nlp 中文文本纠错_基于自然语言处理的病历文本自动纠错技术
一. 背景和意义
电子病历文本是医生对病人病情的文字性描述,一般是医生通过手工输入电子病历系统的。难免存在错字、漏字、错标点等问题。据初步统计,电子病历中的错误率大约为每百万字符15-50处。这些错误对后期的解读和数据分析埋下隐患。

在nlp领域中文本纠错由于没有特别成熟的方法,而且用到的知识点比较繁琐,真正的应用到工业界还要考虑实际成本和效率。常见纠错内容如下所示:
- 谐音错别字:行走瓶稳----行走平稳?- 形近错别字:氨基已酸 ----氨基己酸- 多字:无为畏寒 ----无畏寒- 字词顺序错误:硫酸氯氢吡格雷 ---- 硫酸氢氯吡格雷- 缺字:右扁肿大 ----右扁桃体肿大- 顺序:予阿静滴奇 ---- 予阿奇霉素静滴
二. 文本纠错定义
1.定义
文本纠错是一个重要又不重要的领域,不纠错,通常的NLP下游任务也能进行,只是会影响效果、体验,例如word2vec之类大样本训练任务;有时候用户体验直接影响收入:电商搜索。输入法,校对等。
纠错相对更偏系统工程,经常是其它nlp任务的上游,对响应速度要求较高。与分词一起,具体谁在前不一定,有分词纠错同时进行的。英文NER可以在纠错之前,中文NER一般在纠错之后。中文较少因为纠错让实体词变为非实体词
2.文本纠错分类
英文纠错
拼音纠错
中文纠错
三. 文本纠错解决方案
1.概要:
中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
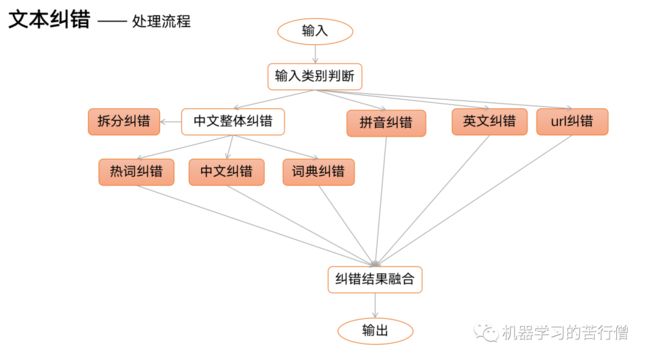
文本纠错流程
2.具体流程:
通常的流程是先断字,每种断法都作为下一步的候选
基于某种断字方法
进行ed=1 or 2的候选扩充,如果增删改的字符让新字符串不构成拼音则抛弃,声母只能代替声母,韵母只能代替韵母,也可使用bk-tree搜索。包括混淆音、方言等问题,比如按照拼音编辑距离:
in->ing/an->ang/z->zh/l->n
unigram/bigram
使用的是断字之后字词本身的uni/bigram
方言混淆音的召回不降权
3.建模方法:
在中文文本纠错的文章,但是从整体来看,大多数都分为2个阶段来建模,当然最新的文本纠错也开始使用端到端方法。但大多数的文本纠错还是大致分为两个步骤。
1)创建一个修改候选实体。此阶段的主要目的是使用一种或多种策略(特定规则或模型)来创建用于修改原始语句的候选对象。每位候选对象都是替换一个或多个可能有错误的汉字的结果。..这个阶段保证了整个模型的召回率和模型的上限。
2)候选实体评分。本阶段的主要目的是基于上一阶段,结合特定的评分功能(距离,LM等编辑)或分类器以及局部和全局特征。执行排序任务,最后进行排序。最佳修复候选者是修复的结果。
四. 一个开源的baseline文本纠错环境搭建
本系统基于 pycorrector 库,pycorrector 是 基于 PyTorch 深度学习框架的序列建模工具包,它支持 业务规则纠错和深度模型,支持混合精度训练,支持分布式多 GPU。
1.桌面工作站服务器的系统环境如表1所示。
表 1桌面工作站系统环境
| 属性名 | 属性值 |
| 操作系统 | Ubuntu 16.04.5 LTS |
| Python 发行版 | Anaconda3-4.4.0-Linux-x86_64 |
| 深度学习框架 | PyTorch 0.4.1 |
| pycorrector 库 | PyTorch 0.4.1 |
| CUDA | CUDA 9.0(cuDNN v7.3.1) |
2.安装
1)代码安装
git clone https://github.com/shibing624/pycorrector.gitcd pycorrectorpython setup.py install2)依赖包安装
kenlm安装:pip install https://github.com/kpu/kenlm/archive/master.zip其他库包安装pip install -r requirements.txt3.使用
import pycorrectorcorrected_sent, detail = pycorrector.correct('少先队员因该为老人让坐')print(corrected_sent, detail)输出内容:少先队员应该为老人让座 [[('因该', '应该', 4, 6)], [('坐', '座', 10, 11)]]五.一个演示视频
下面是结合一个前台页面的电子病历纠错演示视频。
六.最新的sota模型
《Spelling Error Correction with Soft-Masked BERT 》
2020年ACL的一篇文章,可以说是改进了原有BERT直接获取每个字的候选集的方法,将纠错任务拆分为两部分解决,Detection Network 和 Correction Network,其中Detection Network是基于Bi-GRU构建的一个二分类模型,用于预测文本出错的概率。Correction Network则是利用bert生成候选集合并打分。
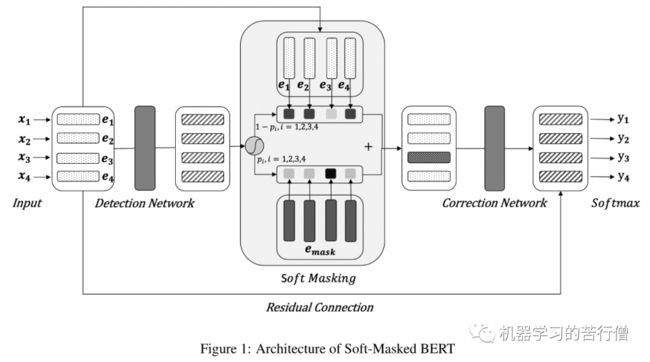
检错网络:
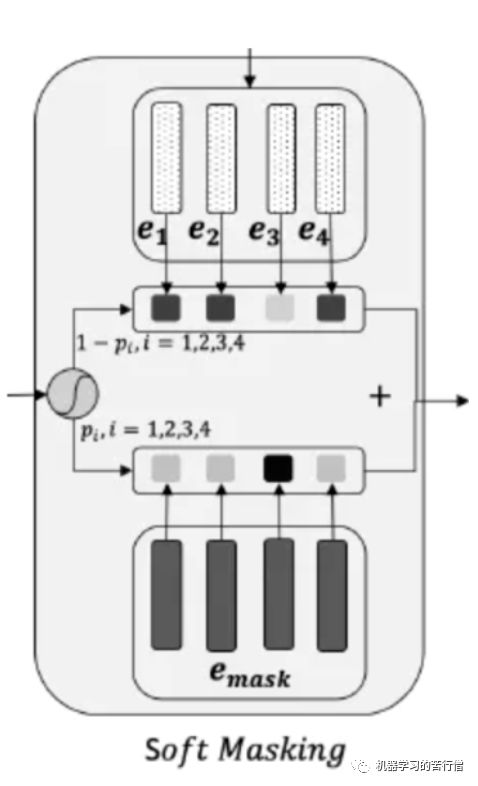
Dectection Network在后续处理时有一个小细节,二分类获得的概率之后,根据概率对bert 的char embedding和mask embedding加权求和传递给Correction Network。Soft Masking 部分,将每个位置的特征以 p(i) 的概率乘上 masking 字符的特征,以(1-p(i))的概率乘上原始的输入特征,最后两部分相加作为每一个字符的特征,输入到纠正网络中。
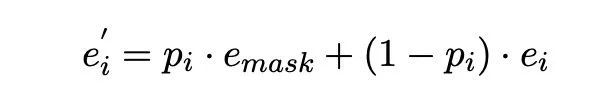
纠错网络:
Correction Network则是一个基于BERT的序列多分类标记模型。检测网络输出的特征作为BERT 12层Transformer模块的输入,最后一层的输出+Input部分的Embedding特征(残差连接)作为每个字符最终的特征表示。整个网络的训练端到端进行,损失函数由检测网络和纠正网络加权构成。

