MobileNetV1 之 Depthwise separable convolution(深度可分离卷积)
MobileNetV1 之 Depthwise separable convolution(深度可分离卷积)
MobileNetV1是2017年提出的,最核心的创新点就是提出了深度可分离卷积。下面进行详细的介绍,以方便理解深度可分离卷积。(论文链接:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications)
以普通卷积为例:
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(9, 9, 4)))
model.add(tf.keras.layers.Conv2D(64, 3, activation='relu'))
#----------------------------------------------------------------------------------
# output:
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 7, 7, 32) 1184
_________________________________________________________________
conv2d_1 (Conv2D) (None, 5, 5, 64) 18496
=================================================================
Total params: 19,680
Trainable params: 19,680
Non-trainable params: 0
_________________________________________________________________
'''
如上代码所示,首先输入一个大小为9 * 9 * 4的特征图,经过一个kernel_size= 3, fileters=32的卷积操作,调整通道数为32,最终输出为(7 * 7 * 32),本次卷积的参数量为:3 * 3 * 4 * 32 + 32 = 1184 (卷积参数的通用计算公式为:卷积核大小(3 * 3 ) * 输入通道数 (4)* 输出通道数(32) + 偏置(32,filters的个数))。
然后再经过一个kernel_size=3, filters=64的卷积操作,调整通道数为64 ,最终输出为(5 * 5 * 64),本次卷积的参数量为:3 * 3 * 32 * 64 + 64 = 18496。
通过以上两步卷积操作,我们将输入大小为(9 * 9 * 4)的特征图变成了(5 * 5 * 64)的特征图。
下面将第二个普通卷积替换成深度可分离卷积。
深度可分离卷积又分为深度卷积和逐点卷积,论文中是这样说的。
Depthwise separable convolution are made up of two layers: depthwise convolutions and pointwise convolutions.We use depthwise convolutions to apply a single filter per each input channel (input depth). Pointwise convolution, a simple 1*1 convolution, is then used to create a linear combination of the output of the depthwise layer.
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(9, 9, 4)),)
model.add(tf.keras.layers.DepthwiseConv2D(3, name='depthwise'))
model.add(tf.keras.layers.Conv2D(64, 1, name = 'pointwise'))
model.summary()
#----------------------------------------------------------------------------------
# output:
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 7, 7, 32) 1184
_________________________________________________________________
depthwise (DepthwiseConv2D) (None, 5, 5, 32) 320
_________________________________________________________________
pointwise (Conv2D) (None, 5, 5, 64) 2112
