【CV】SiamFC:用于目标跟踪的全卷积孪生网络
论文名称:Fully-Convolutional Siamese Networks for Object Tracking
论文下载:https://arxiv.org/abs/1605.07648
论文年份:ECCV 2016
论文被引:2871(2022/05/17)
论文代码:
论文总结
本文提出了一种用于目标跟踪的孪生网络,其是一个简单的方法,即不更新模型或保留过去外观的记忆,不包含额外的线索,例如光流或颜色直方图,不使用边界框回归来改进我们的预测。
孪生网络以真实目标和候选目标样本对作为输入,孪生网络对两个输入应用相同的变换 φ,然后根据 f(z, x) = g(φ(z), φ(x)) 使用另一个函数 g 组合它们的表示。当函数 g 是一个简单的距离或相似度度量时,函数 φ 可以被认为是一个嵌入。
全卷积网络的优势在于,可以为网络提供更大的搜索图像作为输入,而不是相同大小的候选图像,并且它将在单次评估中计算密集网格上所有平移子窗口的相似性。为了实现这一点,作者使用卷积嵌入函数 φ 并使用互相关层 (crosscorrelation layer) 组合生成的特征图。
Abstract
The problem of arbitrary object tracking has traditionally been tackled by learning a model of the object’s appearance exclusively online, using as sole training data the video itself. Despite the success of these methods, their online-only approach inherently limits the richness of the model they can learn. Recently, several attempts have been made to exploit the expressive power of deep convolutional networks. However, when the object to track is not known beforehand, it is necessary to perform Stochastic Gradient Descent online to adapt the weights of the network, severely compromising the speed of the system. In this paper we equip a basic tracking algorithm with a novel fully-convolutional Siamese network trained end-to-end on the ILSVRC15 dataset for object detection in video. Our tracker operates at frame-rates beyond real-time and, despite its extreme simplicity, achieves state-of-the-art performance in multiple benchmarks.
