python之pandas库详解
pandas 是一个 Python Data Analysis Library.在使用前 import pandas as pd
一.创建对象(产生数据)
pandas 中有三种基本结构:
Series:1D labeled homogeneously-typed array
DataFrame:General 2D labeled, size-mutable tabular structure with potentially heterogeneously-typed columns
Panel:General 3D labeled, also size-mutable array
1.Series
Series 是一维带标记的数组结构,可以存储任意类型的数据(整数,浮点数,字符串,Python 对象等等)。
作为一维结构,它的索引叫做 index,基本调用方法为s = pd.Series(data, index=index)。
data 可以是以下结构:
- 字典
ndarray- 标量
(1)字典:如果 data 是个 dict,如果不给定 index,那么 index 将使用 dict 的 key 排序之后的结果,如果给定了 index,那么将会按照 index 给定的值作为 key 从字典中读取相应的 value,如果 key 不存在,对应的值为 NaN(not a number, Pandas 中的缺失默认值)
d = {'a' : 0., 'b' : 1., 'c' : 2.}
pd.Series(d)(2)ndarray
或者list
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
s = pd.Series([1,3,5,np.nan,6,8])
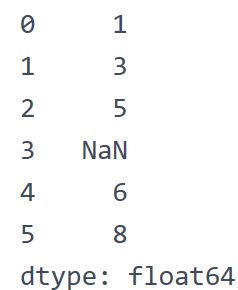
(3)从标量值构造:
pd.Series(5., index=['a', 'b', 'c', 'd', 'e'])2.DataFrame
通过传递一个 numpy array ,时间索引以及列标签来创建一个 DataFrame ,DataFrame 值要求每一列数据的格式相同
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))

