课程设计 天气预报数据可视化开发
-
问题需求分析
数据可视化开发是指将数据呈现为漂亮的统计图表,然后进一步发现数据中包含的规律以及隐藏的信息。数据可视化开发跟数据挖掘和大数据分析紧密相关,这些领域以及当下被热议的“深度学习”其最终的目标都是为了实现从过去的数据去对未来的状况进行分析和预测以及可视化展现。
天气数据是每个人基本都会关注的,具体到个人,主要是为了预防疾病,尤其是感冒,关注天气变化,加减衣服。而且很重要的一点是,如果要去外地,更要知道当地是什么天气情况,决定穿衣和携带的衣服。特别是突然下雨或者降温,加减衣服不当很容易生病。所以对其进行预测是很重要的
-
数据处理
2.1 数据获取
在“getweather.py”文件中
采用requests.get()方法,请求网页,如果成功访问,则得到的是网页的所有字符串文本
添加了文字的输出让我们能直观地看到访问是否成功
def getHTMLtext(url):
"""请求获得网页内容"""
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding # 是中文正常显示
print("访问成功")
return r.text
except:
print("访问失败")
return " "主函数部分则是存好需要的链接,获取到需要的html文件方便后续使用
def main():
"""主函数"""
print("武汉天气数据获取")
url1 = 'http://www.weather.com.cn/weather/101200101.shtml' # 7天天气中国天气网
url2 = 'http://www.weather.com.cn/weather15d/101200101.shtml' # 8-15天天气中国天气网
url_m1 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202201.html'
url_m2 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202202.html'
url_m3 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202203.html'
url_m4 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202204.html'
url_m5 = 'http://www.tianqihoubao.com/lishi/wuhan/month/202205.html' # 天气后报网2022年1~5月
html1 = getHTMLtext(url1)
data1, data1_7 = get_content(html1) # 获得1-7天和当天的数据
html2 = getHTMLtext(url2)
data8_14 = get_content2(html2) # 获得8-14天数据
data14 = data1_7 + data8_142.2 数据预处理
因为天气预报7天,8-15天,天气后报三个网页的格式不同,所以需要写三个处理的函数。
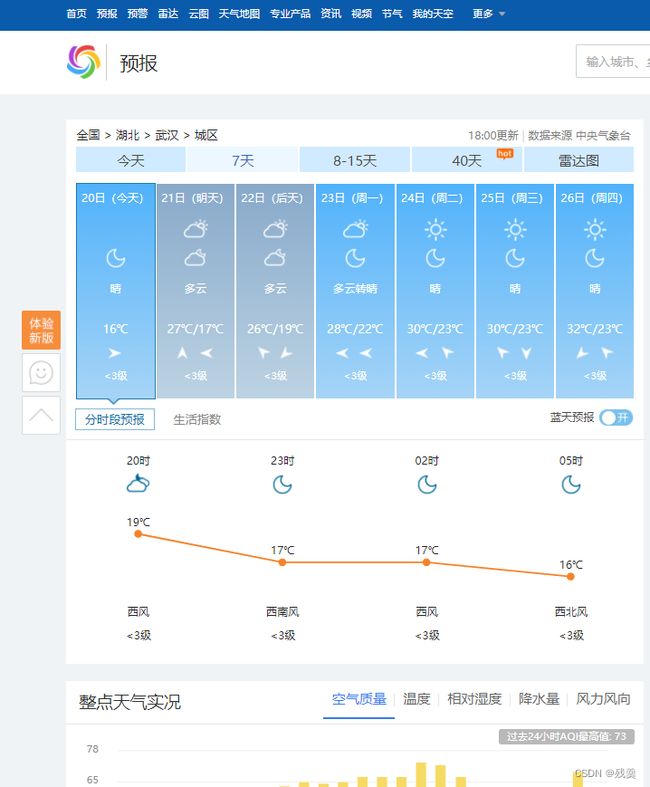
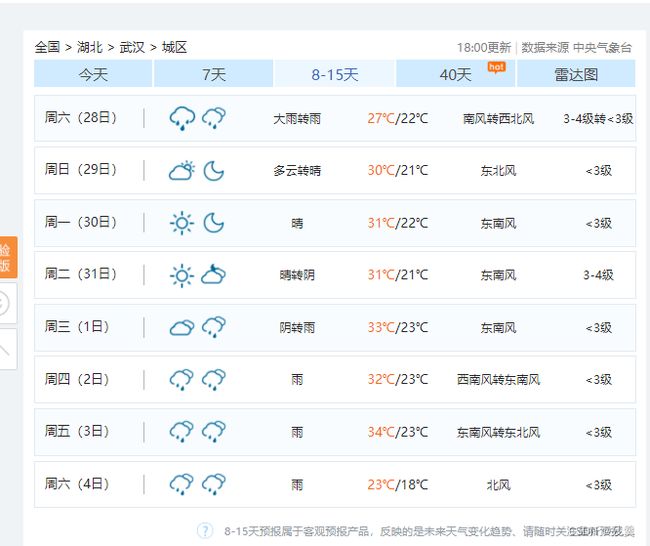
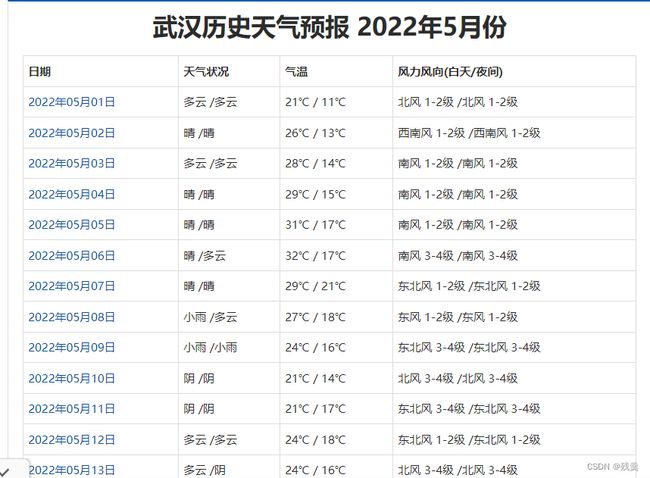
天气预报部分
先建立一个列表储存数据,创建BeautifulSoup对象
def get_content(html): # getHTMLtext返回的文件是此函数的参数
"""处理得到有用信息保存数据文件,1-7天和当天的数据"""
final = [] # 初始化一个列表保存数据class为left-div里面找所有的div
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body使用网页的开发者工具找到找到需要的数据所在位置
当天的数据在'left-div'中,存在data2中
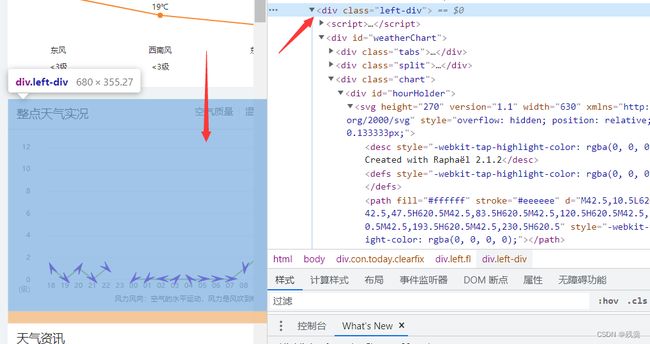
data2 = body.find_all('div', {'class': 'left-div'})首先爬取当天的数据
因为存放当天数据的div是第三个,所以取data2[2]中的文本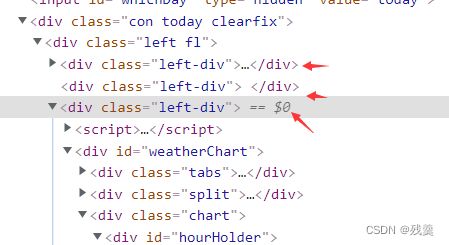