传统上,任意目标跟踪的问题是通过专门在线学习目标外观模型来解决的,使用视频本身作为唯一的训练数据。尽管这些方法取得了成功,但他们仅在线的方法本质上限制了他们可以学习的模型的丰富性。最近,已经进行了几次尝试来利用DCNN的表达能力。但是,当事先不知道要跟踪的目标时,需要在线执行随机梯度下降来适应网络的权重,严重影响系统的速度。在本文中,我们为基本跟踪算法配备了一种新的全卷积孪生网络 (Siamese Network),该网络在 ILSVRC15 数据集上进行端到端训练,用于视频中的目标检测。我们的跟踪器以超越实时的帧速率运行,尽管它非常简单,但在多个基准测试中实现了最先进的性能。
1 Introduction
我们考虑跟踪视频中任意目标的问题,其中目标仅由第一帧中的矩形标识。由于可能要求该算法跟踪任何任意目标,因此不可能已经收集数据并训练了特定的检测器。
几年来,这种场景最成功的范例是使用从视频本身中提取的示例以在线方式学习目标外观的模型 [1]。这在很大程度上归功于 TLD [2]、Struck [3] 和 KCF [4] 等方法的展示能力。然而,仅使用来自当前视频的数据的一个明显缺陷是只能学习相对简单的模型。虽然计算机视觉中的其他问题已经看到越来越普遍地采用从大型监督数据集训练的DCNN(conv-nets),但监督数据的稀缺性和实时操作的限制,阻止了深度学习在这种范式中应用每个视频学习一个检测器。
最近的几项工作旨在使用预训练的DCNN来克服这一限制,该网络是为不同但相关的任务而学习的。这些方法要么应用“浅层”方法(例如相关滤波器),使用网络的内部表示作为特征 [5,6],要么执行 SGD(随机梯度下降)来微调网络的多个层 [7,8,9]。使用浅层方法并没有充分利用端到端学习的优势,在跟踪期间应用 SGD 以实现最先进结果的方法无法实时运行。
我们提倡一种替代方法,其中训练DCNN以在初始离线阶段解决更普遍的相似性学习 (similarity learning) 问题,然后在跟踪期间简单地在线评估该功能。本文的主要贡献是证明这种方法在现代跟踪基准测试中以远远超过帧速率要求的速度实现了极具竞争力的性能。具体来说,我们训练一个孪生网络以在更大的搜索图像中定位示例图像。另一个贡献是一种新颖的 Siamese 架构,它对搜索图像是完全卷积的:通过计算其两个输入的互相关的双线性层实现密集且高效的滑动窗口评估。
我们认为相似性学习方法相对被忽视了,因为跟踪社区无法访问大量的标记数据集。事实上,直到最近,可用的数据集只包含几百个带注释的视频。然而,我们相信用于视频中目标检测的 ILSVRC 数据集的出现 [10](以下简称 ImageNet 视频)使得训练这样的模型成为可能。此外,训练和测试深度模型以使用来自同一域的视频进行跟踪的公平性是一个争议点,因为它最近被 VOT 委员会禁止。我们展示了我们的模型从 ImageNet 视频域泛化到 ALOV/OTB/VOT [1,11,12] 域,使得跟踪基准的视频可以保留用于测试目的。
2 Deep similarity learning for tracking
学习跟踪任意目标可以使用相似性学习来解决。我们建议学习一个函数 f(z, x),它将示例图像 z 与相同大小的候选图像 x 进行比较,如果两个图像描绘相同的目标,则返回高分,否则返回低分。为了在新图像中找到目标的位置,我们可以详尽地测试所有可能的位置,并选择与目标过去外观具有最大相似性的候选者。在实验中,我们将简单地使用目标的初始外观作为示例。函数 f 将从具有标记目标轨迹的视频数据集中学习。
