Paddle-Human 行为识别 | 使用NTU-RGB-D自定义数据集训练STGCN动作识别模型 (二)
上文说到Paddle-Human开源了行为识别模型,但是只能识别摔倒行为,那么现在我们将让模型能够识别更多行为。
一、训练环境搭建
项目地址:
https://github.com/PaddlePaddle/PaddleVideo https://github.com/PaddlePaddle/PaddleVideo训练STGCN是在PaddleVideo开发套件中完成的
https://github.com/PaddlePaddle/PaddleVideo训练STGCN是在PaddleVideo开发套件中完成的
环境可以直接沿用上一篇博客里面的环境,毕竟torch装一遍太慢了Paddle-Human 实时行人分析 | 安装测试指南_訢詡的博客-CSDN博客PP-Human是基于飞桨深度学习框架的业界首个开源的实时行人分析工具,具有功能丰富,应用广泛和部署高效三大优势。PP-Human 支持图片/单镜头视频/多镜头视频多种输入方式,功能覆盖多目标跟踪、属性识别和行为分析。能够广泛应用于智慧交通、智慧社区、工业巡检等领域。支持服务器端部署及TensorRT加速,T4服务器上可达到实时。https://blog.csdn.net/Andrwin/article/details/124248527
然后可以安装一下PaddleVideo里面带的requirements.txt
pip install -r requirements.txt -i https://pypi.douban.com/simple二、FSD-10训练花样滑冰数据集(可跳过)
我将这个部分写在前面是因为这个数据集比较小,而且存在一个测试数据,对于整个STGCN的训练过程和测试过程有比较直观的感受,但这个部分并不重要,可以跳过。
要知道STGCN的输入一个关键点序列而非原始视频图像,那么对于NTU-RGB-D并没有任何测试数据可供推理,不能推理的模型一无是处。
数据集介绍:
基于飞桨实现花样滑冰选手骨骼点动作识别大赛数据集旨在通过花样滑冰研究人体的运动。在花样滑冰运动中,人体姿态和运动轨迹相较于其他运动呈现复杂性强、类别多的特点,有助于细粒度图深度学习新模型、新任务的研究。
在FSD-10 中,所有的视频素材从2017 到2018 年的花样滑冰锦标赛中采集。源视频素材中视频的帧率被统一标准化至每秒30 帧,并且图像大小是1080 * 720 来保证数据集的相对一致性。之后我们通过2D姿态估计算法Open Pose对视频进行逐帧骨骼点提取,最后以.npy格式保存数据集。
下载地址:
https://videotag.bj.bcebos.com/Data/FSD_train_data.npyhttps://videotag.bj.bcebos.com/Data/FSD_train_data.npyhttps://videotag.bj.bcebos.com/Data/FSD_train_label.npyhttps://videotag.bj.bcebos.com/Data/FSD_train_label.npy 下载完成后直接把这两个npy放在PaddleVideo项目根目录就行了,然后将文件前面的“FSD_”这几个字删掉,其次就是:
/PaddleVideo/configs/recognition/stgcn/stgcn_fsd.yaml
这个配置文件里面把batch size改成32,不然8G显存不够用。
训练开始:
python main.py -c configs/recognition/stgcn/stgcn_fsd.yaml如果环境正常的话这个就已经开始训练了,因为这个数据集没有开源测试数据,所以就不做验证了
2080大概一个小时的样子就能训练完,没有测试集直接导出推理模型:
