联邦学习框架浅析
【前言】
▲ 联邦学习问题回顾
前文提及,于2016年,Google提出了用于训练输入法模型的新型方式,称为「联邦学习」。随着时间的推移,联邦学习不再是单纯解决Google输入法模型的一种解决方案,进而形成了一种新型的学习模式。联邦学习解决的问题通常被称为TMMPP–Training Machine Learning Models over multiple data sources with Privacy,即在保证多方参与者的数据不泄露的情况下,共同完成预定模型的训练。
在联邦学习解决的TMMPP问题中,包含了n个数据方(Data Controller){D1,D2,…Dn},其中,每个数据方对应拥有着n个数据{P1,P2,…Pn}。从联邦学习的训练模式来看,在选定好需要进行训练的联邦学习算法后,需为联邦学习提供相应的输入,最终得到训练后的输出。
联邦学习的输入(Input): 每个数据方将Pi其拥有的原始数据Di作为联合建模的输入,输入进联邦学习的进程中。
联邦学习的输出(Output):联合所有参与方的数据,联邦训练出全局模型M (在训练过程中不将任何数据方的原始数据的任何信息透露给其他实体)。
▲ 联邦学习所遇挑战
联邦学习技术还在持续的完善中。在发展的过程中,联邦学习会遇到三大挑战,他们分别分别是统计挑战、效率挑战、安全挑战。
【统计挑战】统计挑战是在联邦学习执行过程中,因为不同用户数据的分布或者数据量的差异造成的挑战;
a)非独立同分布数据(Non-IID data),即不同用户数据分布不独立,有明显的分布差别,比如甲方拥有的是中国北方的水稻种植数据,而乙方拥有的是中国南方水稻种植数据,由于纬度,气候,人文等影响,双方的数据是不服从于同分布的;
b)非平衡数据(Unbalanced data),即用户的数据量有明显的差异,比如巨头企业掌握着近千万的数据量,而小公司仅掌握数万条的数据,两者合作,小公司的数据对巨头企业的影响微乎其微,也难以在模型训练中做出贡献。
【效率挑战】效率挑战指的是在联邦学习中各个节点本地计算与通信的消耗造成的挑战;
a)通信开销,即用户(参与方)节点之间的通信,通常指的是在限定带宽的前提下,各个用户之间传输的数据量的大小,数据量越大,则通信损耗越高;
b)计算复杂度,即基于底层加密协议的计算复杂度,通常指底层加密协议计算的时间复杂度,算法计算逻辑越复杂,消耗时间越多。
【安全挑战】安全挑战指的是,在联邦学习过程中,不同的用户使用不同的攻击手段造成信息破解、下毒等挑战;
a)半诚实模型,即各用户诚实的执行联邦学习中的所有协议,但是会利用获取信息尝试分析并回推他人数据;
b)恶意模型,即存在客户不会严格遵守节点之间的协议,并可能对原始数据或者中间数据进行下毒以破坏联邦学习进程。
【联邦学习常用框架】
面对以上三大挑战,学术界进行针对性的研究,提出了许多有效的、专用的联邦学习框架来优化联邦学习训练过程。下文我们将对这些框架进行简单介绍。
联邦学习1.0 – 传统联邦学习(Federated Learning)
首先,我们重新阐述一下联邦学习的概念与原理:存在若干参与方与协作方共同执行联邦学习任务,参与方(即数据拥有方)通过预置好的联邦学习算法,生成类似于梯度的中间数据,交由协调方进行进一步的处理,随后返还给各参与方,为下一轮的训练做准备。
周而复始,联邦学习任务完成。整个任务中,参与方的本地数据在各个FL框架中并没有参与交换,但协调方和参与方之间传输的参数(比如梯度)可能会泄漏敏感信息。
为了保护数据拥有方的本地数据不被泄露,并在训练过程中保护中间数据的隐私,在FL的框架中应用了一些隐私技术,在参与方与协调方交互时私下交换参数。进一步,从 FL 框架中使用的隐私保护机制来看,将 FL框架分为:
1)非加密的联邦学习框架(即未对任何信息加密);
2)基于差分隐私的联邦学习框架(使用差分隐私的方式对信息进行混淆加密);
3)基于安全多方计算的的联邦学习框架(使用安全多方计算的方法对信息进行加密) ;
▲ 非加密的联邦学习框架
许多FL框架侧重于提高效率或解决统计异质性的挑战,而忽略了交换明文参数所带来的潜在风险。
2015年,由Nishio等人提出的用于机器学习的移动边缘计算框架FedCS[3],在异构数据属主的设置的基础上,可以快速并高效地执行FL。
2017年,由Smith等人提出了一个名为MOCHA[2]的系统感知优化框架,该框架将FL与多任务学习相结合,通过多任务学习的方式来处理统计挑战中的非同分布数据与数据量差异导致的各种挑战。
同年,梁等人提出了LG-FEDAVG[4]结合局部表示学习(local representation learning)。他们表明,局部模型可以更好地处理异构数据,并有效地学习公平的表示,混淆受保护的属性。
下图所示:完全未加密任何中间数据的联邦学习流程,所有的中间数据(如梯度)全是明文传输与计算。通过以上方式,参与方最终共同学习,得到联邦学习模型。

▲ 基于差分隐私的联邦学习框架
差分隐私(DP) 是一种隐私技术[5-7],具有很强的信息理论保证,可以在数据[8-10]中增加噪声。满足 DP 的数据集可以抵抗对私有数据的任何分析,换句话说,所获得的数据敌手对于在同一数据集中推测其他数据几乎是无用的。通过在原始数据或模型参数中添加随机噪声,DP 为单个记录提供统计隐私保证,从而使数据无法恢复以保护数据属主的隐私。
下图所示:采取差分隐私对中间数据进行加密后的联邦学习流程,各方生成的中间数据不再是明文传输计算,而是添加过噪声的隐私数据,以此来进一步增强训练过程的安全性。
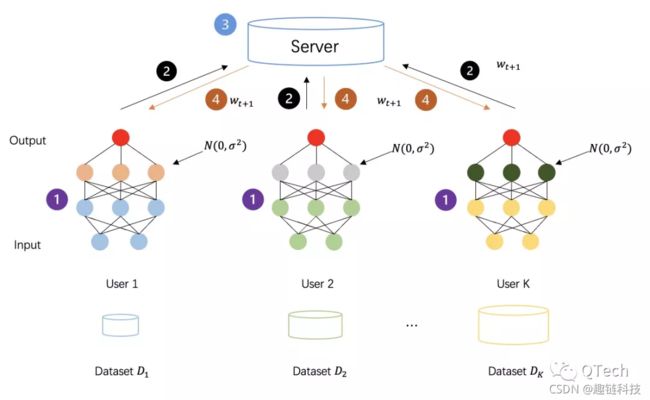
▲ 基于安全多方计算的联邦学习框架
在FL框架中,同态加密(HE)和安全多方计算(MPC)等方法得到了广泛的应用,但它们只向参与方与协调方揭示了计算结果,过程中并没有透露任何除计算结果外的额外的信息。
实际上,HE应用于FL框架的方式与应用于安全多方学习(MPL)框架(一种FL衍生出的框架,下文会详细说明MPL框架)的方式类似,只是细节上略有不同。在FL框架中,HE用于保护参与方和协调方之间交互的模型参数(如梯度)的隐私,而不是像MPL框架中应用的HE那样直接保护参与方之间交互的数据。[1]在FL模型中应用加法同态(AHE)来保护梯度的隐私,以提供针对半诚信中心化协调方的安全性。
MPC 涉及多个方面,并保留了原有的准确性,具有很高的安全性保证。MPC保证了每一方除了结果之外什么都不知道。因此MPC可以应用于 FL 模型中,用于安全聚合并保护本地模型。在基于MPC 的 FL 框架中,集中式的协调方不能获得任何本地信息和本地更新,而是在每一轮协作获得聚合结果。然而,如果在FL框架中应用 MPC 技术将会产生大量额外的通信和计算成本。
迄今为止,秘密共享(SS )是在 FL 框架中应用最广泛的MPC基础协议,特别是 Shamir 的 SS[24]。
下图所示:基于MPC的联邦学习训练流程,会由参与方公平的选举出一组委员会成员作为协调方,通过执行MPC技术来协作完成模型聚合的任务。

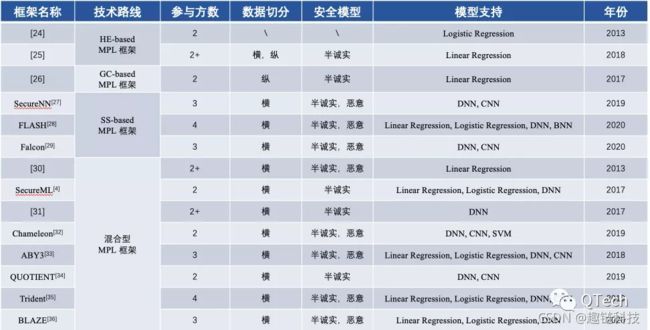
介绍完三种FL框架后,我们总结不同技术路线的框架区别,大体如下:

联邦学习2.0 – 安全多方学习(Secure Multi-party Learning)
上文我们提到到「安全多方学习」,这是基于联邦学习衍生出的一个术语,简单来说就是:没有第三方协作方的联邦学习,被称之为安全多方学习(MPL),与先前所介绍的FL区分开来。换言之,在联邦学习的基础上,安全多方学习剔除了传统联邦学习模式中的协调方,并弱化了协调方的能力,将原本的星形网络替换成点对点网络并使得所有参与方的地位相同。
MPL的框架大体分为四类,包括:
1)基于同态加密(HE)的 MPL 框架;
2)基于混淆电路(GC)的 MPL 框架;
3)基于秘密共享(SS)的 MPL 框架;
4)基于混合协议的 MPL 框架;
简单来说,不同的MPL框架即为:使用了不同的密码学协议来保障中间数据安全的框架。MPL的流程与FL大体类似,我们一起看一下使用过的四种密码学协议:
▲ 同态加密(HE)
同态加密(HE)是一种加密形式,我们可以在不解密,不知道密钥的前提下,直接对密文执行特定的代数操作。然后,它生成一个加密结果,其解密结果与在明文上执行的相同操作的结果完全相同。
HE 可以分为「三种类型」:1)部分同态加密 (PHE),PHE只允许无限次的一种操作(加法或乘法);2)-3)有限同态加密(SWHE)与全同态加密(FHE),为了在密文中同时进行加法和乘法SWHE和FHE 。SWHE 可以在有限次数内执行某些类型的操作,而 FHE 可以在无限次数处理所有操作。FHE 的计算复杂度比 SWHE 和 PHE 要昂贵得多。
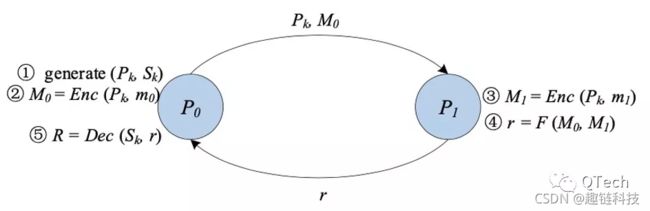
▲ 混淆电路 (GC)
混淆电路[11][12](GC),又称姚氏(Yao’s) 混淆电路,是由姚期智院士提出的一种安全的两方计算的底层技术。GC提供了一个交互式协议,让两方(一个混淆者garbler和一个评估者evaluator)对一个任意函数进行无意识的评估,这个函数通常表示为一个布尔电路。
在经典 GC 的构造中主要包括三个阶段:加密、传输、评估。
首先,对于电路中的每一条线,混淆者生成两个随机字符串作为标签,分别代表该线可能的两个位值“0”和“1”。对于电路中的每一个门,混淆者都会创建一个真值表。真值表的每个输出都是用与其输入相对应的两个标签进行加密。这是由混淆者选择一个密钥推导函数,利用这两个标签生成对称密钥。
