深度学习代码篇(pytorch实现)
文章目录
- 一、Dataset加载数据——获取数据及其label
- 二、tensorboard的使用
-
- 1. add_image()函数——显示image
- 2. add_scalar()函数——显示函数
- 三、torchvision中transform.py的使用
- 三、torchvision中数据集的使用
- 四、Dataloader打包压缩——为网络提供不同的数据形式
- 五、神经网络
-
- 1. 神经网络基本骨架(简单使用)
- 2. 卷积层(convolution layers)
- 3. 最大池化的使用(pooling layers)
- 4. 非线性激活(Non-linear Activations)
-
- relu
- sigmoid
- 5. 线性层(Linear Layers)(全连接层)
- 6. 搭建网络
- 7. 通过 torch.nn.Sequential 使得网络搭建代码更加简洁
- 8. loss function
- 9. 优化器
- 10. 在pytorch提供的网络模型的基础上进行修改
- 10. 网络模型的保存和读取
-
- 保存方式1
- 保存方式2
- 六、完整模型的训练套路
-
- GPU加速训练
- 七、完整模型的验证套路
一、Dataset加载数据——获取数据及其label
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir) #传递的是图片的相对地址
self.img_path_list = os.listdir(self.path) #将相对地址变为列表形式(可按index找指定的图像)
def __getitem__(self, idx):
img_name = self.img_path_list[idx] #图像名字
img_item = os.path.join(self.root_dir,self.label_dir,img_name) #图像全貌(相对地址要具体到单张图片)
img = Image.open(img_item)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path_list)
root_dir = "dataset1/train"
ants_dir = "ants"
bees_dir = "bees"
ant_dataset = MyData(root_dir,ants_dir)
bees_dataset = MyData(root_dir,bees_dir)
train_dataset = ant_dataset + bees_dataset
print(train_dataset[124])
img,label = train_dataset[124]
print(label)
img.show()
结果:(
'bees'
class MyData(Dataset):表示这个类继承括号中的类,并且要求重写类内函数。
在类的函数中含self. 的都是新建的属性
二、tensorboard的使用
1. add_image()函数——显示image
要想在tensor中查看图像,要在虚拟环境中输入:tensorboard --logdir=logs打开网址即可
from torch.utils.tensorboard import SummaryWriter #载入SummaryWriter类
import numpy as np
from PIL import Image
#调用该类中函数 生成的事件文件 存到logs这个文件夹(和py文件在同一目录下)中
writer = SummaryWriter("logs") #用SummaryWriter类初始化对象
image_path = "dataset1/train/ants/0013035.jpg" #相对地址
image_PIV= Image.open(image_path) #打开图像(PIV(pic)类型)
img_numpy = np.array(image_PIV) #转换为numpy类型
#或者这么获得numpy类型
# import cv2
# image_path = "dataset/train/ants/0013035.jpg"
# img_numpy = cv2.imread(img_path) #生成numpy类型的img,传递的参数为相对地址
#或者利用totensor转换为tensor型再传参
#在tensorboard中显示图像
#图像名,numpy型或者tensor型,step(前为numpy型才加上dataformats='HWC')
writer.add_image("image",img_numpy,1,dataformats='HWC')
writer.close()
SummaryWriter类中的add_image()函数中传的参数是numpy类型或者tensor类型,不能是pil类型。
2. add_scalar()函数——显示函数
from torch.utils.tensorboard import SummaryWriter #载入SummaryWriter类
writer = SummaryWriter("logs")
for i in range(100):
#在tensorboard中显示函数
writer.add_scalar("y=x",2*i,i) #函数名,y,x
writer.close()
三、torchvision中transform.py的使用
transfrom对象中传的参数可以是 tensor类型,也可以是pil类型
头文件及初始定义:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "dataset1/train/bees/16838648_415acd9e3f.jpg"
img_PIV = Image.open(img_path)#(PIV(pic)类型)
- totensor,作用是使得pic或者numpy型 转换为tensor型
#实例化对象(transforms.py中的ToTensor类)
totensor_ob = transforms.ToTensor()
#隐含方式 调用内置函数(可按citrl+p查看参数类型)(参数为piv类型)
img_tensor = totensor_ob(img_PIV)
- Normalize 归一化
#每个通道的均值,每个通道的标准差(彩色图一般为3个通道数)
norm_ob = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
#参数为tensor类型
img_norm = norm_ob.forward(img_tensor)
#在tensor中显示