除了向 DataFrame 中传入二维数组,我们也可以使用字典传入数据,字典的每个 key 代表一列,其 value 可以是各种能够转化为 Series 的对象:
df2 = pd.DataFrame({'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })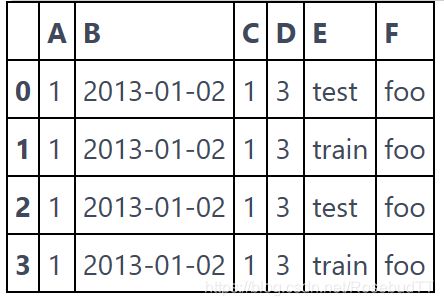
二.查看数据
1.头尾数据
head 和 tail 方法可以分别查看最前面几行和最后面几行的数据(默认为 5):
df.head()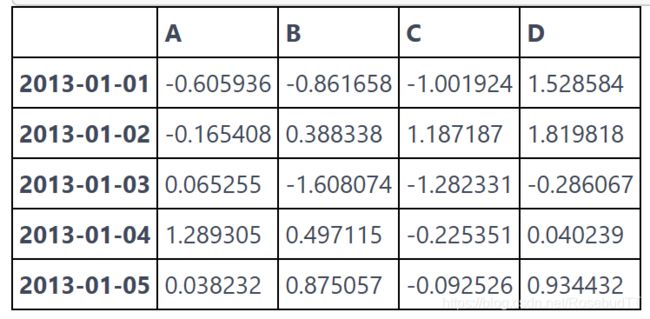
df.tail(3)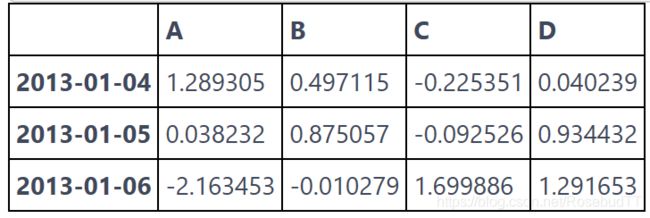
2.下标,列表,数据
df.index #下标使用 index 属性查看
df.columns #列标使用 columns 属性查看
df.values #数据值使用 values 查看DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D')
Index([u'A', u'B', u'C', u'D'], dtype='object')
array([[-0.60593585, -0.86165752, -1.00192387, 1.52858443], [-0.16540784, 0.38833783, 1.18718697, 1.81981793], [ 0.06525454, -1.60807414, -1.2823306 , -0.28606716], [ 1.28930486, 0.49711531, -0.22535143, 0.04023897], [ 0.03823179, 0.87505664, -0.0925258 , 0.93443212], [-2.16345271, -0.01027865, 1.69988608, 1.29165337]])
3.统计数据
df.describe() #查看简单的统计数据
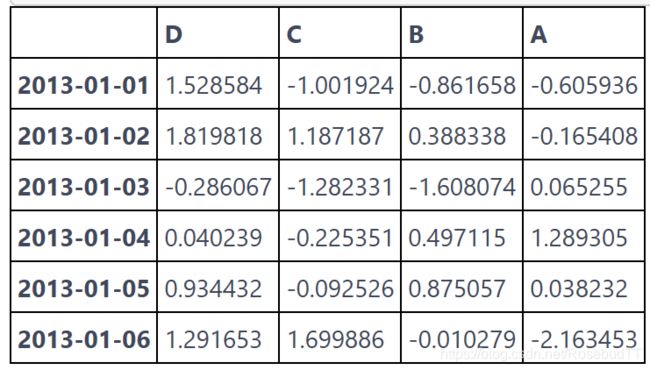
df.T #转置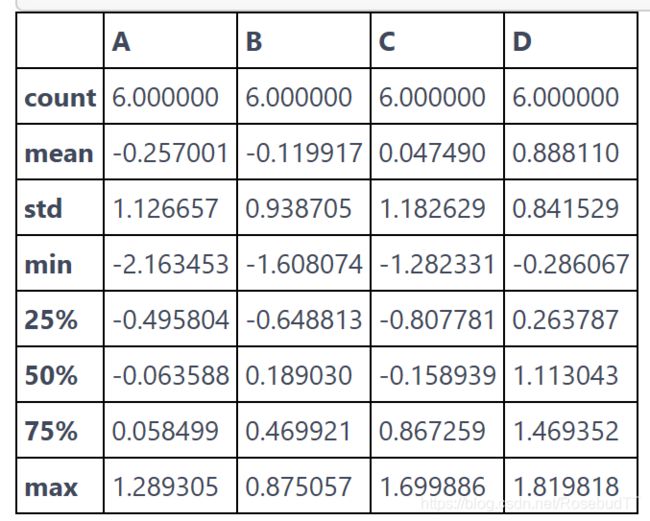

排序:
sort_index(axis=0, ascending=True) 方法按照下标大小进行排序
df.sort_index(ascending=False)
df.sort_index(axis=1, ascending=False)

