论文笔记:BBN: Bilateral-Branch Network with Cumulative Learningfor Long-Tailed Visual Recognition

论文地址:https://arxiv.org/abs/1912.02413
代码地址:https://github.com/megvii-research/BBN
文章目录
-
- 1 动机
-
- 1.1 问题
- 1.2 How class re-balancing strategies work
- 1.3 解决方法
- 2 BBN(Bilateral-Branch Network)
-
- 2.1 bilator-branch结构
-
- (1) Data samplers
- (2) Weight share
- 2.2 cumulative learning strategy
- 2.3 输出logit和损失函数
- 3 实验
-
- 3.1 实验参数
-
- 1 CIFAR-LT(10, 100)
- 2 iNaturalist(2017,2018)
- 3.2 实验结果
-
- 1 同其他Class balance性能对比
- 2 自身对比
- 3 消融实验
- 4 参考文献
1 动机
1.1 问题
作者指出用于long-tailed任务中常用的class rebalance方法虽然表现出了很好的效果,但是会破坏模型对于deep features的表现能力。

作者分析Class re-balance 方法能产生较好的分类性能,但是在通过class re-balance之后,每个类别的类内分布变得更加分散。
1.2 How class re-balancing strategies work
作者为了进一步验证上述观点的正确性,使用单一控制变量法进行了对照实验。
-
将模型分成了feature extrator(backbone)和classifier两部分。
-
对于class re-balance方式分别选择了Re-Sampling、Re-Weighting两种,外加正常分类过程中经常使用的Cross entropy进行实验。
-
设计了一个两阶段实验的方式:
(1)Representation learning manner:先直接使用Cross Entropy或class re-balance方法只对分类模型feature extrator部分进行训练。
(2)Classifier learning manner:再固定模型feature extrator参数不动,参照(1)中的训练策略重头对模型的classifier部分进行训练。

-
通过横向对比(控制Classifier learning manner不变),对于Representation learning manner使用RW(Re-Weighting)和RS(Re-Sampling)都降低了性能。
-
通过纵向对比(控制Representation learning manner不变),对于Classifier learning manner使用RW和RS分类性能都有所提升。
-
不仅在Long-tailed CIFAR-100-IR50(左图)上呈现了这种现象,在Long-tailed-10-IR50(右图)上也反映了相同的结果.
-
在训练模型feature extrator阶段使用Cross Entropy,在训练classifier阶段使用RS时获得了最好的分类效果。
结论: RW和RS能提升分类器的性能,但是会降低模型对于deep features的表达.
1.3 解决方法
-
提出了一个通用的模型BBN,兼顾了representation learning 和classifier learning,
-
开发了一种新的积累学习策略,用于调整BBN模型两个分支(conventional learning和Re-Balancing)学习,其具体的体现方式为: 在训练过程中先让模型更加倾向于学习universal pattern然后在逐渐关注于tail class
2 BBN(Bilateral-Branch Network)

2.1 bilator-branch结构
(1) Data samplers
-
conventional learning branch采用uniform sampler
-
Re-Balance brach采用reversed sampler, 采样概率计算方式为:
P i = w i ∑ j = 1 C w j w i = N m a x N i P_i=\frac{w_i}{\sum^C_{j=1}w_j}\\ w_i=\frac{N_{max}}{N_i} Pi=∑j=1Cwjwiwi=NiNmax
先通过概率 P i P_i Pi对类别进行采样,再对类别样本进行均匀采样.然后将两个分支得到的样本同时输入模型进行训练.
(2) Weight share
使用了ResNet-32和ResNet50作为骨干网络, 除去最后一个residual block之外, 其他的block在两个分支上权重共享.
作用:
-
conventional learning分支上学到的特征能更好的用于Re-Balance分支
-
减少网络哟计算量.
2.2 cumulative learning strategy
在训练过程中通过 α \alpha α参数调整两个不同分支的权重, α \alpha α随着epoch的增加逐渐减小,而在inference过程中则简单的将 α \alpha α设置为0.5.
训练过程中 α \alpha α变化方式为:
α = 1 − ( T T m a x ) 2 T : 当前的 e p o c h T m a x : 最大 e p o c h \alpha=1-(\frac{T}{T_{max}})^2\\ T:当前的epoch\\ T_{max}:最大epoch α=1−(TmaxT)2T:当前的epochTmax:最大epoch
2.3 输出logit和损失函数
输出logit:
z = α W c T f c + ( 1 − α ) W r T f r z=\alpha W^T_cf_c+(1-\alpha)W^T_rf_r z=αWcTfc+(1−α)WrTfr
loss:
L = α E ( p ^ , y c ) + ( 1 − α ) E ( p ^ , y c ) L=\alpha E(\hat{p}, y_c)+(1-\alpha)E(\hat{p}, y_c) L=αE(p^,yc)+(1−α)E(p^,yc)
其中:
f c f_c fc: conventional learning分支中通过GAP之后的特征向量
f r f_r fr: Re-Balance 分支中通过GAP之后的特征向量
W T W^T WT: classifier的权重.
3 实验
3.1 实验参数
1 CIFAR-LT(10, 100)
(1) preprocess:
-
random crop:32x32
-
horizontal flip
-
padding:4 pixels each side
(2) backbone: ResNet32
(3):training details:
- momentum: 0.9
- weight decay: 2 ∗ 1 0 − 4 2*10^{-4} 2∗10−4
- batchsize:128
- epochs:200
- lrschduler: multistep(0, 120, 160), gamma:0.01, startlr=0.1
2 iNaturalist(2017,2018)
(1)preprocess:
- random_resized_crop(先resize到256再crop到224)
- random_horizontal_flip
(2)backbone:ResNet50
(3)training details:
-
momentum:0.9
-
weight decay:$1*10{-4}
-
batchsize: 128(代码中参数)
-
epochs:180 (代码中参数)
-
lrscheduler: multistep(0, 120, 160) gamma:0.1, base_lr:0.4(代码中参数) ps:这里论文中给的epoch是60, 80但是代码中具体为120, 160
3.2 实验结果
1 同其他Class balance性能对比


2 自身对比
在Re-Balancing 分支使用不同的采样方式进行对比.

对于 α \alpha α的不同变化方式对比.

3 消融实验

BBN的Conventional分支的性能与直接使用CE相近,这表明了BBN模型保留了对于Long-tailed数据的特征提取能力.而BBN的Re-Balancing分支的效果比RW和RS要好,作者表示这是因为模型中间的权重共享让Conventional分支学到的特征更好的用到了Re-Balance分支上.
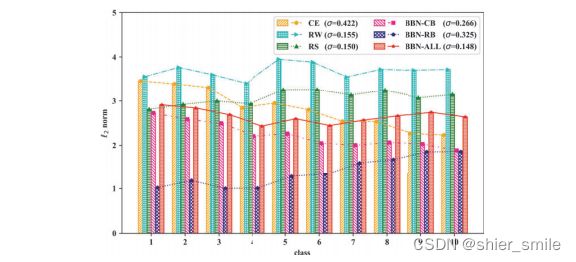
作者还对BBN模型的Classifier中的权重进行了可视化,并与其他class balance方式进行了对比.
- BBN-ALL的方差最小, RW和RS虽然分布较为平坦但是方差比BBN-ALL略大.
- BBN-CB(Conventional分支)的分布情况和CE相似.
- BBN-RB(Re-Balance分支)分布符合reversed 的采样分布.
4 参考文献
论文:BBN: Bilateral-Branch Network with Cumulative Learningfor Long-Tailed Visual Recognition
blog:https://zhuanlan.zhihu.com/p/109648173
本贴写于2022年8月8号, 未经本人允许,禁止转载.