鉴于它们在计算机视觉方面的广泛成功 [13,14,15,16],我们将使用深度卷积网络 (DCNN) 作为函数 f。DCNN的相似性学习通常使用孪生架构来解决 [17,18,19]。孪生网络对两个输入应用相同的变换 φ,然后根据 f(z, x) = g(φ(z), φ(x)) 使用另一个函数 g 组合它们的表示。当函数 g 是一个简单的距离或相似度度量时,函数 φ 可以被认为是一个嵌入。 Deep Siamese conv-nets 先前已应用于人脸验证 [18,20,14]、关键点描述符学习 [19,21] 和 one-shot 字符识别 [22] 等任务。
2.1 Fully-convolutional Siamese architecture
我们提出了一种对候选图像 x 完全卷积的 Siamese 架构。我们说一个函数是完全卷积的,如果它与平移 (translation) 互换。为了给出更精确的定义,引入 Lτ 来表示平移算子 (Lτ x)[u] = x[u − τ],将信号映射到信号的函数 h 是具有整数步长 k 的全卷积,如果
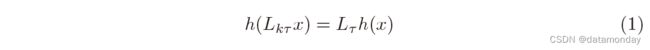
对于任何平移 τ。 (当 x 是有限信号时,这只需要保持输出的有效区域。)
全卷积网络的优势在于,我们可以为网络提供更大的搜索图像作为输入,而不是相同大小的候选图像,并且它将在单次评估中计算密集网格上所有平移子窗口的相似性。为了实现这一点,我们使用卷积嵌入函数 φ 并使用互相关层 (crosscorrelation layer) 组合生成的特征图
![]()
其中 b 1 表示在每个位置取值 b ∈ R 的信号。该网络的输出不是单个分数,而是在有限网格 D ⊂ Z 2 D ⊂ Z^2 D⊂Z2 上定义的分数图,如图 1 所示。请注意,嵌入函数的输出是具有空间支持的特征图,而不是普通向量。相同的技术已应用于当代工作 stereo matching [23]。
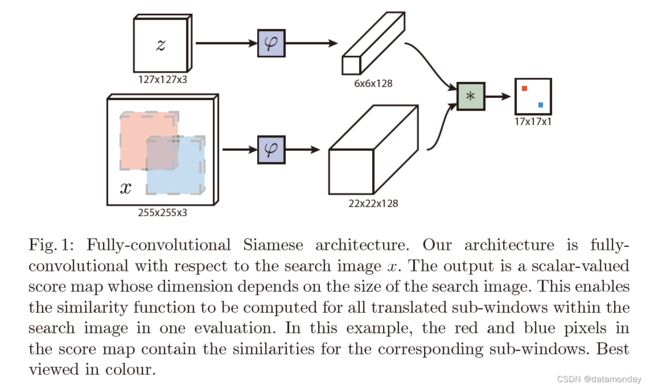
图 1:全卷积孪生架构。我们的架构对于搜索图像 x 是完全卷积的。输出是一个标量值的分数图,其维度取决于搜索图像的大小。这使得能够在一次评估中为搜索图像内的所有平移的子窗口计算相似度函数。在此示例中,得分图中的红色和蓝色像素包含相应子窗口的相似性。最好以彩色观看。
注:上图中的 * 表示卷积操作。这样就可以看成真实目标z(作为滤波器)在候选图像x上的卷积操作,即,一个6×6×128的卷积核在22×22×128图像上的卷积,得到特征图的shape为17×17×1。卷积计算公式:
H o u t = ⌊ [ H i n + 2 × p a d d i n g − d i a l t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) − 1 ] / s t r i d e + 1 ⌋ H_{out} = \lfloor [Hin + 2×padding - dialtion[0] × (kernel \ size[0] - 1) - 1] / stride + 1 \rfloor Hout=⌊[Hin+2×padding−dialtion[0]×(kernel size[0]−1)−1]/stride+1⌋ = [22 + 2×0 - 1×(6 - 1) - 1/1 + 1] = 17,其中没有使用padding,stride=1,没有空洞卷积。
如此可以得到每一个候选图像位置与真实目标之间的相关性。
在跟踪过程中,我们使用以目标先前位置为中心的搜索图像。最大分数相对于分数图中心的位置乘以网络的步幅,得出目标在帧之间的位移。通过组合 (assembling) 小批量缩放图像,在单个前向传递中搜索多个比例。
使用互相关组合特征图并在较大的搜索图像上评估一次网络,在数学上等同于使用内积组合 (inner product) 特征图并在每个平移 (translated) 的子窗口上独立评估网络。但是,互相关层提供了一种非常简单的方法,可以在现有的 conv-net 库的框架内有效地实现此操作。这在测试期间显然很有用,也可以在训练期间加以利用。
2.2 Training with large search images
我们采用判别方法 (discriminative approach),在正负对 (positive and negative pairs) 上训练网络并采用逻辑损失
![]()
其中 v 是单个样本-候选对的实值分数,y ∈ {+1, -1} 是它的真实标签。我们在训练期间通过使用包含示例图像和更大搜索图像的对,来利用网络的完全卷积性质。这将产生一个分数图 v : D → R,每对有效地生成许多示例。我们将分数图的损失定义为单个损失的平均值
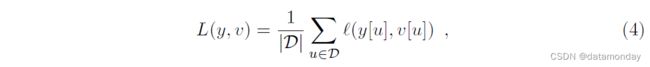
要求分数图中每个位置 u ∈ D 的真实标签 y[u] ∈ {+1, -1}。通过对问题应用随机梯度下降 (SGD) 获得 conv-net θ 的参数
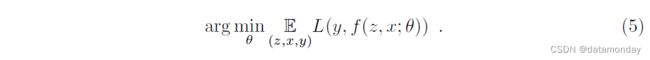

通过提取以目标为中心的示例和搜索图像,从带注释的视频数据集中获得对,如图 2 所示。图像是从视频的两帧中提取的,这两个帧都包含目标并且最多相隔 T 帧。训练期间忽略目标的类别。在不破坏图像纵横比的情况下,对每个图像中目标的比例进行归一化。如果分数图的元素在中心的半径 R 内(考虑到网络的步幅 k),则认为它们属于正例
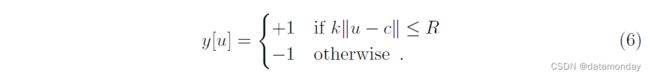
对分数图中正负示例的损失进行加权以消除类别不平衡。
由于我们的网络是完全卷积的,因此它不会学习到中心子窗口的偏差。我们认为考虑以目标为中心的搜索图像是有效的,因为最困难的子窗口以及对跟踪器性能影响最大的子窗口可能是与目标相邻的子窗口。
请注意,由于网络是对称的 f(z, x) = f(x, z),因此在示例中它实际上也是全卷积的。虽然这允许我们在理论上为不同的目标使用不同大小的示例图像,但我们假设大小一致,因为它简化了小批量实现。不过,这个假设在未来可能会放宽。
2.3 ImageNet Video for tracking
2015 年版 ImageNet 大规模视觉识别挑战赛 [10] (ILSVRC) 引入了 ImageNet 视频数据集,作为视频挑战中新目标检测的一部分。参与者需要对来自 30 种不同类别的动物和车辆的物体进行分类和定位。训练和验证集共包含近 4500 个视频,总共超过一百万个带注释的帧。如果与 VOT [12]、ALOV [1] 和 OTB [11] 中的标记序列数量(总共不到 500 个视频)相比,这个数字特别令人印象深刻。我们认为,跟踪社区应该对这个数据集非常感兴趣,不仅因为它庞大的规模,而且因为它描绘的场景和目标与规范跟踪基准中的场景和目标不同。出于这个原因,它可以安全地用于训练深度模型进行跟踪,而不会过度拟合这些基准中使用的视频域。
2.4 Practical considerations
数据集管理 (Dataset curation) 在训练过程中,我们采用 127 × 127 的示例图像和 255 × 255 像素的搜索图像。图像被缩放,使得边界框,加上上下文的附加边距,具有固定的区域。更准确地说,如果紧密边界框的大小为 (w, h) 并且上下文边距为 p,则选择比例因子 s 使得缩放矩形的面积等于一个常数
![]()
我们使用示例图像的面积 A = 1272,并将上下文数量设置为平均维度 p = (w + h)/4 的一半。离线提取每一帧的示例和搜索图像,以避免在训练期间调整图像大小。在这项工作的初步版本中,我们采用了一些启发式方法来限制从中提取训练数据的帧数。相反,对于本文的实验,我们使用了 ImageNet Video 的所有 4417 个视频,其中包含超过 200 万个带标签的边界框。
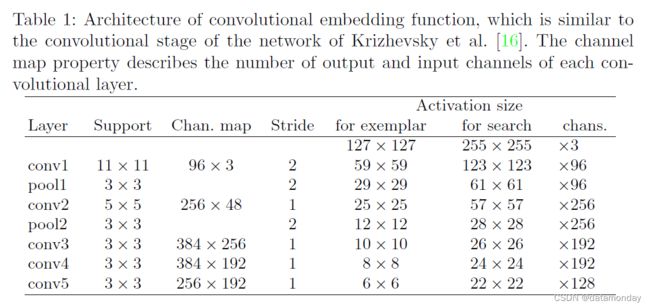
网络架构 我们为嵌入函数 φ 采用的架构类似于 Krizhevsky 等人 [16] 的网络的卷积阶段。参数和激活的维度在表 1 中给出。在前两个卷积层之后采用了 Maxpooling。除了最后一层 conv5,ReLU 非线性跟随每个卷积层。在训练期间,在每个线性层之后立即插入批量归一化 [24]。最终表示的步幅为 8。设计的一个重要方面是在网络中没有引入填充。虽然这是图像分类中的常见做法,但它违反了等式 1 的全卷积性质。
跟踪算法 由于我们的目的是证明全卷积孪生网络在 ImageNet Video 上训练时的有效性及其泛化能力,因此我们使用极其简单的算法来执行跟踪。与更复杂的跟踪器不同,我们不更新模型或保留过去外观的记忆,不包含额外的线索,例如光流或颜色直方图,不使用边界框回归来改进我们的预测。然而,尽管它很简单,但当配备我们的离线学习相似度度量时,跟踪算法取得了令人惊讶的好结果。
在线上,我们确实结合了一些基本的时间约束:我们只在大约是其先前大小的四倍的区域内搜索目标,并且在分数图中添加了一个余弦窗口以惩罚大位移。通过处理搜索图像的几个缩放版本来实现通过比例空间的跟踪。任何比例的变化都会受到惩罚,并且当前比例的更新会受到抑制。
3 Related work
最近的几项工作试图训练递归神经网络 (RNN) 以解决目标跟踪问题。[25] 训练一个 RNN 来预测目标在每一帧中的绝对位置,[26] 类似地使用可微分注意机制训练 RNN 进行跟踪。这些方法尚未在现代基准测试中显示出具有竞争力的结果,但它无疑是未来研究的一个有希望的途径。我们注意到,通过将 Siamese 网络解释为在长度为 2 的序列上训练和评估的展开 RNN,可以在这种方法和我们的方法之间得出一个有趣的相似之处。因此,孪生网络可以作为循环模型的强初始化。
[27] 使用粒子滤波器跟踪目标,该粒子滤波器使用学习的距离度量将当前外观与第一帧的外观进行比较。然而,他们的距离度量与我们的大不相同。他们不是比较整个目标的图像,而是计算注视点 (fixations) 之间的距离(目标边界框中小区域的注视点)。为了学习距离度量,他们训练了受限玻尔兹曼机 (RBM),然后使用隐藏激活之间的欧几里德距离进行两个注视。尽管 RBM 是无监督的,但他们建议在要检测的目标的中心图像内对 RBM 进行随机注视训练。这必须在线执行或在知道要跟踪的目标的离线阶段执行。在追踪物体时,他们学习了一种随机策略来选择特定于该目标的注视,使用不确定性作为奖励信号。除了 MNIST 数字的合成序列外,这种方法仅在人脸和人跟踪问题上得到了定性证明。