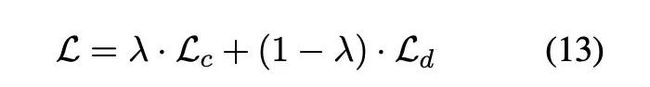
实验结果
作者在“SIGHAN”和“NEWs Title”两份数据集上做了对比实验。其中“SIGHAN”是2013年开源的中文文本纠错数据集,规模在1000条左右。“NEWs Title”是从今日头条新闻标题中自动构建的纠错数据集(根据文章开头展示的相似字形、相似拼音字典),有500万条语料。

参考文献
[1] pycorrector https://github.com/shibing624/pycorrector
[2] Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013
[3] Overview of SIGHAN 2014 Bake-off for Chinese Spelling Check
[4] Introduction to SIGHAN 2015 Bake-off for Chinese Spelling Check
[5] https://github.com/shibing624/pycorrector/blob/master/pycorrector/corrector.py
[6] An Improved Graph Model for Chinese Spell Checking
[7] A Hybrid Model for Chinese Spelling Check
[8] HANSpeller++: A Unified Framework for Chinese Spelling Correction
[9] FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm
[10] Spelling Error Correction with Soft-Masked BERT
[11] https://zhuanlan.zhihu.com/p/138551957
[12] https://zhuanlan.zhihu.com/p/80781295