# writer = SummaryWriter("logs")
# writer.add_image("normalize",img_tensor,0)
# writer.close()
- resize用法1
print(img_PIV.size) #原先的 图片尺寸
resize1_ob = transforms.Resize((512,512)) #(高度,宽度)
img_resize1 = resize1_ob(img_PIV) #参数为pil类型(也可以为tensor)
print(img_resize1) #输出重置尺寸之后的 图片参数
结果:
(500, 450)# W H (宽度,高度)
<PIL.Image.Image image mode=RGB size=512x512 at 0x14F0DB1C7C0>
- resize用法2在Compose混合操作函数(之所以要用compose,是为了方便加入totensor函数,以便于在tensorboard中显示图像)
#在之前尺寸的基础上等比缩放
resize2_ob = transforms.Resize(256) #256匹配w和h较小的那个数,然后另外一个数根据比例缩放
#参数为transforms类型(对象)的列表
compose_ob1 = transforms.Compose([resize2_ob,totensor_ob])
img_resize2 = compose_ob1(img_PIV) #参数为pil类型(也可以为tensor)
print(img_resize2.size()) #输出等比缩放后的图片size,图片为tensor类型
结果:torch.Size([3, 256, 284]) #CHW
- randomcrop用在compose混合操作函数
random_ob = transforms.RandomCrop(256) #将原图随机裁剪为(256*256)的尺寸或者传参(m,n)
compose_ob2 = transforms.Compose([random_ob,totensor_ob]) #实例化对象
img_random = compose_ob2(img_PIV) #参数为pil类型(也可以为tensor)
print(img_random.size()) #输出随即裁剪之后的图片size,图片为tensor类型
结果:torch.Size([3, 256, 256])
三、torchvision中数据集的使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
data_transform_ob = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) #等号左边为transforms类型的对象
# 数据集本身是piv类型,经过transform=data_transform_ob后,转换为tensor类型
train_set = torchvision.datasets.CIFAR10(root="./dataset2",train=True,transform=data_transform_ob,download=True) #训练集
test_set = torchvision.datasets.CIFAR10(root="./dataset2",train=False,transform=data_transform_ob,download=True) #测试集
#生成的事件文件存到pictures这个文件夹(和py文件在同一目录下)中
writer = SummaryWriter("pictures")
for i in range(10):
img,label = test_set[i] #将test_set[i]分离,得到tensor类型的img
writer.add_image('test_set',img,i) #一个图象共10步
writer.close()
img,label = test_set[i]:
比如test_set[5]表示cifar10测试集中按顺序数第六个图片,这个图片可能是10种类型label图片中的任意一种,图片类型不同,label也就不同。
test_set[5]为列表形式: [img的信息,label(为数字,一个数字表示一个类型)]
四、Dataloader打包压缩——为网络提供不同的数据形式
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#1. 载入数据集
test_data = torchvision.datasets.CIFAR10("./dataset2",train=False,transform=torchvision.transforms.ToTensor())
#2. 打包数据集
#batch_size=64表示一次性抓取几个数据,shuffle=True表示第二轮抓取是否打乱,drop_last=False表示到最后不足batch_size的图片是否丢掉
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#3. tensorboard显示
writer = SummaryWriter("loaderdata")
#第一轮抓取,每一次都随机抓取batch_size张图片进行打包。
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images("test1",imgs,step)
step = step+1
#第二轮抓取
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images("test2", imgs, step)
step = step + 1
writer.close()
将数据进行打包之后,以batch_size=64为例,相当于数据集中的test_data[0[~test_data[63](或64—127)为一组进行显示,
五、神经网络
1. 神经网络基本骨架(简单使用)
import torch
from torch import nn
#神经网络的输入和输出,以及负责处理的类
class PXD (nn.Module): #表示继承括号中的类
def __init__(self) -> None:
super().__init__()
def forward(self,input):
output = input+1
return output
pxd = PXD() #初始化对象
input = torch.tensor(1.0) #将1.0转换为tesor类型
output = pxd.forward(input)
print(output)
结果:tensor(2.)