python tools/export_model.py -c configs/recognition/stgcn/stgcn_fsd.yaml -p output/STGCN/STGCN_epoch_00090.pdparams -o inference/STGCN训练完的权重会保存在PaddleVideo/output/STGCN/里面
导出的推理模型会保存在PaddleVideo/inference/STGCn/里面,有三个文件
最后使用项目自带的单例数据做一次推理查看模型训练的怎么样:
python tools/predict.py --input_file data/fsd10/example_skeleton.npy --config configs/recognition/stgcn/stgcn_fsd.yaml --model_file inference/STGCN/STGCN.pdmodel --params_file inference/STGCN/STGCN.pdiparams --use_gpu=True --use_tensorrt=False可以看到准确推断为类27(虽然咱也不知道类27是个啥动作),但是至少和答案一致,且置信度99.97%
到这里FSD-10这个数据就做完了,可以把数据集、训练结果给清除了
三、NTU-RGB-D数据集
先简单介绍下这个数据集:
数据集原始地址:ROSE Labhttps://rose1.ntu.edu.sg/dataset/actionRecognition/
这个数据集分为两个数据集:
(1)NTU-RGB-D 包含了A1-A60类,共60个类
(2)NTU-RGB-D 120 包含了A1-A120类,共120个类
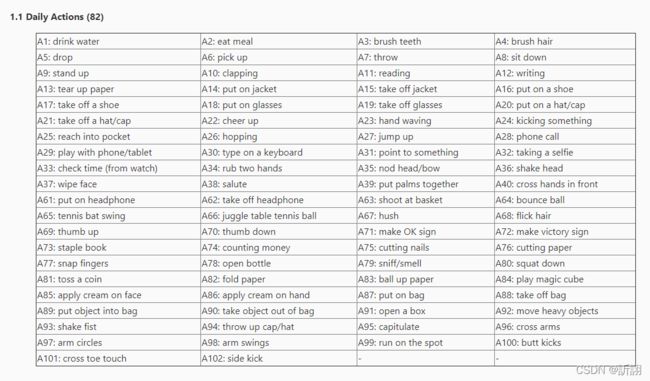
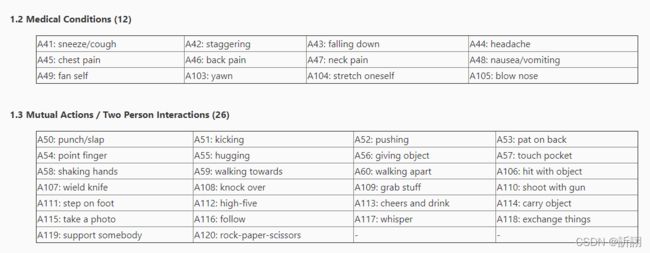
下面是详细的类表和草草机翻:

关于这个数据集的容量:
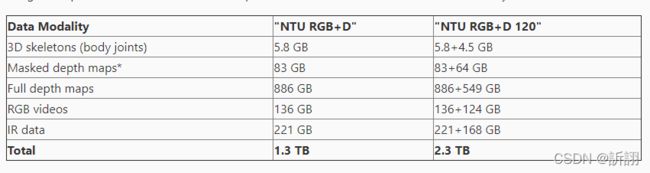
训练STGCN只需要3D骨骼数据,大概需要42G左右的硬盘空间。
因为A1-A60和A61-A120都有我需要识别的行为,所以我要用 NTU-RGB-D 120这个大的数据集。
如果A1-A60已经能够满足你的需求,那么你可以直接从https://videotag.bj.bcebos.com/Data/NTU-RGB-D.tarhttps://videotag.bj.bcebos.com/Data/NTU-RGB-D.tar
下载处理好的数据(可直接用于训练)
如果你想训练NTU-RGB-D 120,那么继续往下看
四、搭建数据集转换环境
先说一下大致过程,原始的NTU-RGB-D是没有办法直接训练的,它由很多个.skeleton组成,我并未详细了解这种数据的详细组成,从https://github.com/open-mmlab/mmskeleton/blob/master/doc/SKELETON_DATA.md 得知了如何将NTU-RGB-D处理为用于训练STGCN的步骤,那么这个转换工具也需要另外的虚拟环境。
NTU RGB+D
NTU RGB+D can be downloaded from their website. Only the 3D skeletons(5.8GB) modality is required in our experiments. After that, this command should be used to build the database for training or evaluation on mmskeleton:
python deprecated/tools/data_processing/ntu_gendata.py --data_path本文作者訢詡https://blog.csdn.net/Andrwin欢迎关注 where the
is the directory path of 3D skeletons annotations of the NTU RGB+D dataset you download.