然后,混淆者对真值表的行进行换行。在混淆阶段结束后,混淆者将混淆后的表以及与其输入为对应的输入线标签传送给评估者。
此外,评估者通过不经意传输(Oblivious Transfer[13,14,15])安全地获取其输入对应的标签。有了混淆表和输入线的标签,评估者负责对混淆表进行反复解密,直至得到函数的最终结果。
▲ 秘密共享(SS)
GMW协议是第一个安全的多方计算协议,允许任意数量的一方安全地计算一个可以表示为布尔电路或算术电路的函数。以布尔电路为例,所有各方使用基于 XOR的SS方案共享输入,各方交互计算结果,逐门计算。基于GMW的协议不需要对真值表进行混淆,只需要进行XOR和AND运算进行计算,所以不需要进行对称的加解密操作。此外,基于GMW的协议允许预先计算所有的加密操作,但在在线阶段需要多方进行多轮交互。因此,GMW在低延迟网络中取得了良好的性能。
BGW协议是3方以上的算术电路安全多方计算的协议。该协议的总体结构与 GMW类似。一般来说,BGW 可以用来计算任何算术电路。与GMW协议类似,对于电路中的加法门,计算是可以在本地进行的,而对于乘法门,各方需要交互。但是,GMW和BGW在交互形式上有所不同。BGW不是使用OT来进行各方之间的通信,而是依靠线性SS(如 Shamir 的 SS)来支持乘法运算。但BGW 依靠的是诚实多数制 (honest-majority)。BGW 协议可以对抗除t SPDZ是 Damgard 等人提出的一种不诚实多数制计算协议,它能够支持两方以上的计算算术电路。它分为离线阶段和在线阶段。SPDZ的优势在于昂贵的公钥密码计算可以在离线阶段完成,而在线阶段则纯粹使用廉价的、信息理论上安全的基元。SWHE用于在离线阶段执行constant-round的安全乘法。SPDZ的在线阶段是linear-round ,遵循GMW范式,在有限域上使用秘密共享来确保安全。SPDZ最多可以对抗恶意敌手的t<=n个腐坏方,其中t为敌手数量,n为计算方数。 将集中密码学协议进行阶段性总结,不同技术路线对应的框架区别大体如下: 联邦学习3.0 – 群学习(Swarm Learning) 2021年,波恩大学的 Joachim Schultze 和他的合作伙伴提出了一种名为 Swarm Learning(群学习)的「去中心化机器学习系统」,这是基于MPL进一步的衍化升级,它取代了当前跨机构医学研究中集中数据共享的方式。Swarm Learning 通过 Swarm 网络共享参数,再在各个参与方的本地数据上独立构建模型,并利用区块链技术对试图破坏 Swarm 网络的不诚实参与者采取强有力的措施。 相较于FL与MPL, Swarm Learning将区块链的技术引入到联邦学习的训练过程中,很好地将区块链取代了公信第三方,起到训练协同的作用。 【总结与展望】 这其中,我们将传统的FL与MPL进行更深层次的对比,体现在以下六点: 隐私保护 通信方式 通信开销 数据格式 训练模型的准确性 应用场景 ▲ 联邦学习框架多方比较 基于FL的MPL基础框架的内容对比 随着联邦学习技术的不断发展,针对不同挑战的联邦学习平台不断涌现,但仍未达到成熟的阶段。目前,在学术界中,联邦学习平台主要解决的问题是非平衡与非同分布的数据问题,而工业界更多的把眼光放在了密码学协议上来解决联邦学习的安全问题。 两边齐头并进,将现有的很多机器学习算法实现了联邦化,但仍不成熟,并未达到可以落地投产的阶段。近几年,联邦学习框架的研究与落地仍处于初级阶段,需要持续不断的努力和推进。 作者简介 [2] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206. [3] D. Demmler, T. Schneider, and M. Zohner, “Aby-a framework for efficient mixed-protocol secure two-party computation.” in Proceedings of The Network and Distributed System Security Symposium, 2015. [4] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy- preserving machine learning,” in Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 19–38. [5] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, “Feder- ated learning of deep networks using model