2. 卷积层(convolution layers)
- torch.Size中的各个参数:
torch.Size(batch_size,通道数,尺寸,尺寸)(NCHW) - 只有三通道及以下的图片才可以被显示出来。
- 多通道转为少通道时,batch_size会增多
- 卷积之后,图像尺寸会变小(因为padding设置为0即不填充),若填充,则保持原尺寸
- 卷积层的stride默认为1
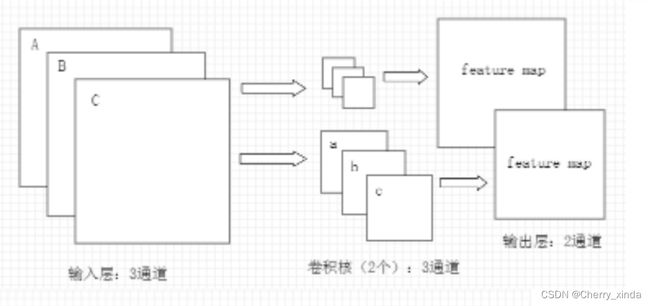
- 卷积核 通道数 = 卷积 输入层 的 通道数
卷积核 个数 = 卷积 输出层 通道数(深度)
在卷积层的计算中,假设输入是H x W x C, C是输入的深度(即通道数),那么卷积核(滤波器)的通道数需要和输入的通道数相同,所以也为C,假设卷积核的大小为K x K,一个卷积核就为K x K x C。
计算时卷积核的对应通道应用于输入的对应通道,这样一个卷积核应用于输入就得到一个输出通道,假设有P个K x K x C的卷积核,这样每个卷积核应用于输入都会得到一个通道,所以会输出P个通道。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
#输入通道数,输出通道数,卷积核大小,步长,是否在周围进行数据填充
self.cov1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) #根据条件可知,卷积核的通道数为3,个数为6
def forward(self,input):
output = self.cov1(input)
return output
pxd = PXD() #实例化对象
writer = SummaryWriter("cov")
step = 0
for data in dataloader:
imgs,targets = data
output = pxd.forward(imgs)
# print(imgs.shape) #torch.Size([64,3,32,32])
# print(output.shape) #torch.Size([64,6,30,30])
writer.add_images("input",imgs,step)
output = torch.reshape(output,(-1,3,30,30)) # batch_size自己算
writer.add_images("output",output,step)
step = step+1
writer.close()
tensorboard中的显示:
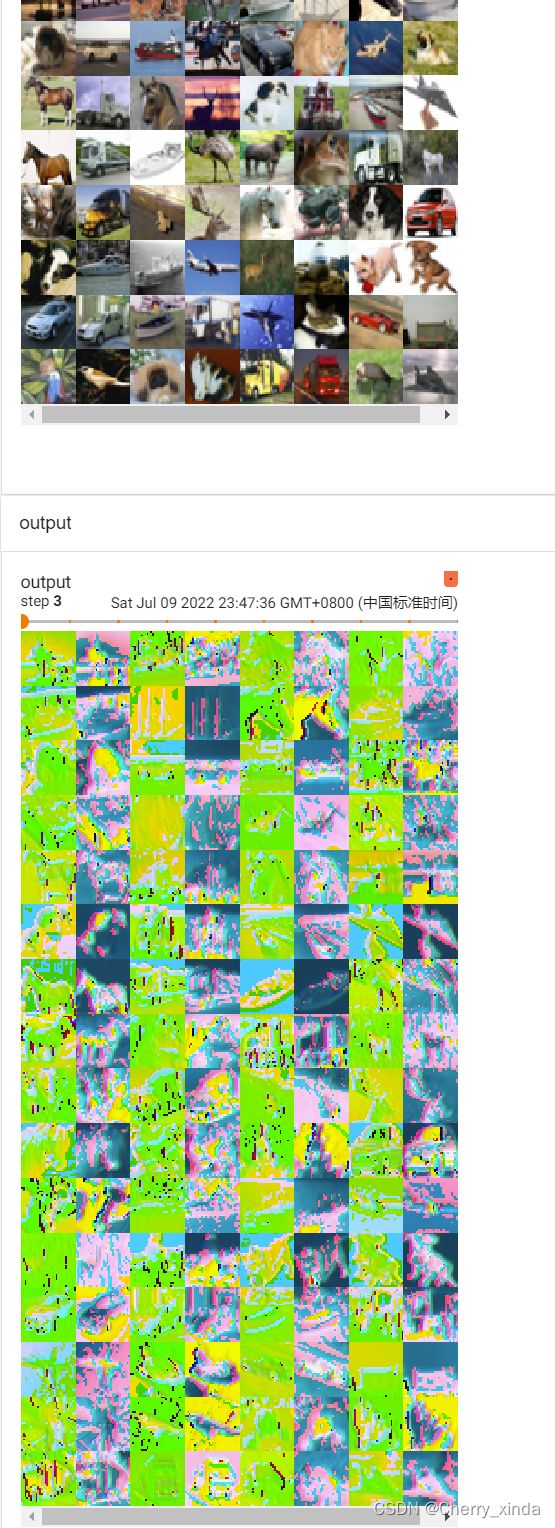
卷积:可以通过改变 卷积核的个数 改变输出图片的通道数,还可以使得输出图片的尺寸变小
3. 最大池化的使用(pooling layers)
- ceil_mode有两种取整方式:floor向下取整(不保留),ceiling向上取整(保留)
ceil_mode默认为False,即为floor取整模式,ceil_mode为True时,为ceiling取整模式
所谓保留和不保留指的是:池化核在input上移动时,如果覆盖不上kernel_size池化核大小的数字,那么就涉及到了保留还是不保留的问题。 - 池化层的stride默认不是1,而是kernel_size的值(池化核的大小)
- 池化后,图像尺寸减小(也可以通过设置padding使得尺寸保持不变),但是输出通道数不变,而卷积之后输出的通道数取决于卷积核的个数。
代码示例1:
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,5,5))
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True) #stride默认为kernel_size,ceil_mode默认为False
def forward(self,input):
output = self.maxpool1(input)
return output
pxd = PXD()
output = pxd.forward(input)
print(output)
结果:
tensor([[[[2.]]]]) # ceil_mode=False
tensor([[[[2., 3.],
[5., 1.]]]]) #ceil_mode=True
代码示例2:
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset2",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True) #stride默认为kernel_size
def forward(self,input):
output = self.maxpool1(input)
return output
pxd = PXD()
writer = SummaryWriter("maxpool")
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = pxd(imgs)
writer.add_images("output",output,step) #不用调整通道数
step = step+1
writer.close()
结果:
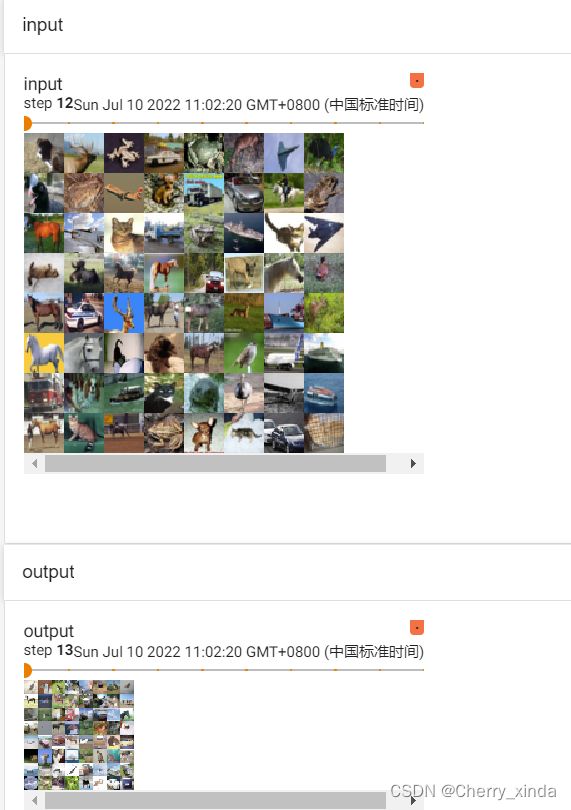
- 最大池化后,不改变输出通道数,但图像尺寸变小。
input_size:(64,3,32,32),3个pool_size:(-1,3,3,3),output_size:(64,3,11,11)
4. 非线性激活(Non-linear Activations)
relu
relu激活函数:小于0的返回0,大于0的返回input
import torch
from torch import nn
from torch.nn import ReLU #引入截断非线性激活函数
input = torch.tensor([[1,-0.5],
[-1,3]],dtype=torch.float32)
input = torch.reshape(input,(-1,1,2,2)) #NCHW,-1表示自己计算batch_size
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.relu = ReLU(inplace=False) #默认为False,表示不就地处理,而是赋值给output
def forward(self,input):
output = self.relu(input)
return output
pxd = PXD()
output = pxd.forward(input)
print(output)
print(output.shape)
结果:
tensor([[[[1., 0.],
[0., 3.]]]])
torch.Size([1, 1, 2, 2])
sigmoid
sigmoid激活函数:output为0到1,为较平滑的范围。
可以使得被处理后的图片亮度降低,失去高光。
代码使用模式与relu相同
5. 线性层(Linear Layers)(全连接层)
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
#线性层可以使得1
dataset = torchvision.datasets.CIFAR10("./dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64,drop_last=True)
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear = nn.Linear(in_features=32,out_features=10) #size of each input sample,size of each output sample
def forward(self,input):
output = self.linear(input)
return output
pxd = PXD()
for data in dataloader:
imgs,targets = data
print(imgs.shape) #torch.Size([64, 3, 32, 32])
output = pxd.forward(imgs)
print(output.shape) #torch.Size([64, 3, 32, 10]) NCHW
线性层的目的是:
改变图像前后的宽度width,高度height不变
矩阵中来看:改变的是列数(维数),行数不变
in_features为原图像的宽度(列数)
线性层实质:
将展平的特征行向量,经过全连接层后,改变了宽度(列数)(维度)
6. 搭建网络
要通过搭建网络完成如下操作:
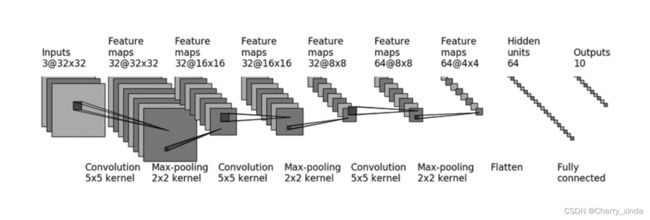
计算padding要用到的公式:

图片input在神经网络最后阶段,最后经过flatten()后,会被平展成为1行1024列的特征矩阵,高度H为1,宽度W为1024,在经过两个线性层,变为1行10列的特征矩阵。
注意:
输入input为图片,也具体化为x,图片的参数有像素,通道数等等。
神经网络中有权重参数,为w,与input的像素点相乘,会被不断更新。
import torch
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2)
self.maxpool1 = MaxPool2d(kernel_size=2)
self.cov2 = Conv2d(32,32,5,1,2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,5,1,2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten() #平展
self.linear1 = Linear(in_features=1024,out_features=64)
self.linear2 = Linear(64,10)
def forward(self,input):
input = self.conv1(input)
input = self.maxpool1(input)
input = self.cov2(input)
input = self.maxpool2(input)
input = self.conv3(input)
input = self.maxpool3(input)
input = self.flatten(input)