text = data2[2].find('script').string# 移除改var data=将其变为json数据
text = text[text.index('=') + 1:-2] # 移除改var data=将其变为json数据
jd = json.loads(text)
dayone = jd['od']['od2'] # 找到当天的数据
final_day = [] # 存放当天的数据将24小时的数据爬下来,存进final_day中(od是网页中的标签名)
count = 0
for i in dayone:
temp = []
if count <= 23:
temp.append(i['od21']) # 添加时间
temp.append(i['od22']) # 添加当前时刻温度
temp.append(i['od24']) # 添加当前时刻风力方向
temp.append(i['od25']) # 添加当前时刻风级
temp.append(i['od26']) # 添加当前时刻降水量
temp.append(i['od27']) # 添加当前时刻相对湿度
temp.append(i['od28']) # 添加当前时刻控制质量
# print(temp)
final_day.append(temp)
count = count + 1下面爬7天的数据
可以看到7天的数据在id为“7d”的div中,存在data中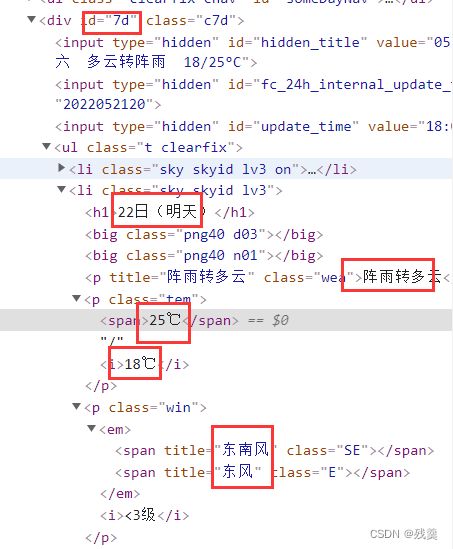
# 下面爬取7天的数据
ul = data.find('ul') # ul 里是在data里找到第一个的ul标签
li = ul.find_all('li') # li 里是在ul里找到所有的li标签并且存在ul和li标签里,所以使用一个循环来遍历每一天的数据,将每一项数据取出并进行预处理
具体在注释中
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 7 and i > 0:
# for i in range(7):
temp = [] # 临时存放每天的数据
date = day.find('h1').string # 得到日期
date = date[0:date.index('日') + 1] # 为从开头到“日”在date总的索引号->取出日期号
temp.append(date) # append:在列表末尾添加新的对象
inf = day.find_all('p') # 找出li下面的p标签,提取第一个p标签的值,即天气
temp.append(inf[0].string) # temp后面加上inf第一项(第一个p)中的文本
tem_low = inf[1].find('i').string # 找到最低气温
temp.append(tem_low[:-1]) # 不要最后一个字符'℃'
if inf[1].find('span') is None: # 天气预报可能没有最高气温
tem_high = None
else:
tem_high = inf[1].find('span').string # 找到最高气温
if tem_high[-1] == '℃': # 如果以'℃'结尾(以防没有'℃')
temp.append(tem_high[:-1])
else:
temp.append(tem_high)
wind = inf[2].find_all('span') # 找到风向
for j in wind: # 加上wind里面每一个title的值
temp.append(j['title'])
wind_scale = inf[2].find('i').string # 找到风级
index1 = wind_scale.index('级')
temp.append(int(wind_scale[index1 - 1:index1]))
final.append(temp)
i = i + 1
return final_day, final14天部分:也是类似,前面的ul,li标签获取相同
def get_content2(html):
"""处理得到有用信息保存数据文件,8-14天数据"""
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div', {'id': '15d'}) # 找到div标签且id = 15d