averaging,” CoRR, vol. abs/1602.05629, 2016. [6] J. Konecˇny`, H. B. McMahan, D. Ramage, and P. Richta ́rik, “Federated optimization: Distributed machine learning for on-device intelligence,” arXiv preprint arXiv:1610.02527, 2016. [7] J. Konecˇny`, H. B. McMahan, F. X. Yu, P. Richta ́rik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communica- tion efficiency,” arXiv preprint arXiv:1610.05492, 2016. [8] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” in Proceedings of Artificial Intelligence and Statistics, 2017, pp. 1273–1282. [9] A. C.-C. Yao, “How to generate and exchange secrets,” in Proceedings of the 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). IEEE, 1986, pp. 162–167. [10] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proceedings of Advances in Neural Information Processing Systems, 2017, pp. 4424–4434. [11] R. Fakoor, F. Ladhak, A. Nazi, and M. Huber, “Using deep learning to enhance cancer diagnosis and classification,” in Proceedings of the international conference on machine learning, vol. 28. ACM New York, USA, 2013. [12] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in Proceedings of European conference on computer vision. Springer, 2016, pp. 525–542. [13] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823. [14] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017. [15] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206. [16] T.NishioandR.Yonetani,“Clientselectionforfederatedlearningwith heterogeneous resources in mobile edge,” in Proceedings of 2019 IEEE International Conference on Communications (ICC). IEEE, 2019, pp. 1–7. [17] P. P. Liang, T. Liu, L. Ziyin, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,” arXiv preprint arXiv:2001.01523, 2020. [18] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient vertical federated learning framework,” arXiv preprint arXiv:1912.11187, 2019. [19] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggre- gation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191. [20] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, and Q. Yang, “Se- cureboost: A lossless federated learning framework,” arXiv preprint arXiv:1901.08755, 2019. [21] G. Xu, H. Li, S. Liu, K. Yang, and X. Lin, “Verifynet: Secure and verifiable federated learning,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 911–926, 2019. [22] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, “Learn- ing differentially private recurrent language models,” arXiv preprint arXiv:1710.06963, 2017. [23] Y. Zhao, J. Zhao, M. Yang, T. Wang, N. Wang, L. Lyu, D. Niyato, and K. Y. Lam, “Local differential privacy based federated learning for internet of things,” arXiv preprint arXiv:2004.08856, 2020. [24] M. Hastings, B. Hemenway, D. Noble, and S. Zdancewic, “Sok: General purpose compilers for secure multi-party computation,” in Proceedings of 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1220–1237. [25] I. Giacomelli, S. Jha, M. Joye, C. D. Page, and K. Yoon, “Privacy- preserving ridge regression with only linearly-homomorphic encryp- tion,” in Proceedings of 2018 International Conference on Applied Cryptography and Network Security. Springer, 2018, pp. 243–261. [26] A. Gasco ́n, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Privacy-preserving distributed linear regression on high- dimensional data,” Proceedings on Privacy Enhancing Technologies, vol. 2017, no. 4, pp. 345–364, 2017. [27] S. Wagh, D. Gupta, and N. Chandran, “Securenn: 3-party secure computation for neural network training,” Proceedings on Privacy Enhancing Technologies, vol. 2019, no. 3, pp. 26–49, 2019. [28] M. Byali, H. Chaudhari, A. Patra, and A. Suresh, “Flash: fast and robust framework for privacy-preserving machine learning,” Proceedings on Privacy Enhancing Technologies, vol. 2020, no. 2, pp. 459–480, 2020. [29] S. Wagh, S. Tople, F. Benhamouda, E. Kushilevitz, P. Mittal, and T. Rabin, “Falcon: Honest-majority maliciously secure framework for private deep learning,” arXiv preprint arXiv:2004.02229, 2020. [30] V. Nikolaenko, U. Weinsberg, S. Ioannidis, M. Joye, D. Boneh, and