项目地址:
https://github.com/open-mmlab/mmskeletonhttps://github.com/open-mmlab/mmskeleton
下面开始搭建mm-lab:
1、先建个虚拟环境
conda create -n open-mmlab python=3.7 -y
2、安装torch
conda activate open-mmlab
conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch3、下载好项目文件之后
cd mmskeleton-master
pip install cython -i https://pypi.douban.com/simple以及其他环境
pip install -r requirements.txt -i https://pypi.douban.com/simple然后卸载mmcv
pip uninstall mmcv -y安装指定版本的mmcv
pip install mmcv==0.4.3 -i https://pypi.douban.com/simple卸载pillow
pip uninstall pillow -y安装<7.0.0的pillow
pip install pillow==6.2.2 -i https://pypi.douban.com/simple4、安装nms
cd mmskeleton/ops/nms/
python setup_linux.py develop安装成功的话会显示
Creating /home/nvidia/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/nms.egg-link (link to .)
Adding nms 0.0.0 to easy-install.pth file
Installed /home/nvidia/mmskeleton-master/mmskeleton/ops/nms
Processing dependencies for nms==0.0.0
Finished processing dependencies for nms==0.0.0
5、安装pycocotools
cd ../../../
pip install pycocotools -i https://pypi.douban.com/simple注意检查是否安装成功
Successfully built pycocotools
Installing collected packages: typing-extensions, python-dateutil, kiwisolver, fonttools, cycler, matplotlib, pycocotools
Successfully installed cycler-0.11.0 fonttools-4.32.0 kiwisolver-1.4.2 matplotlib-3.5.1 pycocotools-2.0.4 python-dateutil-2.8.2 typing-extensions-4.1.1
还有一个
pip install terminaltables -i https://pypi.douban.com/simple6、下载一个mmdetection离线包
https://github.com/open-mmlab/mmdetection/archive/v1.0rc1.zip
一般ubuntu默认把下载的东西存到Downloads,接着用pip安装这个zip压缩包
python -m pip install ~/Downloads/mmdetection-1.0rc1.zip -i https://pypi.douban.com/simple7、下载mmcv的预训练权重
第一个 pose_hrnet_w32_256x192-76ea353b.pth
第二个 cascade_rcnn_r50_fpn_20e_20181123-db483a09.pth
将其放入~/.cache/torch/checkpoints/这个文件夹下面
它自己下载不下来,我是在网上找的,打包好了https://download.csdn.net/download/Andrwin/85175564https://download.csdn.net/download/Andrwin/85175564
8、测试环境
python mmskl.py pose_demo如果没报错的话,大概1分钟后会显示推理完成
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 300/300, 5.9 task/s, elapsed: 51s, ETA: 0s
Generate video:
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 300/300, 1300.6 task/s, elapsed: 0s, ETA: 0s
Video was saved to work_dir/pose_demo/skateboarding.mp4
那个work_dir就在项目根目录,如果环境安装过程中存在无法解决的问题,尝试参考其他安装教程:(我就看的这着但是各种报错,跌跌撞撞总算安装好了)
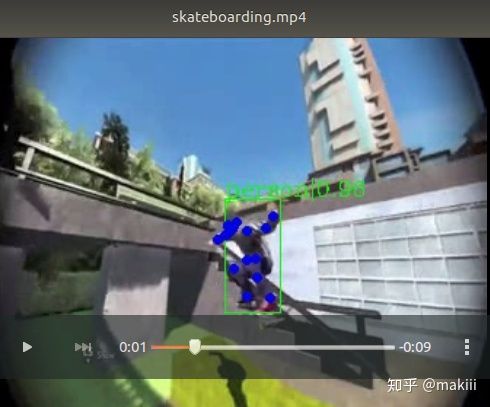