ul = data.find('ul') # 找到所有的ul标签
li = ul.find_all('li') # 找到左右的li标签遍历每一个li,根据每一个数据的特点取出相应的数据并存入final中返回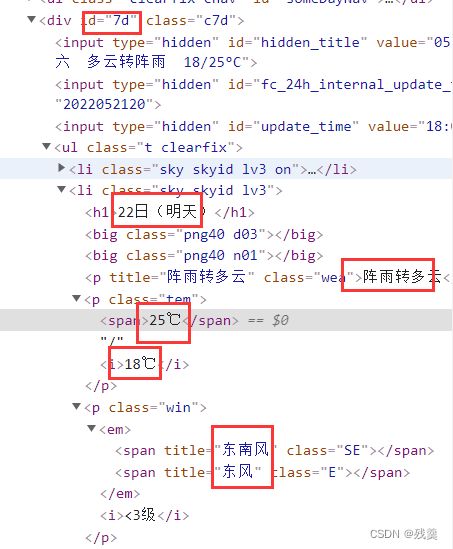
i = 0 # 控制爬取的天数
for day in li: # 遍历找到的每一个li
if i < 8:
temp = [] # 临时存放每天的数据
date = day.find('span', {'class': 'time'}).string # 得到日期
date = date[date.index('(') + 1:-1] # 取出日期号,保留一个“日”字
temp.append(date)
weather = day.find('span', {'class': 'wea'}).string # 找到天气
temp.append(weather)
tem = day.find('span', {'class': 'tem'}).text # 找到温度
temp.append(tem[tem.index('/') + 1:-1]) # 找到最低气温
temp.append(tem[:tem.index('/') - 1]) # 找到最高气温
wind = day.find('span', {'class': 'wind'}).string # 找到风向
if '转' in wind: # 如果有风向变化
temp.append(wind[:wind.index('转')])
temp.append(wind[wind.index('转') + 1:])
else: # 如果没有风向变化,前后风向一致
temp.append(wind)
temp.append(wind)
wind_scale = day.find('span', {'class': 'wind1'}).string # 找到风级
index1 = wind_scale.index('级')
temp.append(int(wind_scale[index1 - 1:index1]))
final.append(temp)
return final天气后报部分
在网页中找到需要的数据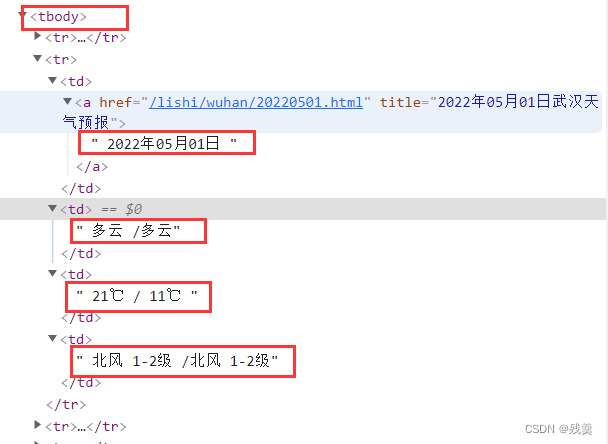
因为用前面的函数获取此网页的代码中文为乱码,所以此处换一种方式,形参是网址,在函数内部获取网页内容并处理
def get_content3(url):
"""处理得到有用信息保存数据文件,半年的数据"""
final = [] # 初始化一个列表保存数据
resp = requests.get(url)
html = resp.content.decode('gbk') # 为了中文不是乱码可以看到内容存在table中的tr里,第一个tr是表头,不是我们需要的数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('table')
tr = data.find_all('tr') # 找到所有的tr标签
tr = tr[1:] # 去掉第一行不需要的表头 使用循环处理每一天的数据
使用循环处理每一天的数据
for day in tr: # 遍历找到的每一天
temp = [] # 临时存放每天的数据
inf = day.find_all('td') # 全部都是用td装的日期内容存在a标签中
发现得到的日期数据有大量的空格空行,并且使用的是中文的年月日
使用.strip()去除空字符,并且将日期改为用“/”分隔
date = day.find('a').string.strip() # 得到日期
date1 = date[0:4] + '/' + date[5:7] + '/' + date[8:10]
temp.append(date1) # temp后面加上日期并去除空字符效果如图: ![]()
天气数据是前后有大量空格且中间也有空格,还需要拆掉“/”
将温度的0,2项取出来并去掉末尾符号
tianqi = inf[1].string.split() # 取出天气部分的文本再拆分,顺便去掉空字符
temp.append(tianqi[0]) # 天气第一部分
temp.append(tianqi[1][1:]) # 天气第二部分,去掉/
win = inf[3].string.split() # 风向部分
temp.append(win[0]) # 风向1