=================================================================
Total params: 3,616
Trainable params: 3,616
Non-trainable params: 0
_________________________________________________________________
'''
如上代码所示,首先使用tensorflow 自带的DepthwiseConv2D进行depthwise convolutions,kernel_size=3,最终输出为(5 * 5 * 32),参数量为: 3 * 3 * 32 + 32 = 320。这里的第一个32是输出通道数,第二个32是偏置,并没有输入的通道数(可理解为1)。可以这样理解,上一次卷积得到的输出大小为(7 * 7 * 32)一共32个通道,在每一个通道上分别使用一个大小为3 * 3 * 1 的卷积核,一共使用了 3 * 3 * 1 * 32 = 288,最后给每个通道上的卷积核加上一个偏置,就是320。
再使用Conv2D进行pointwise convolutions,kernel_size = 1,filters = 64, 最终输出为(5 * 5 * 64),参数量为: 1 * 1 * 32 * 64 + 64 = 2112。
通过以上两步卷积操作,我们最终也得到了(5 * 5 * 64 )的输出。
从(7 * 7 * 32 )到 (5 * 5 * 64),直接使用普通卷积参数量为:18496,使用depthwise convolutions 和 pointwise convolutions 替换,参数量为: 320 + 2112 = 2432。参数量大幅度减少。
下面再来看下论文中给出解释图:
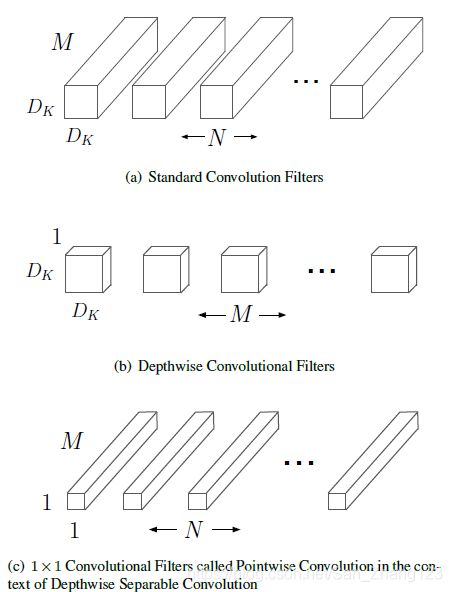 图(a)对应的就是标准的卷积操作,对应上面给出的例子,Dk * Dk = 3 * 3, M表示通道数为32, N输出的通道数为64。
图(a)对应的就是标准的卷积操作,对应上面给出的例子,Dk * Dk = 3 * 3, M表示通道数为32, N输出的通道数为64。
图(b)表示将标准的卷积核按照通道数划分,共划分出M (32) 个,每个大小为Dk * Dk * 1(3 * 3 * 1)。
图(c) 表示逐点卷积的卷积核大小为1 * 1 * M(32), 输出通道数为N(64)。
不使用tensorflow自带的DepthwiseConv2D进行卷积,单独使用Conv2D,也可实现深度可分离卷积。根据之前的分析,需在Conv2D时将输入的通道数调整为上一个特征图的通道数,这里的上一个特征图为(7 * 7 * 32),所以输出通道数为32。还需设置groups 的参数,为输出通道数。该参数能够将通道数进行分离。
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(9, 9, 4)))
model.add(tf.keras.layers.Conv2D(32, 3, groups=32)) # depthwise convolutions
model.add(tf.keras.layers.Conv2D(64, 1)) # pointwise convolutions
model.summary()
#----------------------------------------------------------------------------------
# output:
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 7, 7, 32) 1184
_________________________________________________________________
conv2d_1 (Conv2D) (None, 5, 5, 32) 320
_________________________________________________________________
conv2d_2 (Conv2D) (None, 5, 5, 64) 2112
=================================================================
Total params: 3,616
Trainable params: 3,616
Non-trainable params: 0
_________________________________________________________________
'''
总结:
MobileNetV1 最核心的关键点就是使用深度可分离卷积(Depthwise separable convolution )替代标准卷积。每一次卷积后都加上了BN和Relu层。
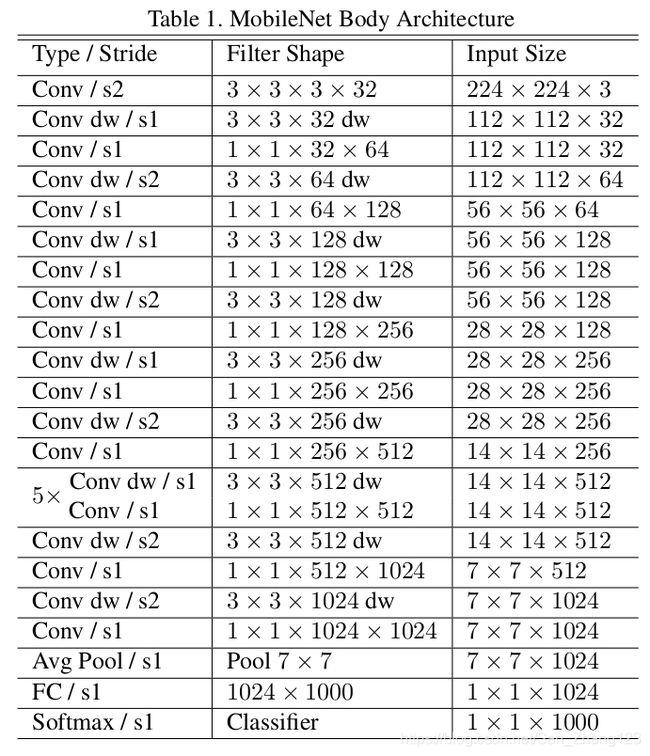
 具体结构如下:
具体结构如下: