定义且可微,如果点从 a 沿着该点梯度的负方向, −▽F(a) 变化,那么函数 F(x)
下降最快。现在,在定义域内随机取一点 x0 作为初始最小值点,考虑点序列 x0,x1,…,
我们有
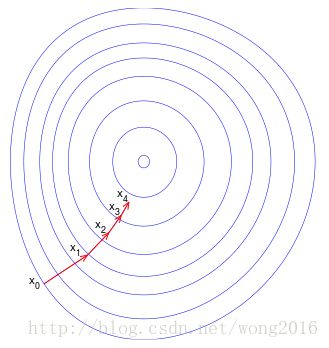
当 F 是凸函数,选择合适的步长 γ′s ,可以使 F 收敛到全局最小值点。这一过程如图所示,这里,设 F 是定义在平面上的二元函数,图中的蓝线是等高线,即,等高线上的点,函数值相等。等高线的值由外向内依次减小。红色箭头依次指向梯度下降的方向。注意到,负梯度方向垂直于经过某点的等高线。我们看到,梯度下降的方向指向“碗底”,即, F 的最小值点。
在Logistic 回归中,设损失函数 Loss(β) 为负对数似然,即
在梯度下降法中,为了保证损失函数收敛到全局最小值点(无论初始点如何选择),我们取相同的步长,不妨设为 α ,则迭代公式为
由 Taylor 定理,
故
这里,步长 α 如果选的太小,可能导致收敛的慢或不能收敛到局部最优解。为此,我们选择
称为线最小化( line minimization )或线搜索( line search ).
- 牛顿迭代法
另外一种更快速的优化方法,考虑函数的曲率,即 Hessian 矩阵,称为二阶优化方法,这里介绍典型的方法——牛顿迭代法。首先介绍牛顿迭代法的基本原理。
设多元函数 f(θ) 在 θk 点存在二阶偏导数,则它在该点的二阶 Taylor 展式为
其中, ▽f 为梯度, H=(∂2f∂xi∂xj) 为 Hessian 矩阵。
令 Ak=12Hk,bk=▽f(θk)−Hkθk,ck=f(θk)−▽f(θk)Tθk+12θTkHkθk ,
则 f 的最小值点在

将牛顿迭代法应用于上面定义的损失函数 Loss(β) 。
- 迭代加权最小二乘法
迭代加权最小二乘(Iteratively reweighted least squares, or IRLS)
现在,使用牛顿迭代法求二值 Logistic 回归参数的最大似然估计。
Hessian 矩阵 H=XTSX ,取搜索步长 αk=1 , 代入牛顿迭代公式,有
其中
这是一个加权最小二乘问题的例子,它是以下优化问题的解:
又由于 Sk 是对角阵,所以
该算法称为迭代加权最小二乘法(Iteratively reweighted least squares ),简记 IRLS。在每一次迭代,我们计算权矩阵 Sk=diag(p(k)i(1−p(k)i)) 的加权
最小二乘估计。

拟合优度
在 Logistic 回归模型里,我们用偏差(Deviance )来度量模型拟合数据的程度。首先,定义”饱和”模型(“saturated” model ):
称一个理论上完美的拟合为”饱和”模型。然后,通过对比拟合模型与”饱和”模型来计算偏差,这要通过似然比检验实现:定义检验统计量
D 近似服从 χ2 分布。 D 值越小,表明拟合模型与”饱和”模型偏差越小,模型越优。通常,找不到”饱和”模型,这时,定义
在 Logistic 回归里,两个重要的偏差度量是:零偏差与模型偏差。定义为:
其中,零模型( null model )是指仅含常数项,即,没有预测变量的模型。那么,
如果 D 值较大,即,模型偏差显著地小于零偏差,则预测变量显著地改善了模型拟合。
回归系数的检验
- 优势比(odds ratio /OR )
设 Logistic 回归模型
定义
- 连续变量
设 xj 连续,则定义 OR=odds(xj+1)odds(xj)=eβj 。
指数关系给出了回归系数 βj 的解释: xj 每增加一个单位, odds 乘 eβj 。
- 二值变量
设 xi∈{0,1} 是二值变量,则定义 OR=odds(xi=1)odds(xi=0)
- Wald 检验
为了检验预测变量 xj 对回归模型的贡献,定义Wald 统计量
其中, SE(βj) 是 βj 的标准误( standard error )。
Wj 渐近服从 χ2 分布。当数据稀疏时, Wj 偏差较大。
例子:婚外情调查

AER 包的 Affairs 数据集,即著名的婚外情数据 Fair’s Affairs,源于
《今日心理学》( Psychology Today )杂志在1969年所做的一次非常具有代表性的调查。该数据调查了601个参与者的9个变量,它们分别是:
- affairs —— 最近一年婚外私通的次数
- gender —— 参与者性别
- age —— 年龄
17.5 = under 20, 22 = 20–24, 27 = 25–29, 32 = 30–34, 37 = 35–39, 42 = 40–44, 47 = 45–49, 52 = 50–54, 57 = 55 or over - yearsmarried —— 婚龄