temp.append(win[2][1:]) # 风向1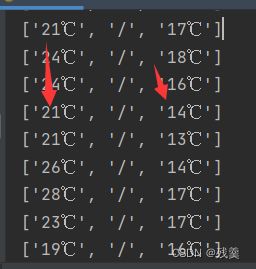
风向:
输出后如下图
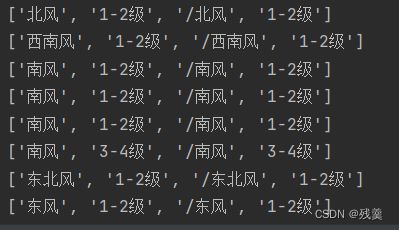
把风级信息就不要了,把第一项和第三项取出,第三项要去掉开头的“/”
win = inf[3].string.split() # 风向部分
temp.append(win[0]) # 风向1
temp.append(win[2][1:]) # 风向1
final.append(temp)
return final得到在天气后报中所需要的天气信息
将数据加到最终(final)中返回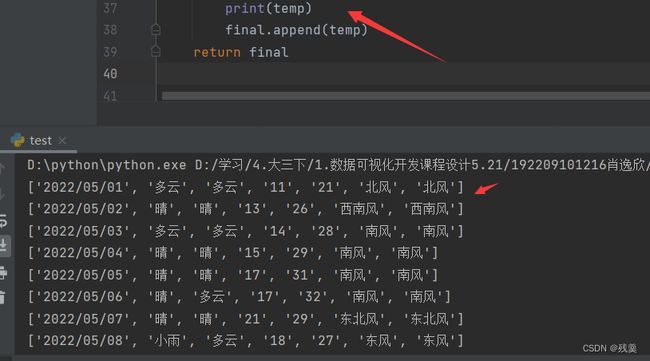
保存为csv文件
因为有三种不同的数据,所以保存时分成三种情况,用“day”参数区分
分别加入表头,存入数据
def write_to_csv(file_name, data, day): # 文件名,写入的数据,是哪种数据
"""保存为csv文件"""
with open(file_name, 'a', errors='ignore', newline='') as f: # 起名为f
if day == 14: # 周数据
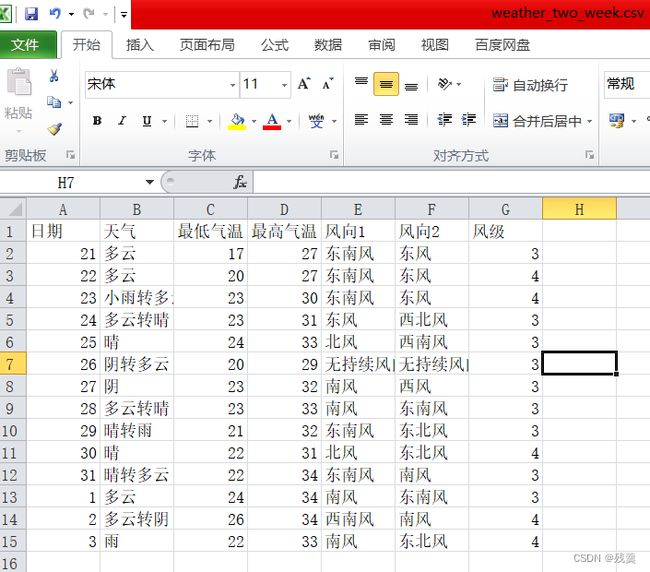
header = ['日期', '天气', '最低气温', '最高气温', '风向1', '风向2', '风级']
elif day == 30: # 月数据
header = ['日期', '天气1', '天气2', '最低气温', '最高气温', '风向1', '风向2']
else: # 天数据
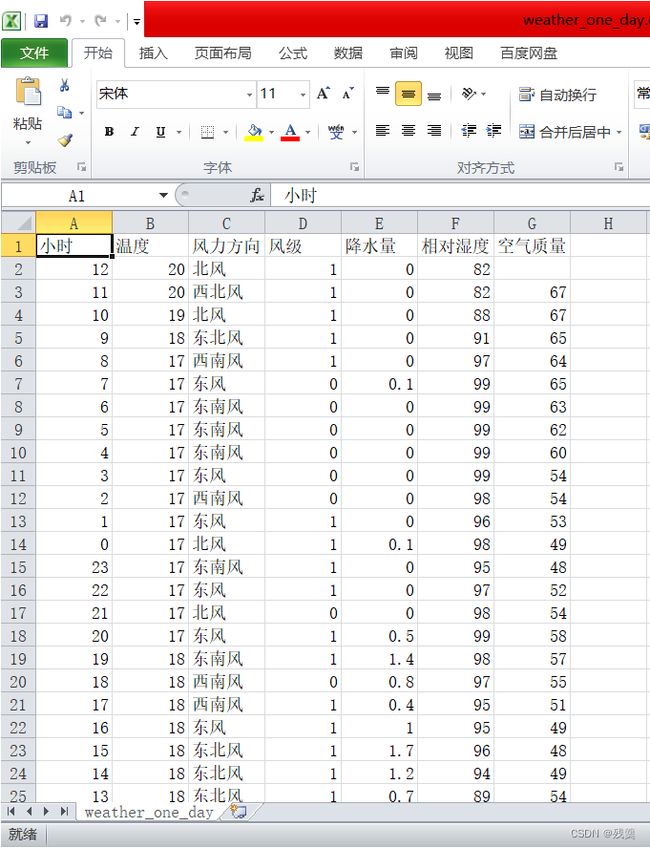
header = ['小时', '温度', '风力方向', '风级', '降水量', '相对湿度', '空气质量']
f_csv = csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(data)主函数中用此函数将三个文件保存
write_to_csv('weather_two_week.csv', data14, 14) # 保存为csv文件
write_to_csv('weather_one_day.csv', data1, 1)
write_to_csv('weather_half_year.csv', data_half_year, 30)成功写成csv格式 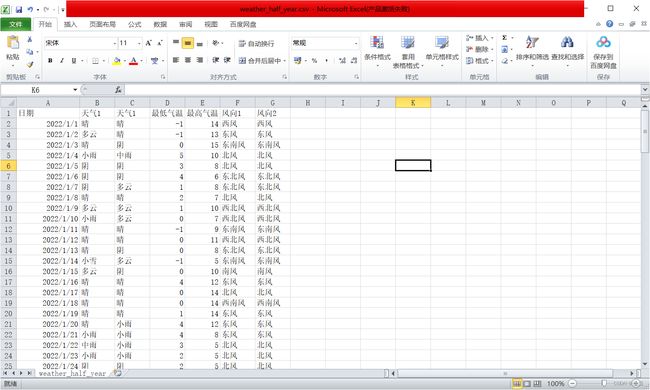
2.3数据清洗
在“show.py”文件中
检查是否有空值
# 数据清洗
df = pd.read_csv("weather_half_year.csv", encoding="ANSI")
print(df.isnull().sum())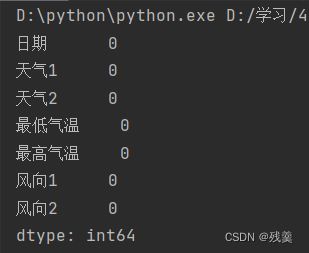
weather_one_day

weather_two_week
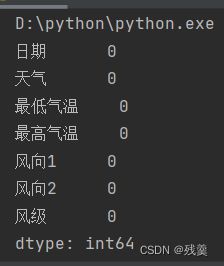
发现有一个空气质量为空,因为空气质量随时间变化而变化,考虑到第一个和最后一个的情况,所以选择用前一个和后一个非缺失值去填充该缺失值
加上inplace = True才能是源数据发生改变并保存
# 数据清洗
df = pd.read_csv("weather_one_day.csv", encoding="ANSI")
# print(df)
df.fillna(method='ffill', inplace=True) # 加上inplace = True才能是源数据发上改变并保存
df.fillna(method='bfill', inplace=True)
# print(df)
print(df.isnull().sum())前:
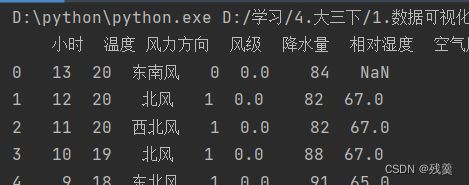
后:
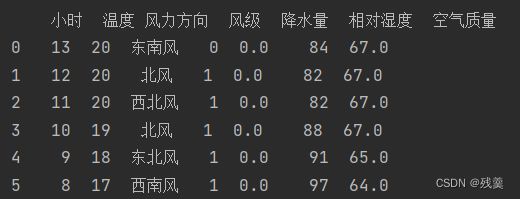
-
可视化展示
为解决负号和中文显示问题,添加以下两条代码
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题上半年最高温和最低温的变化曲线
将需要的包导入