input = self.linear1(input)
output = self.linear2(input)
return output
pxd = PXD()
print(pxd)
#检验网络的正确性(不报错则证明正确):
input = torch.ones((64,3,32,32))
output = pxd.forward(input)
print(output.shape)
结果:
PXD(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
7. 通过 torch.nn.Sequential 使得网络搭建代码更加简洁
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model1 = Sequential(Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024,out_features=64),
Linear(64,10))
def forward(self,input):
output = self.model1(input)
return output
pxd = PXD()
print(pxd)
#检验网络的正确性(不报错则证明正确):
input = torch.ones((64,3,32,32))
output = pxd(input)
print(output.shape)
8. loss function
作用1 :计算实际输出和目标之间的差距
作用2 :为我们更新输出提供一定的依据(反向传播)
import torch
from torch.nn import L1Loss,MSELoss,CrossEntropyLoss
inputs = torch.tensor([1.,2.,3.]) #输入
targets = torch.tensor([1.,2.,5.]) #目标
inputs = torch.reshape(inputs,(-1,1,1,3))
targets = torch.reshape(targets,(-1,1,1,3))
#1. L1Loss
loss1 = L1Loss() #计算输入和目标差值的和的平均值
result1 = loss1(inputs,targets)
print(result1)
loss2 = L1Loss(reduction='sum') #计算输入和目标差值的和
result2 = loss2(inputs,targets)
print(result2)
#2. MSELoss
loss3 = MSELoss() #计算输入和目标方差的平均值
result3 = loss3(inputs,targets)
print(result3)
#3. CrossEntropyLoss 交叉熵
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3)) #1个batch_size,3类 (N,W)
loss_cross = CrossEntropyLoss()
result4 = loss_cross(x,y)
print(result4)
结果:
tensor(0.6667)
tensor(2.)
tensor(1.3333)
tensor(1.1019)
9. 优化器
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model1 = Sequential(Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024,out_features=64),
Linear(64,10))
def forward(self,input):
output = self.model1(input)
return output
pxd = PXD()
#这一步的目的是加载图片数据集,得到targets方便计算损失,得到imgs以便得到输出
dataset = torchvision.datasets.CIFAR10("./dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
loss = nn.CrossEntropyLoss() #初始化损失
optim = torch.optim.SGD(pxd.parameters(),lr=0.01) #选择优化器,参数:模型,学习率,不同优化器后面的参数不同
for epoch in range(20):#训练20轮
running_loss = 0
for data in dataloader:
imgs,targets = data
outputs = pxd.forward(imgs)
result_loss = loss(outputs,targets) #计算损失
optim.zero_grad() #梯度清零
result_loss.backward() #反向传播,更新参数
optim.step() #优化器进行优化
running_loss = running_loss + result_loss
print(running_loss) #计算每一轮损失函数的值
结果:
tensor(360.3538, grad_fn=<AddBackward0>)