0.125 = 3 months or less, 0.417 = 4–6 months, 0.75 = 6 months–1 year, 1.5 = 1–2 years, 4 = 3–5 years, 7 = 6–8 years, 10 = 9–11 years, 15 = 12 or more years - children —— 是否有子女
- education —— 受教育程度
9 = grade school, 12 = high school graduate, 14 = some college, 16 = college graduate, 17 = some graduate work, 18 = master’s degree, 20 = Ph.D., M.D., or other advanced degree - religiousness —— 宗教信仰程度
1 = anti, 2 = not at all, 3 = slightly, 4 = somewhat, 5 = very - occupation —— 职业
- rating —— 婚姻的自我评分
1 = very unhappy, 2 = somewhat unhappy, 3 = average, 4 = happier than average, 5 = very happy
下面显示该数据集的描述性统计量
data(Affairs, package = "AER")
summary(Affairs)
table(Affairs$affairs)![]()
从这些统计信息可以看到,52%的调查对象是女性,72%的人有孩子,样本年龄的中位数为32岁。对于响应变量,72%的调查对象表示过去一年中没有婚外情(451/601),而婚外偷腥的最多次数为12(占了6%)。虽然这些婚姻的轻率举动次数被记录下来,但此处我们感兴趣的是二值型结果(有过一次婚外情/没有过婚外情)。因此,将 affairs 转化为二值型因子 ynaffair。
Affairs$ynaffair[Affairs$affairs > 0] <- 1
Affairs$ynaffair[Affairs$affairs == 0] <- 0
Affairs$ynaffair <- factor(Affairs$ynaffair,
levels = c(0, 1),
labels = c("No", "Yes"))
table(Affairs$ynaffair) No Yes
---------- ----------
451 150
该二值型因子现可作为Logistic 回归的结果变量:
fit.full <- glm(ynaffair ~ gender + age + yearsmarried + children +
religiousness + education + occupation + rating,
data = Affairs, family = binomial())
summary(fit.full)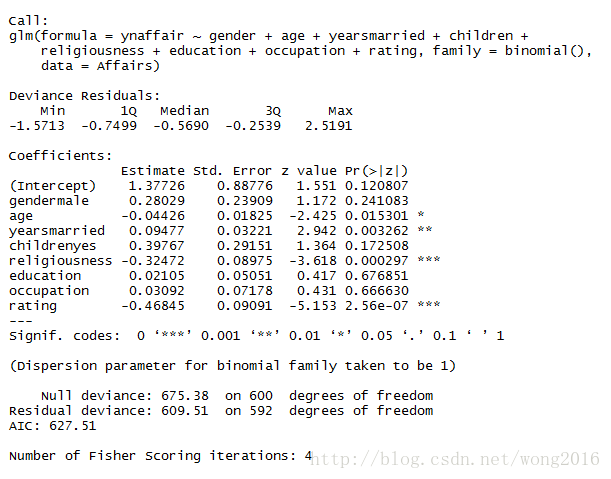
从回归系数的 p 值(最后一栏)可以看到,性别、是否有孩子、学历和职业对方程的贡献都不显著(你无法拒绝参数为0的假设)。去除这些变量重新拟合模型,检验新模型是否拟合得好:
fit.reduced <- glm(ynaffair ~ age + yearsmarried + religiousness +
rating, data = Affairs, family = binomial())
summary(fit.reduced)
新模型的每个回归系数都非常显著(p<0.05)。由于两模型嵌套(fit.reduced 是 fit.full 的一个子集),你可以使用 anova ()函数对它们进行比较,对于广义线性回归,可用 χ2 检验。
anova(fit.reduced, fit.full, test = "Chisq")
结果的卡方值不显著(*p8=0.21),表明四个预测变量的新模型与九个完整预测变量的模型拟合程度一样好。这使得你更加坚信添加性别、孩子、学历和职业变量不会显著提高方程的预测精度,因此可以依据更简单的模型进行解释。
- 解释模型参数
先看看回归系数:
coef(fit.reduced)![]()
在 Logistic 回归中,响应变量是 Y =1的对数优势比(log)。回归系数含义是当其他预测变量不变时,一单位预测变量的变化可引起的响应变量对数优势比的变化。由于对数优势比解释性差,你可对结果进行指数化:
exp(coef(fit.reduced))![]()
可以看到婚龄增加一年,婚外情的优势比将乘以1.106(保持年龄、宗教信仰和婚姻评定不
变);相反,年龄增加一岁,婚外情的的优势比则乘以0.965。因此,随着婚龄的增加和年龄、宗
教信仰与婚姻评分的降低,婚外情优势比将上升。因为预测变量不能等于0,截距项在此处没有
什么特定含义。