学习open-mmlab之mmskeleton安装 - 知乎@misc{mmskeleton2019, author = {Sijie Yan, Yuanjun Xiong, Jingbo Wang, Dahua Lin}, title = {MMSkeleton}, howpublished = {\url{https://github.com/open-mmlab/mmskeleton}}, year = {2019} }mmskeleton官… https://zhuanlan.zhihu.com/p/161943990 生成的视频就是下面这个图里面的样子,但是不知道为啥的生成的视频里面蓝点乱七八糟的,下面的图是从上面的知乎帖子里面哪来的,如果能生成这个,说明环境已经搭建好了。
https://zhuanlan.zhihu.com/p/161943990 生成的视频就是下面这个图里面的样子,但是不知道为啥的生成的视频里面蓝点乱七八糟的,下面的图是从上面的知乎帖子里面哪来的,如果能生成这个,说明环境已经搭建好了。
五、下载数据
第一部分:A1-A60:https://drive.google.com/open?id=1CUZnBtYwifVXS21yVg62T-vrPVayso5Hhttps://drive.google.com/open?id=1CUZnBtYwifVXS21yVg62T-vrPVayso5H
第二部分:A61-A120
https://drive.google.com/open?id=1tEbuaEqMxAV7dNc4fqu1O4M7mC6CJ50whttps://drive.google.com/open?id=1tEbuaEqMxAV7dNc4fqu1O4M7mC6CJ50w难点主要就是需要科学上网,心疼我的流量
六、生成数据
把上面两个数据下载以后合并到一个文件夹里面,这个文件夹里面会有114480个子文件,注意核对数目
回到之前的mm-lab环境,在项目根目录执行
python deprecated/tools/data_processing/ntu_gendata.py --data_path nturgb+d_skeletons文件夹的路径这个要执行一会,奇妙的是一条龙服务,没有什么分割比例让你选
(43691/43691) Processing xsub-train data: [------------------------------]
(70487/70487) Processing xsub-val data: [------------------------------]
(76046/76046) Processing xview-train data: [------------------------------]
(38132/38132) Processing xview-val data: [------------------------------]
完成后就终于做完了NTU-RGB-D 120数据集,保存在mmskeleton/data/NTU-RGB-D里面
比对下和之前直接下载可用的数据集:
NTU-RGB-D | NTU-RGB-D-120
xsub/train_data.npy 7.2GB | 7.9GB
xsub/train_label.pkl 1.6MB | 1.8MB
xsub/val_data.npy 3.0GB | 12.7GB
xsub/val_label.pkl 675.3kB | 2.9MB
xview/train_data.npy 6.8GB | 13.7GB
xview/train_label.pkl 1.5MB | 3.1MB
xview/val_data.npy 3.4GB | 6.9GB
xview/val_label.pkl 775.5kB | 1.6MB
七、训练NTU-RGB-D-120数据集
回到paddle-human的环境
修改/PaddleVideo/configs/recognition/stgcn/stgcn_ntucs.yaml里面的第10行num_classes从60改为120,然后使用
python -m paddle.distributed.launch --gpus="0" --log_dir=log_stgcn main.py --validate -c configs/recognition/stgcn/stgcn_ntucs.yaml即可开始训练。
补充:
关于X-sub 和 X-view的区别:
NTU数据集在划分训练集和测试集时采用了两种不同的划分标准。
1、Cross-Subject
Cross-Subject按照人物ID来划分训练集和测试集,训练集40320个样本,测试集16560个样本,其中将人物ID为 1, 2, 4, 5, 8, 9, 13, 14, 15,16, 17, 18, 19, 25, 27, 28, 31, 34, 35, 38的20人作为训练集,剩余的作为测试集。2、 Cross-View
按相机来划分训练集和测试集,相机1采集的样本作为测试集,相机2和3作为训练集,样本数分别为18960和37920。
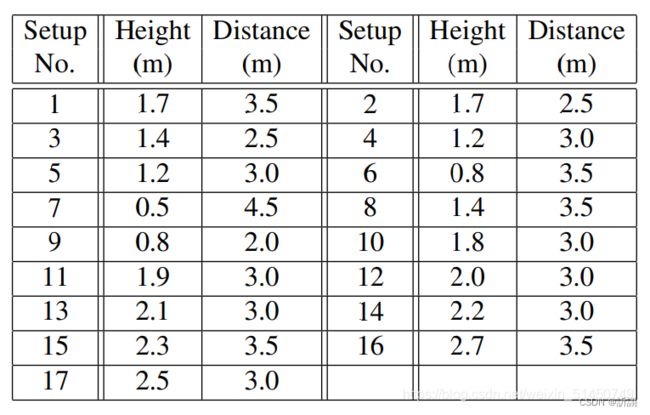
说到相机就不得不说相机的设置规则,三个相机,相机的垂直高度都是一样的,水平角度分别为-45°、0°和45°,每个动作执行人做两遍相同的动作,一个次对着左边的相机,一次对着右边的相机,也就是说最后会采集到2×3个不同角度的信息。最后,设置不同的相机高度及距离以增加视角多样性,并赋予一个设置号(1-17),见表。