tensor(354.5248, grad_fn=<AddBackward0>)
tensor(334.0772, grad_fn=<AddBackward0>)
tensor(319.1064, grad_fn=<AddBackward0>)
...........#可见,通过训练学习,损失越来越小,
10. 在pytorch提供的网络模型的基础上进行修改
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16()
print(vgg16)
# 结果:
# VGG(
# (features): Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (18): ReLU(inplace=True)
# (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (20): ReLU(inplace=True)
# (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (22): ReLU(inplace=True)
# (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (25): ReLU(inplace=True)
# (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (27): ReLU(inplace=True)
# (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (29): ReLU(inplace=True)
# (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
# )
vgg16.classifier.add_module('add_linear',nn.Linear(1000,10)) #通过添加线性层,使得分类减少(维数减少)vgg16.classifier.add_module('add_linear',nn.Linear(1000,10)) #通过添加线性层,使得分类减少(维数减少)
10. 网络模型的保存和读取
保存方式1
保存:
vgg16 = torchvision.models.vgg16()#如果是自己写的网络模型,此步不写
torch.save(vgg16,"vgg16_method1.pth") #网络模型,名字
加载:
#如果是自己写的模型,需要在这一行写上神经网络或者头文件中from model import*
#但是不用再实例化了
model = torch.load("vgg16_method1.pth") #相对地址 model为实例化的网络模型 对象
print(model)
保存方式2
保存:
vgg16 = torchvision.models.vgg16()
torch.save(vgg16.state_dict(),"vgg16_method2.pth") #网络模型,名字
加载:
vgg16 = torchvision.models.vgg16()
vgg16.load_state_dict(torch.load("vgg16_method2.pth")) #相对地址
print(vgg16)
六、完整模型的训练套路
print("-------第 {}轮训练开始-------".format(i+1)) 字符串函数,用 i+1 替换 {}
accuracy = (outputs.argmax(1) == targets).sum() 用于计算每一次训练的正确率,1表示按行看寻最大值
训练的基本思路:
我们要训练的对象是神经网络,我们先初步构建神经网络,如卷积,池化等,然后第一轮让训练集通过创建好的神经网络的这些层,使得训练集的图片变为特征图(类似于高亮变灰白)(使得容易训练神经网络),然后让特征图(outputs) 和 targets相比来通过损失函数获得损失,然后再经过优化器优化、损失反向传播 使得神经网络中的层的参数逐渐被优化更新,然后经过n轮训练,直到更加接近target。
如何知道神经网络被训练的效果怎么样呢?(是否适应模型)
通过测试集。 让测试集经过神经网络,看看每一轮的损失或者正确率(分类问题常用)如何,进而判断训练效果。
为什么要在每一轮过后要保存网络模型呢?
因为神经网络在每一轮训练过后参数都会被优化更新,网络模型实质上发生了变化。
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
#device = torch.device("cuda") 也表示在gpu中训练
#dataset 准备数据集
train_dataset = torchvision.datasets.CIFAR10(root="./dataset2",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.CIFAR10(root="./dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#length 长度
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print("训练数据集的长度为{}".format(train_dataset_size))