虽然为每个新视频从头开始训练DCNN是不可行的,但有几项工作已经研究了在测试时从预训练参数进行微调的可行性。 SO-DLT [7] 和 MDNet [9] 都在离线阶段为类似的检测任务训练卷积网络,然后在测试时使用 SGD 来学习检测器,该检测器具有从视频本身中提取的示例,如在传统跟踪中一样作为检测器学习范式。由于在许多示例上评估前向和后向传递的计算负担,这些方法不能以帧速率运行。利用卷积网络进行跟踪的另一种方法是应用传统的浅层方法,使用预训练卷积网络的内部表示作为特征。而这种风格的跟踪器,如 DeepSRDCF [6],[5] 和 FCNT [8] 取得了很好的成绩,但由于卷积网络表示的维度相对较高,它们一直无法实现帧率操作。
在我们自己的工作的同时,其他一些作者也提出了通过学习成对图像的函数来使用卷积网络进行目标跟踪。
-
[28] 介绍了 GOTURN,其中训练一个卷积网络直接从两个图像回归到第一张图像中显示的目标的第二张图像中的位置。预测矩形而不是位置的优点是可以处理比例和纵横比的变化,而无需进行详尽的评估。然而,他们的方法的一个缺点是它不具备平移第二张图像的内在不变性。这意味着必须在所有位置向网络展示示例,这是通过大量数据集扩充来实现的。
-
[29] 训练一个将样本和更大的搜索区域映射到响应图的网络。然而,由于最后的层是全连接的,他们的方法也缺乏对第二张图像平移的不变性。与 Held 等人类似,这是低效的,因为训练集必须代表所有目标的所有翻译。他们的方法因网络的 Y 形状而被命名为 YCNN。与我们的方法不同,它们不能在训练后动态调整搜索区域的大小。
-
[30] 建议训练一个 Siamese 网络来识别与初始目标外观匹配的候选图像位置,将他们的方法称为 SINT(Siamese INstance search Tracker)。与我们的方法相比,它们没有采用与搜索图像完全卷积的架构。相反,在测试时,他们在不同半径的圆上均匀地对边界框进行采样,如 Struck [3]。此外,它们结合了光流和边界框回归来改进结果。为了提高系统的计算速度,他们使用感兴趣区域 (RoI) 池化来有效地检查许多重叠的子窗口。尽管进行了这种优化,但在每秒 2 帧的情况下,整个系统仍远非实时。
以上所有在视频序列上训练的竞争方法(MDNet [9]、SINT [30]、GOTURN [28])都使用属于基准测试使用的相同 ALOV/OTB/VOT 域的训练数据。由于担心过度拟合基准中的场景和目标,这种做法在 VOT 挑战中被禁止。因此,我们工作的一个重要贡献是证明可以训练卷积网络以进行有效的目标跟踪,而无需使用与测试集相同分布的视频。
4 Experiments
4.1 Implementation details
训练。嵌入函数的参数是通过最小化 eq 来找到的。 5 使用 MatConvNet [31] 直接使用 SGD。参数的初始值遵循高斯分布,根据改进的 Xavier 方法 [32] 进行缩放。训练在 50 个 epoch 上进行,每个 epoch 包含 50,000 个采样对(根据 2.2 节)。使用大小为 8 的小批量估计每次迭代的梯度,并且学习率在每个 epoch 从 10-2 到 10-5 进行几何退火。