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import math首先将需要的数据使用.iloc提取出来
"""绘制半年的最高最低温度曲线图"""
tem_time = hy.iloc[:, 0] # 日期
tem_min = hy.iloc[:, 3] # 最低温度
tem_max = hy.iloc[:, 4] # 最高温度因为半年的数据较多,所以改变窗口的大小
达到如图,x轴重叠在一起无法看清,用红色线条代表最高温,蓝色线条代表最低温,并让x轴刻度文字倾斜
plt.figure(figsize=(10, 5.5)) # 改变窗口大小
plt.plot(tem_time, tem_min, 'b') # 显示图像
plt.plot(tem_time, tem_max, 'r') # 显示图像
plt.xticks(rotation=15) # 横坐标倾斜可以看到因为x轴刻度过多导致重叠无法看清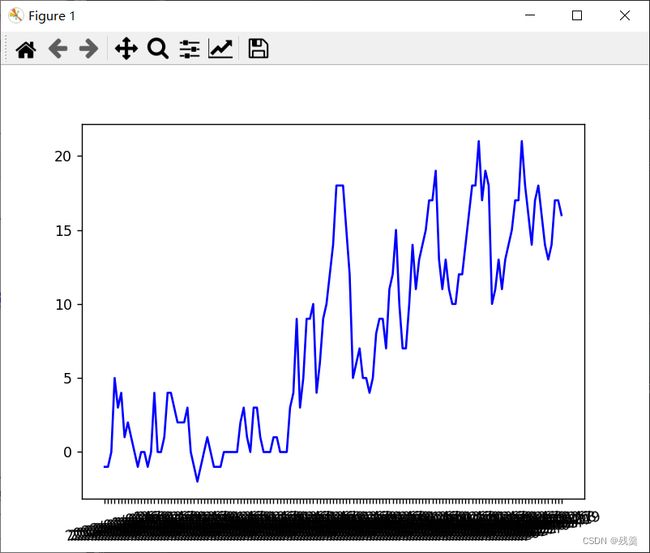
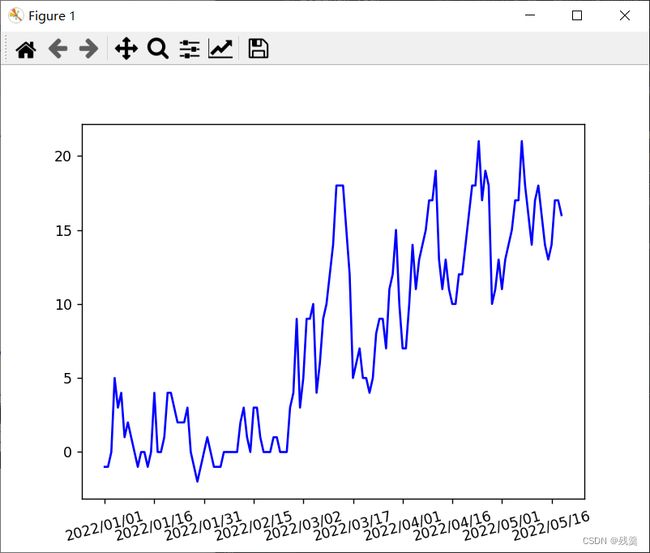
所以使用xticks函数让x坐标轴显示的步长为15(每15个显示一个)
plt.xticks(tem_time[::15]) # 横坐标只显示部分可以看到看的更清楚了
添加上标题和标签
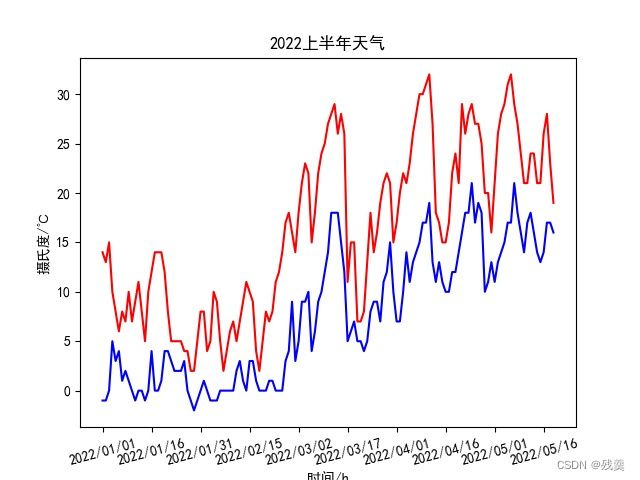
plt.title("2022上半年天气") # 标题
plt.xlabel('日期') # x轴标签
plt.ylabel('摄氏度/℃') # y轴标签保存图片时发现图片打开为空白,查资料后发现是plt.show()在savefig前面导致
plt.xticks(tem_time[::15]) # 横坐标只显示部分
plt.xticks(rotation=15) # 横坐标倾斜
plt.show()
plt.savefig('2022半年气温.jpg') # 保存图片
#会导致保存空白图片
去掉show或将show之后后运行,可以看到文件正常保存
再加上最高温度的图像
plt.figure(figsize=(10, 5.5)) # 改变窗口大小
plt.plot(tem_time, tem_min, 'b') # 显示图像
plt.plot(tem_time, tem_max, 'r') # 显示图像
plt.title("2022上半年天气") # 标题
plt.xlabel('日期') # x轴标签
plt.ylabel('摄氏度/℃') # y轴标签
plt.xticks(tem_time[::15]) # 横坐标只显示部分
plt.xticks(rotation=15) # 横坐标倾斜
# plt.savefig('2022半年气温.jpg') # 保存图片
# plt.show() 结果如图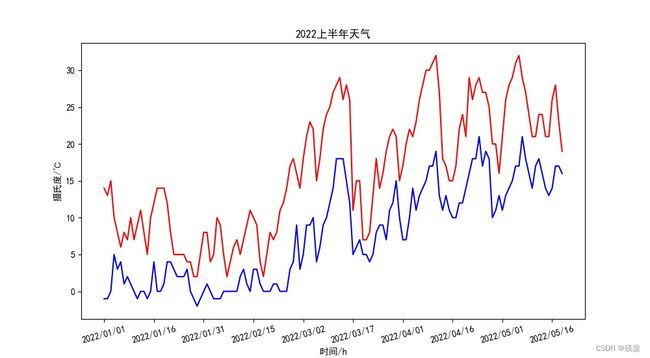
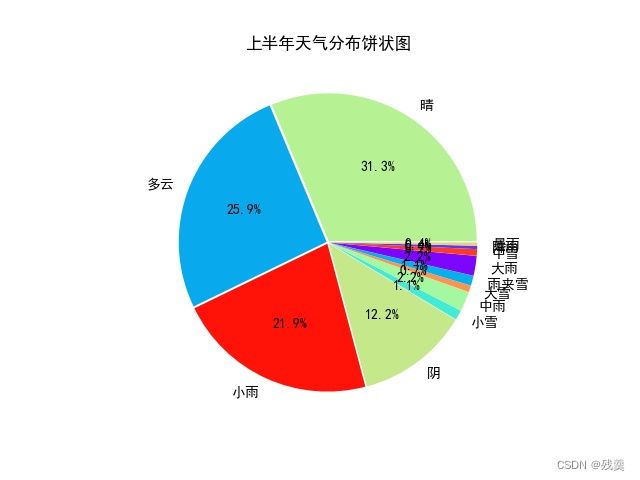
上半年天气分布饼状图
因为每天的天气有两部分,所以将所有的天气合起来,计算统计每一种的数量
"""绘制半年的天气饼图"""
weather = list(hy['天气1'].append(hy['天气2'])) # 把两部分天气合起来
dic_wea = {}
for w in weather:
if w in dic_wea.keys():
dic_wea[w] += 1
else:
dic_wea[w] = 1使用matplotlib.cm得到对应数量的随机色彩映射
explode = [0.01] * len(dic_wea.keys())
color = plt.cm.rainbow(np.random.rand(len(dic_wea.keys()))) # 随机颜色
plt.pie(dic_wea.values(), explode=explode, labels=dic_wea.keys(), autopct='%1.1f%%', colors=color)
plt.title('上半年天气分布饼状图')
plt.savefig('2022上半年饼状图.jpg') # 保存图片结果如图
不知道怎么解决文字重叠问题,知道的可以教教我)
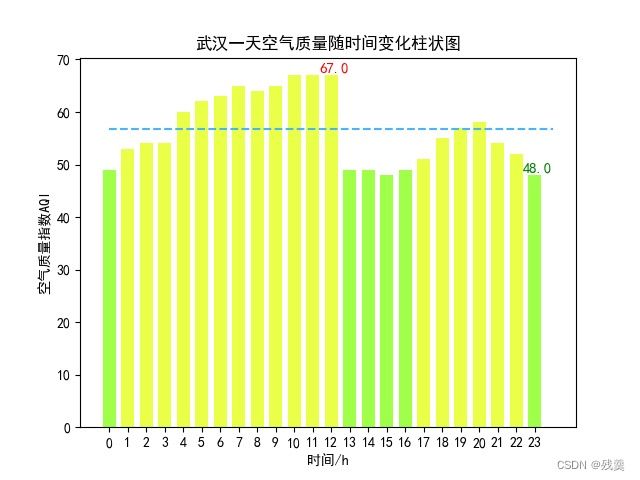
一天内空气质量随时间变化柱状图
读入数据
x,y轴分别为小时和空气质量
