uci心脏病决策树分析
目录
1.数据来源
2.数据说明
3.代码实现
4.结果展示
5.分析
1.数据来源
Index of /ml/machine-learning-databases/heart-disease
里面的processed.cleveland.data点击下载即可
2.数据说明
| 字段名 |
含义 |
描述 |
| age |
年龄 |
对象的年龄,数字表示 |
| sex |
性别 |
对象的性别,1男性 0女性 |
| cp |
胸部疼痛类型 |
痛感程度1,2,3,4 |
| trestbps |
血压 |
血压数值 |
| chol |
胆固醇 |
胆固醇数值 |
| fbs |
空腹血糖 |
血糖含量 |
| restecg |
心电图结果 |
是否有T波,0,1 |
| thalach |
最大心跳数 |
最大心跳数 |
| exang |
运动时是否心绞痛 |
是否有心绞痛,1 是,0 否 |
| oldpeak |
运动相对于休息的ST depression |
st段压数值 |
| slop |
心电图ST segment的倾斜度 |
ST segment的slope,程度分为3 down、2 flat、1 up |
| ca |
透视检查看到的血管数 |
透视检查看到的血管数(0-3) |
| thal |
缺陷种类 |
并发种类,0-6 |
| status |
是否患病 |
是否患病 0到4患心脏病的程度 |
3.代码实现
import numpy as np
import pandas as pd
import pydotplus
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import tree
import graphviz #此处没有用到
#(1)读取数据
names=['年龄','性别','类型','静态血压','血清胆固醇','空腹血糖','静息心电图','最大心率','运动心绞痛','ST压低','ST段峰值斜率','主要血管数','thal','心脏病的诊断']
data=pd.read_csv("processed.cleveland.csv",sep=",",header=None,names=names)
print(data.info())#查看数据是否有缺省
#(2)对数据进行处理
#删除缺失值的行
data=data.replace(to_replace="?",value=np.nan) #将?转换为null
data.dropna(inplace=True)#将空值所在的行删除inplace=True改变原表
# print(data)
# print(data.sample(10))#随机查看10条数据
#(3)划分训练集和测试集7:3
target=data['心脏病的诊断']#------Y 因变量
print(target)
data=data.drop('心脏病的诊断',1)#------x 自变量
print(data)
#训练集和测试集的划分为7:3 将70%拿去训练模型,剩余30%的数据代入训练的模型中进行测试
X_train, X_test, Y_train, Y_test=train_test_split(data,target,test_size=0.3,random_state = 0)
#clf=DecisionTreeClassifier(criterion = 'entropy',random_state = 0) #载入决策树分类模型 #基于信息熵的决策树
#固定random_state后,每次构建的模型是相同的、生成的数据集是相同的、每次的拆分结果也是相同的,也就是随机种子相同
#(4)使用训练集训练一个决策树分类器
clf=DecisionTreeClassifier(criterion='gini',max_depth=4,max_leaf_nodes=10,min_samples_leaf=9,)#基于gini的决策树
#max_depth=4决策树最大深度
#max_leaf_nodes最大叶子结点
#min_samples_leaf:叶子节点(即分类)最少样本数。
#(5)决策树拟合得到模型
clf=clf.fit(X_train,Y_train)
y_pred = clf.predict(X_test)
print(y_pred)
#(6)分别使用训练集和测试集计算决策树分类器的分类准确率
score=clf.score(X_test,Y_test)#返回测试集的准确度
score1=clf.score(X_train,Y_train)#返回训练集的准确度
print(score) #0.5555555555555556
print(score1) #0.6714975845410628
#(7)判断是否出现过拟合现象
#如果训练集和测试集的准确率都很低,那么说明模型欠拟合;如果训练集的准确率接近于1而验证集还相差甚远,说明模型典型的过拟合
#由此可见没有过拟合
#(8)查看每个特征的重要程度
name=['age','sex','cp','trestbps','chol','fbs','restecg','thalach','exang','oldpeak','slop','ca','thal']
importances=[*zip(name,clf.feature_importances_)]
print(importances)
#(9)决策树可视化
#clf:分类器
# feature_names:列名
# class_name:分类标签名
# filled:是否填充颜色
# rounded:图形边缘是否美化
# names1=names[0:-1] #结果的可能性也就是患心脏病程度
dot_data=tree.export_graphviz(clf,feature_names=name,class_names=
['0','1','2','3','4'],filled=True,rounded=True)
# graph = graphviz.Source(dot_data)
# graph.render("E:tree.pdf") --------这种方法报错,系统找不到dot,可能我环境变量没配对
#画图
graph = pydotplus.graph_from_dot_data(dot_data)
#保存成图片
graph.write_png('heart_disease1.png')4.结果展示
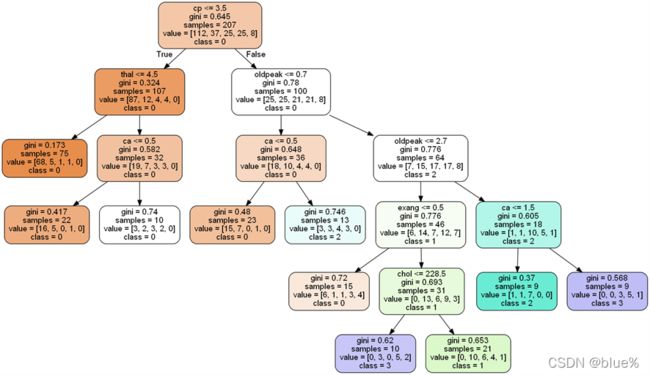
5.分析
由决策树可知,胸部疼痛类型的jini指数最大,说明它是最重要的因素,当cp<=3.5时也就是cp=[1,2,3]时不会患心脏病,当cp>3.5也就是等于4时,st压低oldpeak<=0.7,并且血管数ca<=0.5也就是血管数=0时不会患心脏病……..
患心脏病最大概率的两种情况是:
- cp=4,oldpeak<=2.7,exang=1,chol<=228.5的时候患心脏病概率的等级为3级(有严重的胸部疼痛,并且st压低小于等于2.7,运动时有心绞痛,胆固醇数值小于228.5)
- cp=4,oldpeak>2.7,ca>1.5也就是ca=[2,3] 的时候患心脏病概率的等级为3级(有严重的胸部疼痛,并且st压低大于2.7,血管数为2或3)
如有不对的地方,希望能给予指正,我们共同进步!