追踪。如前所述,在线阶段故意极简主义。初始目标外观的嵌入 φ(z) 计算一次,并与后续帧的子窗口进行卷积比较。我们发现通过简单的策略(例如线性插值)在线更新(特征表示)样本不会获得太多性能,因此我们将其保持不变。我们发现使用双三次插值对分数图进行上采样,从 17 × 17 到 272 × 272,由于原始图相对粗糙,因此定位更准确。为了处理尺度变化,我们还在五个尺度 1.025{−2,−1,0,1,2} 上搜索目标,并通过系数为 0.35 的线性插值更新尺度以提供阻尼。
为了使我们的实验结果具有可重复性,我们在 http://www.robots.ox.ac.uk/~luca/siamese-fc.html 上共享训练和跟踪代码以及生成精选数据集的脚本。在配备单个 NVIDIA GeForce GTX Titan X 和 4.0GHz 的 Intel Core i7-4790K 的机器上,我们的完整在线跟踪管道以每秒 86 和 58 帧的速度运行,分别在 3 和 5 个尺度上进行搜索。
4.2 Evaluation
我们评估了我们的简单跟踪器的两个变体:SiamFC(Siamese FullyConvolutional)和 SiamFC-3s,它搜索 3 个尺度而不是 5 个尺度。
4.3 The OTB-13 benchmark
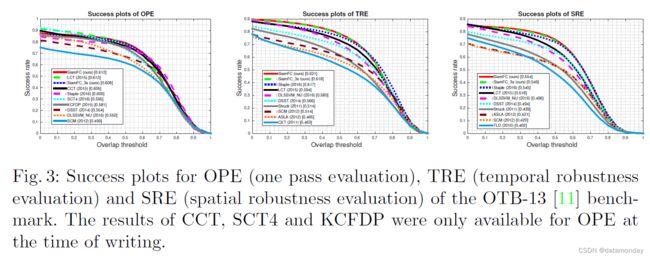
OTB-13 [11] 基准考虑了不同阈值下的平均每帧成功率:如果跟踪器的估计值与真实值之间的交并比 (IoU) 高于某个阈值,则跟踪器在给定帧中是成功的。然后根据该阈值的不同值的成功率曲线下面积来比较跟踪器。除了 [11] 报告的跟踪器之外,在图 3 中,我们还与主要计算机视觉会议上提出的另外七个最新的最先进的跟踪器进行了比较,它们可以以帧速率运行:Staple [33] 、LCT [34]、CCT [35]、SCT4 [36]、DLSSVM NU [37]、DSST [38] 和 KCFDP [39]。鉴于序列的性质,仅对于这个基准,我们在训练期间将 25% 的对转换为灰度。所有其他超参数(用于训练和跟踪)都是固定的。
4.4 The VOT benchmarks
对于我们的实验,我们使用最新稳定版本的视觉目标跟踪 (VOT) 工具包 (tag vot2015-final),它评估从 356 个序列中选择的序列的跟踪器,以便很好地代表七种不同的具有挑战性的情况。许多序列最初出现在其他数据集中(例如 ALOV [1] 和 OTB [11])。在基准测试中,跟踪器在失败后 5 帧自动重新初始化,当估计的边界框和地面实况之间的 IoU 变为零时,这被认为已经发生。
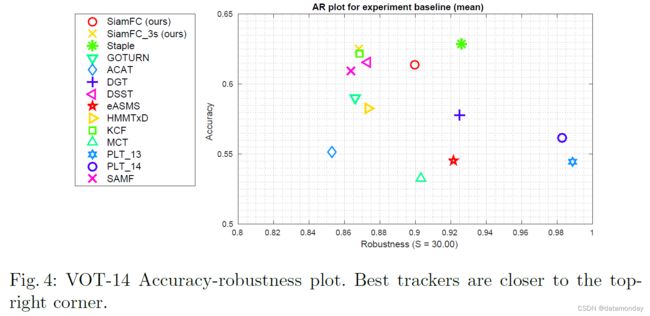
VOT-14 结果。我们将我们的方法 SiamFC(和变体 SiamFC3s)与参加 2014 年版 VOT 挑战的 10 个最佳跟踪器进行比较 [40]。我们还包括 Staple [33] 和 GOTURN [28],这两个最近的实时跟踪器分别在 CVPR 2016 和 ECCV 2016 上展示。跟踪器根据两个性能指标进行评估:准确性和鲁棒性。前者以平均 IoU 计算,而后者以失败总数表示。这些可以深入了解跟踪器的行为。图 4 显示了准确度-鲁棒性图,其中最佳跟踪器更靠近右上角。
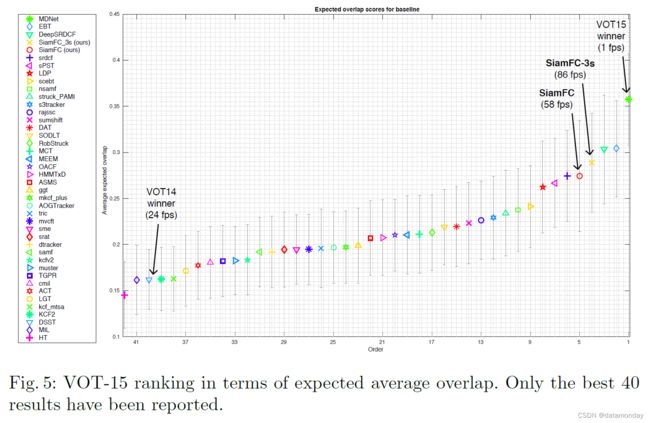
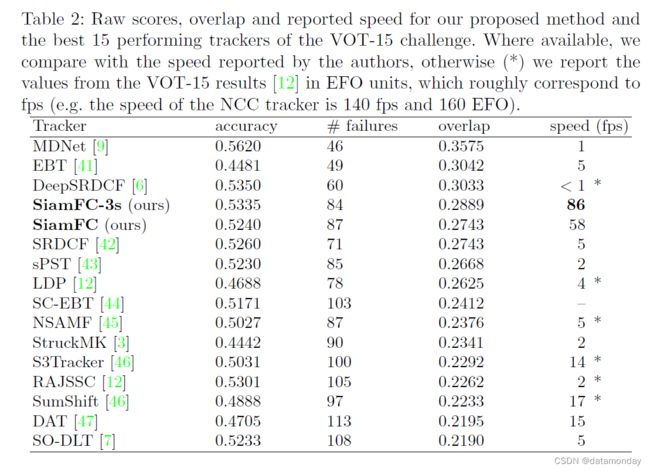