print("测试数据集的长度为{}".format(test_dataset_size))
#dataloader 加载数据集
train_dataloader = DataLoader(train_dataset,batch_size=64)
test_dataloader = DataLoader(test_dataset,batch_size=64)
#实例化网络模型
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model1 = Sequential(Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024,out_features=64),
Linear(64,10))
def forward(self,input):
output = self.model1(input)
return output
pxd = PXD()
pxd = pxd.cuda() #GPU训练 #pxd = pxd.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss() #交叉熵
loss_fn = loss_fn.cuda() #GPU训练 #loss_fn = loss_fn.to(device)
#添加tensorboard便于观察损失函数变化
writer = SummaryWriter("loss")
#优化器
learning_rate = 1e-2 #0.01
optimizer = torch.optim.SGD(pxd.parameters(),lr=learning_rate) #选用sgd优化器
#设置神经网络的一些参数
total_train_step = 0 #训练的次数
total_test_step = 0 #测试的次数
epoch = 10 #训练的轮数
for i in range(epoch):
print("-------第 {}轮训练开始-------".format(i+1))
#训练步骤开始
pxd.train()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.cuda() #GPU #imgs = imgs.to(device)
targets = targets.cuda() #GPU #targets = targets.to(device)
outputs = pxd.forward(imgs) #让输入通过层层特征提取网络(前向传播)
#特征提取:输入的像素点矩阵x * 权重参数矩阵w的过程,像素矩阵x的行列(形状)会发生变化,权重矩阵w的元素值将来会被不断更新。
loss = loss_fn(outputs,targets) #计算在dataloader中一次训练的损失(每一轮输出的得分和真实值作比较的过程)
#优化器优化
optimizer.zero_grad() #梯度清零
loss.backward() #反向传播,求解损失函数梯度
optimizer.step() #更新权重参数
total_train_step = total_train_step + 1
if(total_train_step % 100 == 0):
print("训练次数:{},此次训练的Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#验证步骤开始(验证训练结果怎么样)
pxd.eval()
total_test_loss = 0
total_test_accuracy = 0
#无梯度的目的是:正处在验证阶段,所以不用对梯度进行调整,无需优化神经网络参数,也可以节省内存
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.cuda() #GPU #imgs = imgs.to(device)
targets = targets.cuda() #GPU #targets = targets.to(device)
outputs = pxd.forward(imgs)
#特征提取网络经过该轮训练,神经网络参数w被更新,将输入图片放入该网络后的到的得分值被记录下来
loss = loss_fn(outputs,targets) #计算损失
total_test_loss = total_test_loss + loss
accuracy = (outputs.argmax(1) == targets).sum() #正确率的分子
total_test_accuracy = total_test_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_test_accuracy/test_dataset_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_test_accuracy/test_dataset_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(pxd,"tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