data = pd.read_csv('weather_one_day.csv', encoding='gb2312') # 读入数据
"""空气质量柱状图绘制"""
hour = list(data['小时'])
air = list(data['空气质量'])求出最高,最低,平均空气质量
for i in range(0, 24):
if math.isnan(air[i]):
air[i] = air[i - 1]
air_ave = sum(air) / 24 # 求平均空气质量
air_max = max(air)
air_max_hour = hour[air.index(air_max)] # 求最高空气质量
air_min = min(air)
air_min_hour = hour[air.index(air_min)] # 求最低空气质量
x = []
y = []设置不同空气质量的分级,将不同等级的柱状图的颜色设置为从绿到红的渐变,让我们可以在图中更直观的感觉到空气质量整体情况
for i in range(0, 24): # 空气质量分级
if y[i] <= 50:
plt.bar(x[i], y[i], color='#a0ff48', width=0.7) # 1等级
elif y[i] <= 100:
plt.bar(x[i], y[i], color='#EAFF48', width=0.7) # 2等级
elif y[i] <= 150:
plt.bar(x[i], y[i], color='#E0CD7F', width=0.7) # 3等级
elif y[i] <= 200:
plt.bar(x[i], y[i], color='#E0AC69', width=0.7) # 4等级
elif y[i] <= 300:
plt.bar(x[i], y[i], color='#E07B4B', width=0.7) # 5等级
elif y[i] > 300:
plt.bar(x[i], y[i], color='#E05140', width=0.7) # 6等级画出平均空气质量虚线
用红色表示出最高温,绿色表示出最低温
plt.plot([0, 24], [air_ave, air_ave], c='#48b4ff', linestyle='--') # 画出平均空气质量虚线
plt.text(air_max_hour + 0.15, air_max + 0.15, str(air_max), c='red', ha='center', va='bottom',
fontsize=10.5) # 标出最高空气质量
plt.text(air_min_hour + 0.15, air_min + 0.15, str(air_min), c='green', ha='center', va='bottom',
fontsize=10.5) # 标出最低空气质量设置标题和标签,保存图片
plt.xticks(x)
plt.title('武汉一天空气质量随时间变化柱状图')
plt.xlabel('时间/h')
plt.ylabel('空气质量指数AQI')
# plt.show()
plt.savefig('武汉空气质量柱状图.jpg') # 保存图片结果如图:
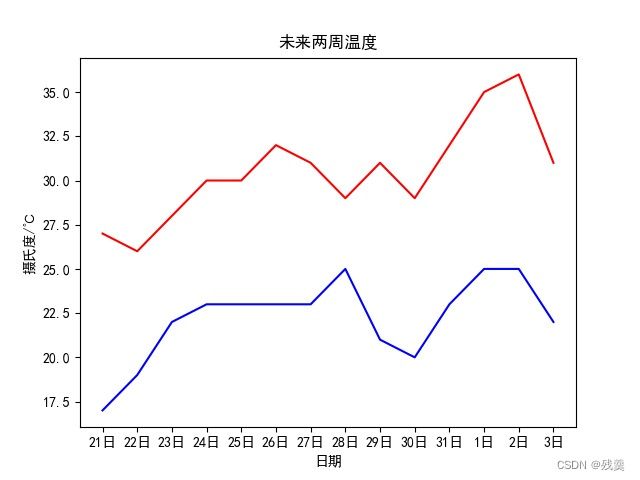
未来两周的气温数据绘制
将未来两周的数据读入,取出需要的日期,最高温和最低温
"""未来两周的气温数据绘制"""
data14 = pd.read_csv('weather_two_week.csv', encoding='gb2312') # 未来两周的数据
tem_time = data14.iloc[:, 0] # 日期
tem_min = data14.iloc[:, 2] # 最低温度
tem_max = data14.iloc[:, 3] # 最高温度
plt.plot(tem_time, tem_min, 'b') # 显示图像
plt.plot(tem_time, tem_max, 'r') # 显示图像
plt.title("未来两周温度") # 标题
plt.xlabel('日期') # x轴标签
plt.ylabel('摄氏度/℃') # y轴标签
plt.xticks(tem_time)
plt.savefig('未来两周温度.jpg') # 保存图片
# plt.show()结果如图:
-
模型构建