VOT-15 结果。我们还将我们的方法与 2015 年版 [12] 中的 40 名最佳参与者进行了比较。在这种情况下,使用准确度和失败次数的原始分数来计算预期的平均重叠度量,它表示在失败后没有重新初始化的平均 IoU。图 5 说明了预期平均重叠的最终排名,而表 2 报告了挑战中排名最高的 15 个跟踪器的分数和速度。
VOT-16 结果。在撰写本文时,还没有 2016 年版的结果。然而,为了便于与我们的方法进行早期比较,我们报告了我们的分数。对于 SiamFC 和 SiamFC-3,我们分别获得了 0.3876 和 0.4051 的总体预期重叠(基线和无监督实验之间的平均值)。请注意,这些结果与 VOT-16 报告不同,因为我们参与的挑战是这项工作的初步版本。
尽管它很简单,但我们的方法改进了最近最先进的实时跟踪器(图 3 和图 4)。此外,它在具有挑战性的 VOT-15 基准测试中优于大多数最佳方法,同时是唯一一种实现帧速率速度的方法(图 5 和表 2)。这些结果表明,我们的全卷积 Siamese 网络仅在 ImageNet Video 上学习到的相似性度量的表达能力就足以获得非常强大的结果,与最近的最先进方法相当或更好,这些方法通常是几个数量级幅度较慢。我们相信,通过使用跟踪社区经常采用的方法(例如模型更新、边界框回归、微调、内存)来增强极简在线跟踪管道,可以获得相当高的性能。
4.5 Dataset size
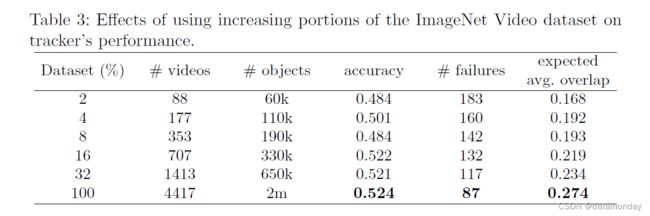
表 3 说明了用于训练孪生网络的数据集大小如何极大地影响性能。当数据集的大小从 5% 增加到 100% 时,预期的平均重叠(在 VOT-15 上测量)从 0.168 稳步提高到 0.274。这一发现表明,使用更大的视频数据集可以进一步提高性能。事实上,即使 200 万个监督边界框看起来是一个巨大的数字,但不应忘记它们仍然属于相对适中的视频数量,至少与通常用于训练卷积网络的数据量相比。
5 Conclusion
在这项工作中,我们脱离了用于跟踪的传统在线学习方法,并展示了一种替代方法,该方法专注于在离线阶段学习强嵌入。与它们在分类设置中的使用不同,我们证明了对于跟踪应用,Siamese 全卷积深度网络能够更有效地使用可用数据。这既反映在测试时,通过执行有效的空间搜索,也反映在训练时,每个子窗口有效地代表一个有用的样本,几乎没有额外的成本。实验表明,深度嵌入为在线跟踪器提供了自然丰富的特征来源,并使简单的测试时间策略能够很好地执行。我们相信这种方法是对更复杂的在线跟踪方法的补充,并期望未来的工作能够更彻底地探索这种关系。
图 6:第 2.4 节中描述的简单跟踪器的快照,配备了我们提出的在 ImageNet Video 上从头开始训练的全卷积孪生网络。我们的方法不执行任何模型更新,因此它仅使用第一帧来计算 φ(z)。尽管如此,它对于运动模糊(第 2 行)、外观的剧烈变化(第 1、3 和 4 行)、光照不足(第 6 行)和尺度变化(第 6 行)等许多具有挑战性的情况都具有惊人的鲁棒性。另一方面,我们的方法对混乱的场景(第 5 行)很敏感,可以说是因为模型从不更新,因此互相关对与目标第一次出现相似的所有窗口都给出了高分。所有序列均来自 VOT-15 基准:gymnastics1, car1, fish3, iceskater1, marching, singer1。快照是在固定帧(1、50、100 和 200)处拍摄的,并且永远不会重新初始化跟踪器。