一文看懂推荐系统:物品冷启02:简单的召回通道
一文看懂推荐系统:物品冷启02:简单的召回通道
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
提示:文章目录
文章目录
- 一文看懂推荐系统:物品冷启02:简单的召回通道
- 物品冷启动:简单的召回通道
-
- 召回的难点
- 改造双塔模型应对冷启动
-
- defaulting embedding
- 利用相似物品的embedding向量
- 类目召回通道
- 基于关键词的召回
- 总结
物品冷启动:简单的召回通道
大家好,上节介绍了物品冷启动的基本概念和评价指标,
从这节开始,我们研究冷启动的具体技术,我从召回开始讲起,
有很多种适用于冷启动的召回通道。
我先讲几类最简单的召回通道,我们先分析一下召回有哪些难点
召回的难点
在小红书,我们做召回要依据哪些信息?
我们来分析一下新笔记有哪些信息,而又缺少哪些信息,

笔记都有图片、文字之类的内容。有的笔记还标注了地点、新笔记,
还有算法或者人工打的标签,比如笔记的内幕、
笔记的内容和标签都是做召回的依据。
但是新笔记缺少一些非常重要的信息,给推荐系统造成了很大的困难。
用户对笔记的点击、点赞的统计数据可以反映出笔记本身的质量,以及什么样的用户喜欢这篇笔记。
这为精准推荐的帮助很大,可惜新笔记没有这些信息,
而且item cf user cf之类的召回通道需要知道笔记跟哪些用户有过交互,
如果一篇笔记还没有跟用户交互,就走不了iphone cf这种召回通道
冷启动缺少的另一个关键信息是,笔记的ID in bedding
召回和排序模型都有embedding层,把每个笔记ID映射到一个向量,
这个向量是从用户跟笔记交互的行为中学习出来的
可新发布的笔记的这个向量是刚刚初始化的,还没有用反向传播更新,
也就是说新笔记的ID in beating啥都不是。
大家应该都知道,笔记的ID embedding是召回和排序中最重要的特征之一,
缺少这个特征会让召回和排序变得很不准。
概括一下冷启给召回带来的困难,由于缺少用户交互,双卡模型还没有学好,笔记ID embedding。

这会导致双塔模型的效果不好,
双塔模型是推荐系统中最重要的召回通道,没有之一
离开双塔模型很难做好新笔记的推荐,
缺少笔记ID embedding不只会影响召回,其实还会影响排序,让排序模型的预估做不准。
item cf 也是很重要的召回通道,想要用item cf,就需要知道有哪些用户跟这个物品有过交互,
跟新物品交互过的用户非常少,所以item cf对新物品不适用。
我详细解释一下为什么item cf不适用于物品能启动???这是两篇笔记。
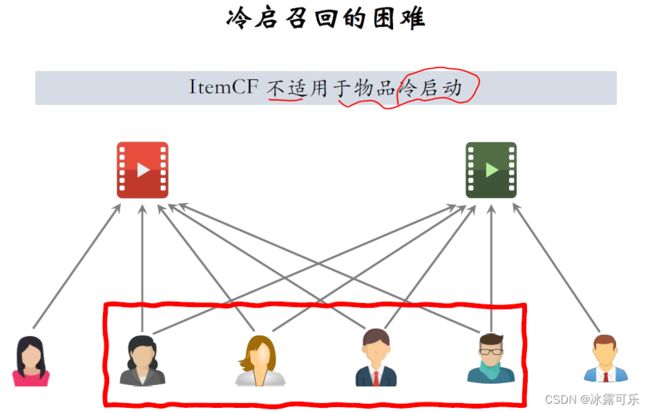
item cf做召回的原理是判断两篇笔记的相似度有多高
要根据与笔记交互过的用户来判定两篇笔记的相似度。
上面这些用户跟两篇笔记中至少一篇交互过,红框这部分用户是重合的,他们同时喜欢两篇笔记。
重合度有多大,可以反映出两篇笔记的相似度有多高。