N. Taft, “Privacy-preserving ridge regression on hundreds of millions of records,” pp. 334–348, 2013. [31] M. Chase, R. Gilad-Bachrach, K. Laine, K. E. Lauter, and P. Rindal, “Private collaborative neural network learning.” IACR Cryptol. ePrint Arch., vol. 2017, p. 762, 2017. [32] M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, and F. Koushanfar, “Chameleon: A hybrid secure computation frame- work for machine learning applications,” in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018, pp. 707–721. [33] P. Mohassel and P. Rindal, “Aby3: A mixed protocol framework for machine learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 35– 52. [34] N. Agrawal, A. Shahin Shamsabadi, M. J. Kusner, and A. Gasco ́n, “Quotient: two-party secure neural network training and prediction,” in Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, pp. 1231–1247. [35] R. Rachuri and A. Suresh, “Trident: Efficient 4pc framework for pri- vacy preserving machine learning,” arXiv preprint arXiv:1912.02631, 2019. [36] A. Patra and A. Suresh, “Blaze: Blazing fast privacy-preserving ma- chine learning,” arXiv preprint arXiv:2005.09042, 2020. [37] Song L, Wu H, Ruan W, et al. SoK: Training machine learning models over multiple sources with privacy preservation[J]. arXiv preprint arXiv:2012.03386, 2020.

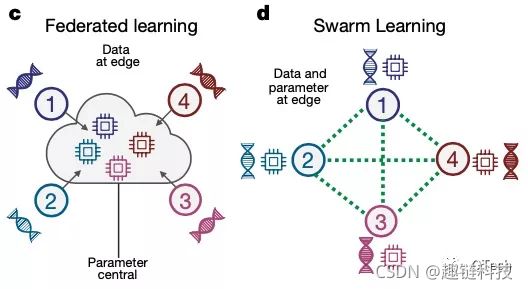
▲ 联邦学习技术路线比较
纵观联邦学习的前世今生,其已经拥有了多种解决问题的技术路线,经总结,分布式机器学习(DML),联邦学习(FL),安全多方学习(MPL),群学习(SL)的差异大体如下:

MPC 框架中使用的 MPC 协议为双方提供了很高的安全性保证。然而,非加密 FL 框架在数据属主和服务器之间交换模型参数是明文的,敏感信息也可能被泄露;
在 MPL 中,数据属主之间的通信通常是在没有可信第三方的情况下以对等的形式进行的,而 FL 通常是以具有集中式服务器的 Client-Server的形式进行的。换句话说,MPL中的每个数据属主在状态上是相等的,而 FL 中的数据属主和集中式服务器是不对等的;
对于 FL,由于数据属主之间的通信可以由一个中心化服务器来协调,通信开销比 MPL 的点对点形式更小,特别是当数据属主的数量非常大时;
目前,在 MPL 的解决方案中,不考虑非 IID 设置。然而,在FL的解决方案中,由于每个数据属主都在本地训练模型,因此更容易适应非 IID 设置;
在 MPL 中,在全局模型中通常没有精度损失。但如果 FL 利用 DP 保护隐私,全局模型通常会有一定的准确性损失;
结合上述分析,可以发现 MPL 更适合于安全性和准确性较高的场景,而 FL 更适合于性能要求较高的场景,用于更多的数据拥有方。

自2016年FL基础性框架的内容对比
严杨 联邦学习后驱者
趣链科技数据网格实验室BitXMesh团队
参考文献
[1] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.