在“train.py”文件中
4.1 数据获取
本次课设中我选择使用岭回归算法对温度变化进行预测
岭回归,又称脊回归、吉洪诺夫正则化(Tikhonov regularization),是对不适定问题(ill-posed problem)进行回归分析时最经常使用的一种正则化方法,是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
最开始我选择将日期作为特征值,温度作为标签值进行学习和预测,但结果为一条直线,显然在此问题中并是一个好的模型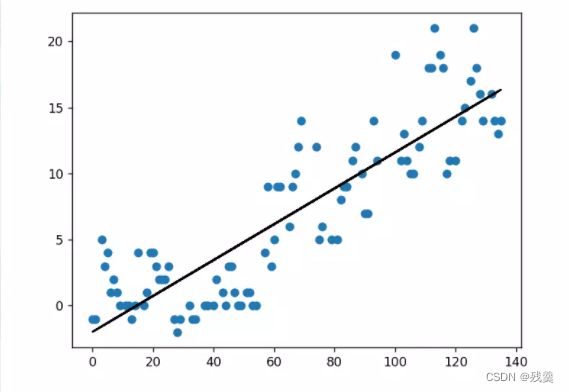
随后我查询天气温度预测的相关资料,最终选择将一个温度的前N天作为其标签值,使用岭回归算法进行学习和预测
此处以最低温度数据为例
先处理数据,此处将N设为7,分别放入两个列表中
def read_data(df, N, column): # 数据,特征数目,列名
"""天气数据 处理1"""
data = list(df[column]) # 提取数据内容
x = []
y = []
for i in range(N, len(data)):
s = []
for j in range(i - N, i):
s.append(data[j])
x.append(s)
y.append(data[i])
return np.array(x), np.array(y)运行的效果:
df = pd.read_csv('weather_half_year.csv', encoding='gb2312') # 读取数据
N = 7 # 特征数目
lX, lY = read_data(df, N, '最低气温') # 处理1后的
print(lx)lx
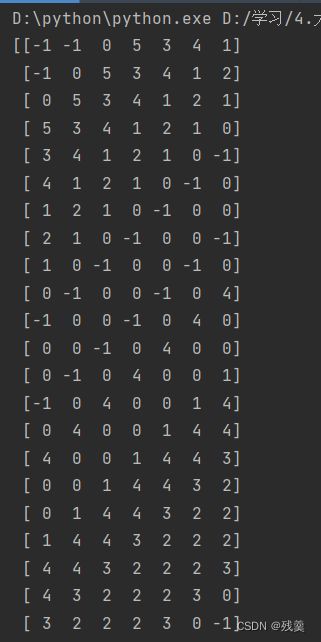
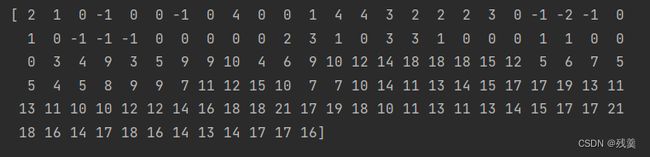
ly
再分割训练集和测试集,此处设置20%的部分为测试集
进行岭回归:
x_train, x_test, y_train, y_test = train_test_split(lX, lY, test_size=0.2) # 分割训练集和测试集
"""岭回归"""
class RidgeRegression:
def __init__(self):
'''初始化线性回归模型'''
self.theta = None
# 通过代码实现θ的求解
def fit(self, xMat, yMat, lam=0.2):
"""
xMat(ndarray): 特征值
yMat(ndarray): 标签值
lam: 常量λ
"""
xMat = np.mat(xMat) # 将数据转化为矩阵
yMat = np.mat(yMat).T # 将数据转化为矩阵,并进行转置
xTx = xMat.T * xMat # 矩阵xMat转置后相乘
denom = xTx + np.eye(np.shape(xMat)[1]) * lam # 公式XTX+λI的表示代码
# 判断denom是否是奇异的
if np.linalg.det(denom) == 0.0:
print("这个矩阵是奇异的,不可求逆")
return
self.theta = denom.I * (xMat.T * yMat) # 根据最优解求解公式求θ值
def predict(self, test_data):
'''
test_data(ndarray):测试样本
'''
test_data = np.mat(test_data) # 将数据转化为矩阵
y_predict = test_data * self.theta # 通过得到的θ值,对数据进行预测
return y_predict建立模型并训练
rr = RidgeRegression()
rr.fit(x_train, y_train)
yp = rr.predict(lX)为了便于观察模型效果,将使用原始数据(lX)进行预测得到yp
接下来将两个结果进行可视化
4.2 可视化展示
因为是前7天作为特征值,结果中没有,所以将日期与温度都从第八项开始取
因为观察到两条线有一定的错位,所以将真实值最后一位不取,预测结果第一位不取来对齐
将真实值与预测值放在一起便于观察预测效果
将真实线条设置为绿色,预测线条设置为蓝色虚线
y_real = df.iloc[7:-1, 3] # 真实温度数据
x_real = df.iloc[7:-1, 0] # 日期部分