假设右边绿色的物品是新笔记,新笔记还没有跟用户发生交互,
或者只跟很少几个用户发生交互,
那么Item cf就没有办法根据重合的用户来计算两篇笔记的相似度,所以我说item self不适用于冷启动。
item cf是推荐系统中最重要的召回通道之一,
但是它对冷启动不适用,
双塔模型比item cf更重要,这种深度学习的模型需要用笔记的ID embedding,
所以直接用于冷启效果不好,想要用双塔模型的话,需要做特殊的处理,

类目、关键词是两种弱个性化的召回通道。
在笔记刚刚发布的时候,这两种召回通道是最有用的,
但是在笔记发布一段时间之后,这两种召回通道会失效,
聚类召回和look like也是专门针对新物品的召回通道,
这节详细讲解蓝框中这2类召回通道,他们都很简单,很容易理解。
后面两节再详细讲解聚类召回和look like召回。
改造双塔模型应对冷启动
我们首先讨论如何改造双塔模型,让它适用于冷启动。
这就是常见的双塔模型,左边是用户塔,输入是用户特征,
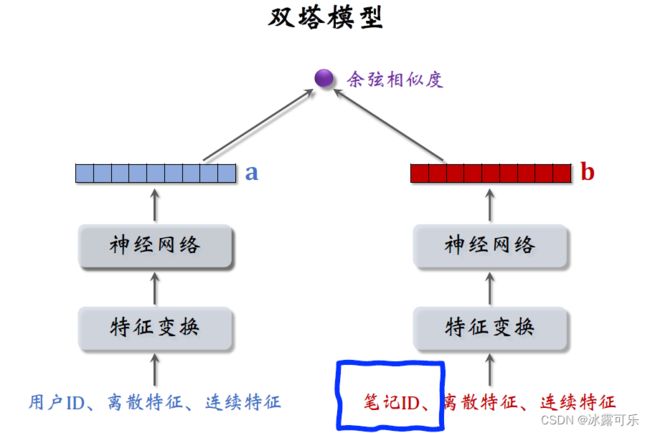
右边是物品塔,输入是笔记ID和其他笔记特征,
两个塔各自输出一个向量,
两个向量的余弦相似度表示用户对物品的兴趣,
物品ID,也就是笔记ID是物品塔中最重要的特征。
神经网络有一个embedding层,把笔记ID映射成向量,
每篇笔记都有一个ID embedding,需要从用户和笔记的交互中学习。
可是新笔记还没有跟几个用户交互过,所以他的embedding向量还没有学好。
如果直接用双塔模型做新笔记的召回效果会不太好。
我介绍两种改进ID in bedding的方案。
defaulting embedding
第一种方案是让新笔记使用defaulting embedding,

也就是说,让所有新笔记共享一个ID embedding,而不是用新笔记自己真正的ID,
那么,所有新笔记的ID embedding向量都是相同的,这个向量就叫做defaulding belling
使用defaulting bedding在实践中是可以拿到收益的,为什么?
新笔记自己的ID embedding向量还没有学到
不如大家先共享一个默认的向量,这个向量是学出来的,而不是随机初始化或者全0初始化学出来的。
比随机初始化的全0初始化更好。
新笔记发布之后,逐渐会有点击和交互这些信号可以用来学习笔记的ID embedding,
当我下次模型训练的时候,新笔记的ID embedding向量才被学到。
利用相似物品的embedding向量
另一种初始化新笔记ID embedding的方法是利用相似物品的embedding向量,

当新笔记发布之后,查找top k内容最相似的高曝光笔记
在小红书的应用中相似,可以用图片文字类目来定义。
用多模态神经网络把一篇笔记的图文内容表征为一个向量。
每当一篇新笔记发布的时候,寻找最相似的K的向量就行,
把找到的K篇高曝光笔记的embedding向量取平均作为新笔记的embedding,
之所以用高曝光笔记,是因为他们的ID embedding通常学的比较好,
在实践中通常会用多个向量召回池,比如一小时新笔记,六小时新笔记,24小时新笔记,还有30天老笔记。