如果有需要,你还可使用confint()函数获取系数的置信区间。例如,exp(confint
(fit.reduced))可在优势比尺度上得到系数95%的置信区间。
最后,预测变量一单位的变化可能并不是我们最想关注的。对于二值型Logistic回归,某预
测变量n个单位的变化引起的较高值上优势比的变化为 eβnj ,它反映的信息可能更为重要。比
如,保持其他预测变量不变,婚龄增加一年,婚外情的优势比将乘以1.106,而如果婚龄增加10
年,优势比将乘以 1.10610 ,即2.7。
- 评价预测模型对结果概率的影响
对于我们大多数人来说,以概率的方式思考比使用优势比更直观。使用predict ()函数,你可观察某个预测变量在各个水平时对结果概率的影响。首先创建一个包含你感兴趣预测变量值的虚拟数据集,然后对该数据集使用predict ()函数,以预测这些值的结果概率。现在我们使用该方法评价婚姻评分对婚外情概率的影响。首先,创建一个虚拟数据集,设定年龄、婚龄和宗教信仰为它们的均值,婚姻评分的范围为1~5。
testdata <- data.frame(rating = c(1, 2, 3, 4, 5),
age = mean(Affairs$age),
yearsmarried = mean(Affairs$yearsmarried),
religiousness = mean(Affairs$religiousness))
testdata
接下来,使用测试数据集预测相应的概率:
testdata$prob <- predict(fit.reduced, newdata = testdata,
type = "response")
testdata
从这些结果可以看到,当婚姻评分从1(很不幸福)变为5(非常幸福)时,婚外情概率从0.53降低到了0.15(假定年龄、婚龄和宗教信仰不变)。下面我们再看看年龄的影响:
testdata <- data.frame(rating = mean(Affairs$rating),
age = seq(17, 57, 10),
yearsmarried = mean(Affairs$yearsmarried),
religiousness = mean(Affairs$religiousness))
testdata
testdata$prob <- predict(fit.reduced, newdata = testdata,
type = "response")
testdata
此处可以看到,当其他变量不变,年龄从17增加到57时,婚外情的概率将从0.34降低到0.11。利用该方法,你可探究每一个预测变量对结果概率的影响。
- 过度离势
抽样于二项分布的数据的期望方差是 σ2=np(1−p) , n 为观测数,
p=P(y=1). 所谓过度离势,即观测到的响应变量的方差大于期望的二项分布的方差。过度离势会导致奇异的标准误检验和不精确的显著性检验。当出现过度离势时,仍可使用glm ()函数拟合 Logistic 回归,但此时需要将二项分布改为类二项分布(quasibinomial distribution ). 检测过度离势的一种方法是比较二项分布模型的残差偏差与残差自由度,如果比值:
比1大很多,你便可认为存在过度离势。回到婚外情的例子,可得:
它非常接近于1,表明没有过度离势。
你还可以对过度离势进行检验。为此,你需要拟合模型两次,第一次使用 family =” binomial “,第二次使用 family = “ quasibinomial“。假设第一次 glm ()返回对象记为 fit,第二次返回对象记为 fit.od,那么:
pchisq(summary(fit.od)$dispersion * fit$df.residual,
fit$df.residual, lower = FALSE)提供的p 值即可对假设 H0:Φ=1H1:Φ≠1 进行检验, 若p 很小(小于0.05),则拒绝零假设。将其应用到婚外情数据集,可得:
fit <- glm(ynaffair ~ age + yearsmarried + religiousness +
rating, family = binomial(), data = Affairs)
fit.od <- glm(ynaffair ~ age + yearsmarried + religiousness +
rating, family = quasibinomial(), data = Affairs)
pchisq(summary(fit.od)$dispersion * fit$df.residual,
fit$df.residual, lower = FALSE)[1] 0.340122
此处p 值(0.34) 显然不显著 ( p > 0.05),这更增强了我们认为不存在过度离势的信心。
阅读更多精彩内容,请关注微信公众号 —— 统计学习与大数据