plt.plot(x_real, y_real, 'g', label='真实')
plt.plot(x_real, yp[1:], 'b--', label='预测')使用figsize设置窗口大小
设置标题和标签
plt.figure(figsize=(10, 5.5)) # 改变窗口大小
plt.title("武汉半年来温度预测与实际对比图") # 标题
plt.xlabel('日期') # x轴标签
plt.ylabel('摄氏度/℃') # y轴标签因为日期会产生重叠,所以设置倾斜为15
plt.xticks(rotation=15) # 横坐标倾斜
plt.xticks(x_real[::15]) # 横坐标只显示部分 #要在线条显示的下面,不然报错一定要注意它们的相对位置!!!不然会出错
y_real = df.iloc[7:-1, 3] # 真实温度数据
x_real = df.iloc[7:-1, 0] # 日期部分
plt.figure(figsize=(10, 5.5)) # 改变窗口大小
plt.plot(x_real, y_real, 'g', label='真实')
plt.plot(x_real, yp[1:], 'b--', label='预测')
plt.title("武汉半年来温度预测与实际对比图") # 标题
plt.xlabel('日期') # x轴标签
plt.ylabel('摄氏度/℃') # y轴标签
plt.legend()
plt.xticks(rotation=15) # 横坐标倾斜
plt.xticks(x_real[::15]) # 横坐标只显示部分 #要在线条显示的下面,不然报错
plt.savefig('武汉半年来温度预测与实际对比图.jpg') # 保存图片
plt.show()结果如图:
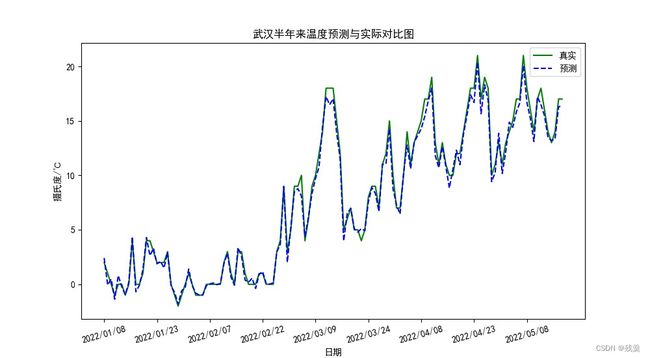
可以看出预测效果还是很不错的
-
前景预测
将得到的未来14天的气温用作预测
为了从为来第一天就能开始预测,将历史最后7天和未来14天的数据拼在一起
处理成前7天为特征值,后一天为标签值的状态,使用特征值进行预测,得到结果
"""预测未来14天温度"""
# 处理特征值,把历史最后7天和未来14天的数据拼在一起,为了从为来第一天就能开始预测
data14 = pd.read_csv('weather_two_week.csv', encoding='gb2312')
df14 = data14.iloc[:, [0, 2]]
df7 = df.iloc[-7:, [0, 3]]
df147 = pd.concat([df7, df14], ignore_index=True) # 后面那个接在前面
lX1, lY1 = read_data(df147, N, '最低气温') # 处理1
yp147 = rr.predict(lX1) # 得到预测结果将结果可视化:
# 可视化结果查看效果
x14 = data14.iloc[:-1, 0]
y14 = data14.iloc[:-1, 2] # 未来14天天气预报数值
plt.plot(x14, y14, 'g', label='真实')
plt.plot(x14, yp147[1:], 'b--', label='预测')
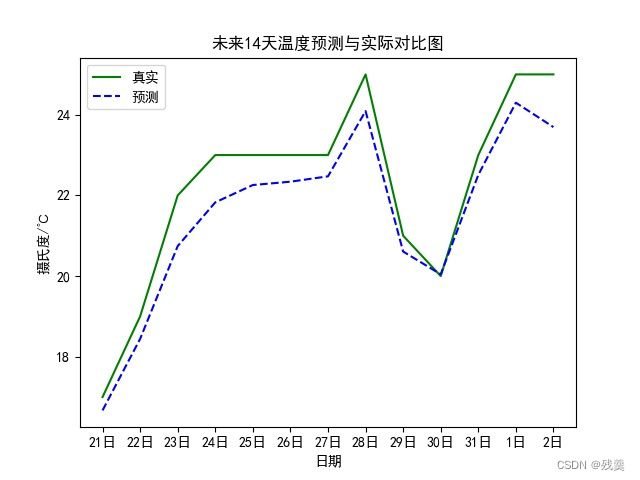
plt.title("未来14天温度预测与实际对比图") # 标题
plt.xlabel('日期') # x轴标签
plt.ylabel('摄氏度/℃') # y轴标签
plt.legend()
plt.savefig('未来14天温度预测与实际对比图.jpg') # 保存图片
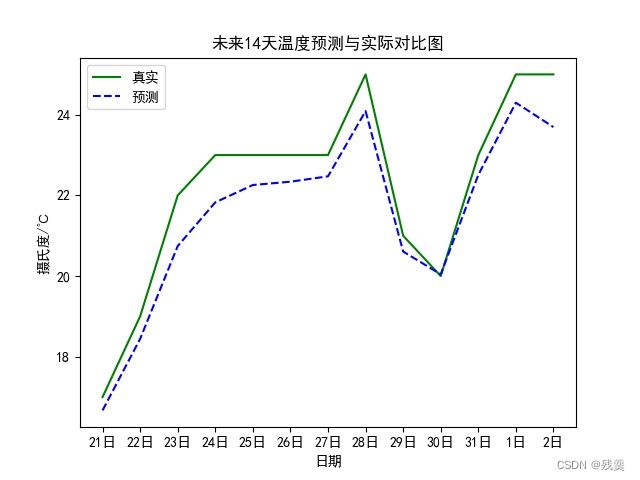
# plt.show()结果如图:
-
结果分析
从预测图中可以看出,该模型预测效果大体上差异不大,但仍然有提升的空间。
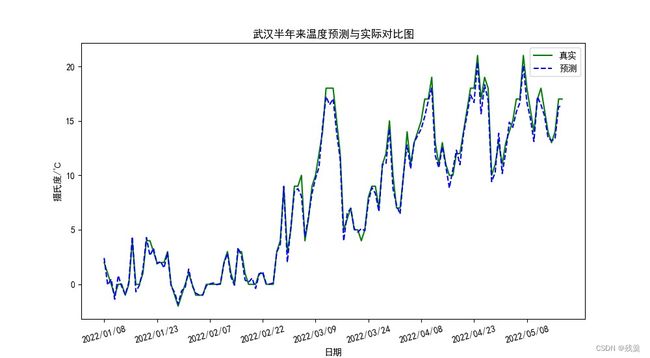
从上半年最高最低温度的曲线图中可以很直观的看出2022年上半年在一月底达到了最低温,之后温度整体上升
在三月中旬猛地升温,再温度猛降,至今已有四波大的起伏
从上半年天气分布饼图中可以看出最多的是晴天,次之的是多云,小雨
从武汉一天空气质量随时间变化柱状图可以看出,武汉的空气质量整体不算太好,但也不是过于恶劣
下午1点~4点和凌晨空气质量较好