用多个召回池可以让新笔记有更多的机会曝光。
假如只有一个30天笔记的召回池,那么新笔记被召回的几率很小。很难得到曝光,
所有这些召回使用的是同一个双塔模型,所以不会增加训练模型的代价。
类目召回通道
刚才讨论了双塔模型,下面我要讲类目召回通道,
还有一些相似的召回通道,比如关键词召回我就不细说了,
只在后面简单提一下,凡是做信息流社交电商的互联网公司都会维护每一位用户的画像,
画像中记录了用户的兴趣点,比如感兴趣的类目感兴趣的关键词,有的是用户自己填写的。
有的是算法自动推断出来的,
我经常刷小红书,所以算法能够推断出我感兴趣的类目,包括美食、科技、数码、电影,
我感兴趣的关键词包括纽约、职场、搞笑、程序员、大学这些类目的关键词可以用于召回。

下面我要讲基于类目的召回通道,在小红书,我们的系统维护一份从类目到笔记的索引。
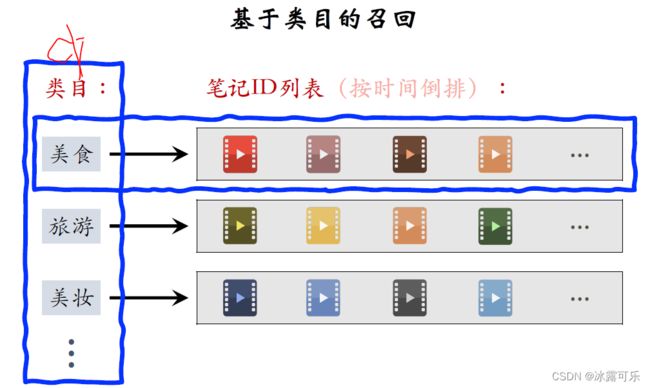
所以上的T是类目,比如美食、旅游、美妆这样比较大的类目,
也可以是更细腻度的类目,比如日本料理、国内旅游护肤品这样的类目,
每个类目后面是一个笔记的列表,按照发布时间倒排,最新发布的笔记排在最前面。
刚才讲了系统维护一个从类目到笔记的索引,要用这个索引召回新笔记,
一个用户刷新小红书的时候,系统要给他做推荐。
系统根据这位用户的画像,知道他对哪些类目感兴趣,取回这些类目,
比如他对美食和旅游感兴趣,然后到类目索引上找到美食和旅游对应的两个笔记列表,

取回笔记列表上美食的前k个可以填笔记,旅游的前k个可以填笔记,
这样就得到2K篇笔记作为召回的结果。
刚才介绍了基于类目的召回,还有几种很相似的召回通道。
基于关键词的召回
比如基于关键词的召回原理跟类目召回是完全一样的,
索引上的key是关键词,每个关键词后面有一个笔记列表,
按照时间倒排,给用户做推荐的时候,根据用户画像上用户感兴趣的关键词做召回。

跟类目召回唯一的区别就是这里用关键词代替类目。
刚才讲了,基于类目的召回和基于关键词的召回,
这两种召回通道都有很明显的缺点,
第一个缺点是只对刚刚发布的新笔记有效。
类目索引和关键词索引都是按照笔记发布的时间倒排,
刚刚发布的新笔记排在最前面,做召回的时候,每次取回某类目或者某关键词下面最新的K篇笔记,
如果笔记已经发布了几小时,那么大概率会被排在几百甚至几千的位置上。
也就是说,这篇笔记再也没有机会被召回了。
类目召回有关键词召回留给每篇笔记的窗口,留给每篇笔记的窗口期很短,

两种召回通道的另一个缺点是,若个性化不够精准,
按照用户感兴趣的类目关键词做召回,其实是比较宽泛的。
假如我喜欢观赏鱼,它属于宠物的类目,但是最新发布的100篇宠物笔记可能都是猫猫狗狗的,
大概率没有我感兴趣的观赏鱼,于是召回的100篇都是我不感兴趣的。
虽然类目召回和关键词召回的缺点很明显,但他们仍然对冷起很重要。
他能让刚刚发布的新笔记立刻获得曝光,有助于提升作者的发布积极性。
最后总结一下这节内容,新笔记的召回是比较困难的,有的召回通道不适用,

有的召回通道需要改造后才使用。
为了做好冷启动,工业界有一些专门的新物品召回通道。
这节我们重点有了双塔模型召回和类目关键词召回,
后面两节介绍聚类召回和look like召回。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:双塔模型召回和类目关键词召回