前三轮次的结果:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为50000
测试数据集的长度为10000
-------第 1轮训练开始-------
训练次数:100,此次训练的Loss:2.287644147872925
训练次数:200,此次训练的Loss:2.281564712524414
训练次数:300,此次训练的Loss:2.258236885070801
训练次数:400,此次训练的Loss:2.173457145690918
训练次数:500,此次训练的Loss:2.0533664226531982
训练次数:600,此次训练的Loss:2.0135819911956787
训练次数:700,此次训练的Loss:1.9880279302597046
整体测试集上的loss:314.1552734375
整体测试集上的正确率:0.28039997816085815
模型已保存
-------第 2轮训练开始-------
训练次数:800,此次训练的Loss:1.8499757051467896
训练次数:900,此次训练的Loss:1.823794960975647
训练次数:1000,此次训练的Loss:1.880897879600525
训练次数:1100,此次训练的Loss:1.9815046787261963
训练次数:1200,此次训练的Loss:1.7078672647476196
训练次数:1300,此次训练的Loss:1.6430387496948242
训练次数:1400,此次训练的Loss:1.7231780290603638
训练次数:1500,此次训练的Loss:1.7968997955322266
整体测试集上的loss:301.3468017578125
整体测试集上的正确率:0.3149999976158142
模型已保存
-------第 3轮训练开始-------
训练次数:1600,此次训练的Loss:1.7480535507202148
训练次数:1700,此次训练的Loss:1.638698697090149
训练次数:1800,此次训练的Loss:1.9216716289520264
训练次数:1900,此次训练的Loss:1.7019065618515015
训练次数:2000,此次训练的Loss:1.8428000211715698
训练次数:2100,此次训练的Loss:1.5035483837127686
训练次数:2200,此次训练的Loss:1.5163278579711914
训练次数:2300,此次训练的Loss:1.7925814390182495
整体测试集上的loss:267.4210205078125
整体测试集上的正确率:0.3807999789714813
模型已保存
通过每一轮训练后的结果,我们可以观察到测试集上的整体loss在逐轮次下降、正确率逐轮次提高,表明神经网络经过每一轮的训练,神经网络的参数在不断被优化,损失越来越小,神经网络越来越适应模型。
GPU加速训练
只能在以下环节中利用GPU加速:
- 网络模型
- 数据(imgs,targets)(输入,标注(eg:‘dogs’))
- 损失函数
七、完整模型的验证套路
类似于训练套路中的测试集那里
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
img_path = "./pictures/dog.png"
image = Image.open(img_path) #以pil类型打开
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Resize((32,32))])
image = transform(image)
image = image.cuda() #因为网络模型是用gpu训练的,所以测试的输入图片应该.cuda()
print(image.shape)
#使用第一种方式加载网络
class PXD(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model1 = Sequential(Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32,32,5,1,2),
MaxPool2d(2),
Conv2d(32,64,5,1,2),
MaxPool2d(2),
Flatten(),
Linear(in_features=1024,out_features=64),
Linear(64,10))
def forward(self,input):
output = self.model1(input)
return output
model = torch.load("tudui_9.pth") #传参为神经网络的相对地址,实例化
image = torch.reshape(image,(1,3,32,32)) #此步使得batch_size变为1,很重要,容易忽略!!!
model.eval()
with torch.no_grad():
output = model.forward(image)
print(output)
print(output.argmax(1)) #输出tensor最大的标签