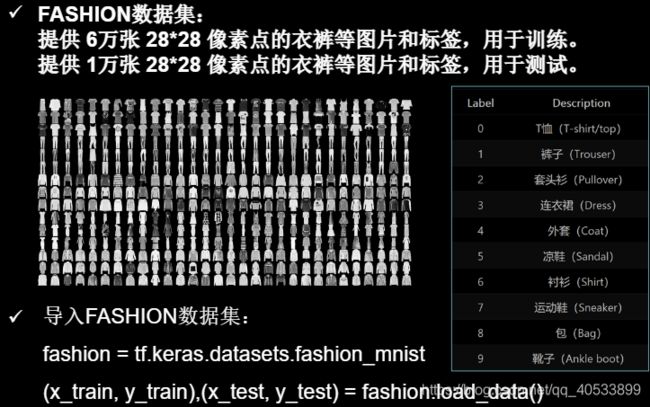
tensorflow学习笔记4(神经网络八股)


2;train,test 告知要喂入网络的训练集和测试集是什么
3:在Sequential中搭建神经网络结构,逐层描述每层网络,相当于走了一边前向传播
4:在compile配置训练方法,选择何种优化器(更新网络参数使用),何种损失函数,何种评测指标
5:在fit中执行训练过程,告知训练特征和标签,告知每个batch是多少,以及迭代多少次训练集
6:summary打印出网络的结构和参数统计

Flatten()将输入特征拉直,变为一维数组,Dense为全连接层

这里有个需要注意的地方 是 from_logit=False or True 的问题,如果神经网络输入经过了概率分布这里选择FALSE,不经过概率分布,直接输出这里选择True

不解释
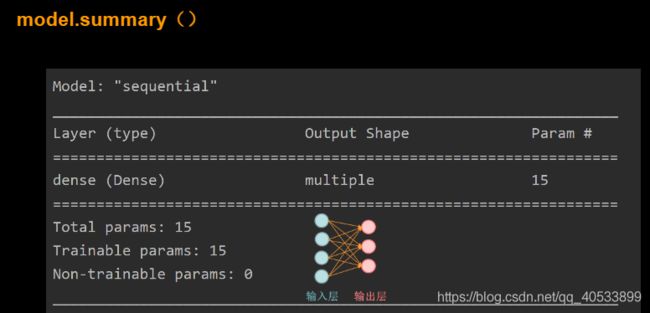
当时想为什么 Total params为15不应该为12嘛后来才想打是w1+b1总共15个可训练参数
import tensorflow as tf
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()
神经元个数这里,因为神经元个数是不计算输入层的所以,鸢尾花只剩下输出层三个神经元
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)这个数学上是个什么损失函数,我还不是特别清楚,所以暂时先不管,视频中说实践中常用这个函数为损失函数


import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
class IrisModel(Model):
def __init__(self):
super(IrisModel, self).__init__()
self.d1 = Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, x):
y = self.d1(x)
return y
model = IrisModel()
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary()

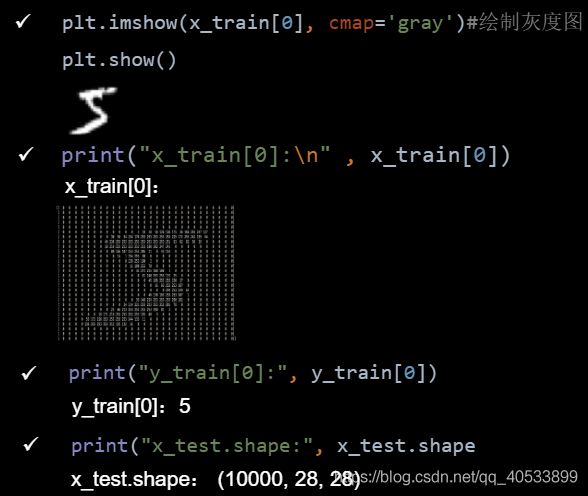
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
self.d1,self.d2 d1是第一层的神经元个数,d2是第二层的神经元个数