sort_values(by, axis=0, ascending=True) 方法按照 by 的值的大小进行排序
df.sort_values(by="B")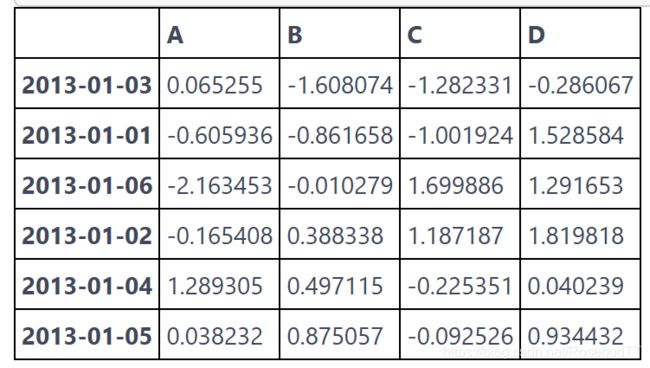
三.数据选择
虽然 DataFrame 支持 Python/Numpy 的索引语法,但是推荐使用 .at, .iat, .loc, .iloc 和 .ix 方法进行索引
df["A"]
#df.A
1.使用切片:
df[0:3]
#index 名字也可以进行切片
#df["20130101":"20130103"]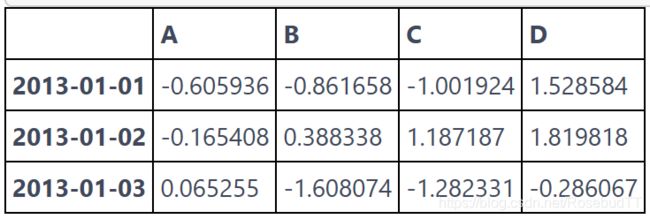
2.使用 label 索引:loc 可以方便的使用 label 进行索引
df.loc[:,['A','B']]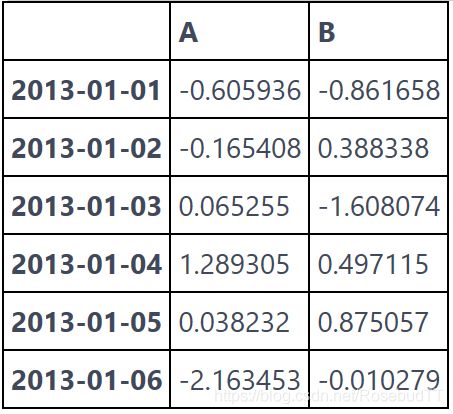
得到标量值可以用 at,速度更快:
df.at[dates[0],'B']-0.861657519028
3.使用位置索引
df.iloc[3]
df.iloc[[1,2,4],[0,2]] #索引不连续的部分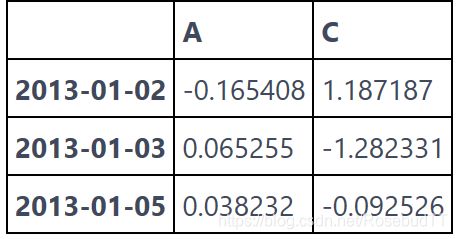
使用 iat 索引标量值更快
4.布尔型索引
df[df > 0]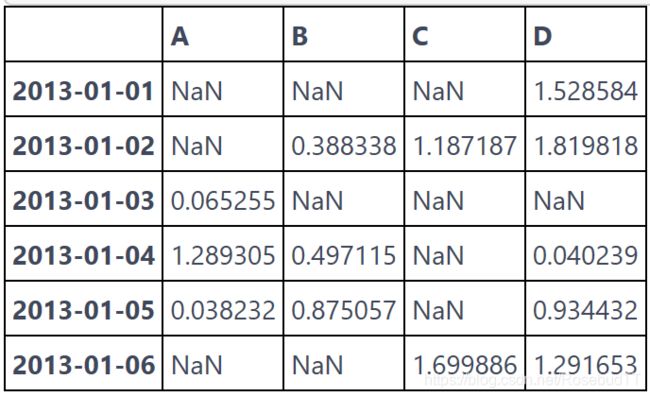
使用 isin 方法做 filter 过滤:
df2 = df.copy()
df2['E'] = ['one', 'one','two','three','four','three']
df2[df2['E'].isin(['two','four'])]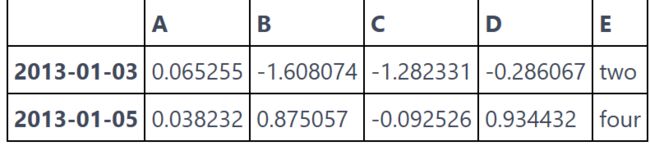
四.数据缺失
在 pandas 中,使用 np.nan 来代替缺失值,这些值将默认不会包含在计算中
1、 reindex() 方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝:
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1],'E'] = 1
2、 去掉包含缺失值的行:
df1.dropna(how='any')
3.对缺失值进行填充:
df1.fillna(value=5)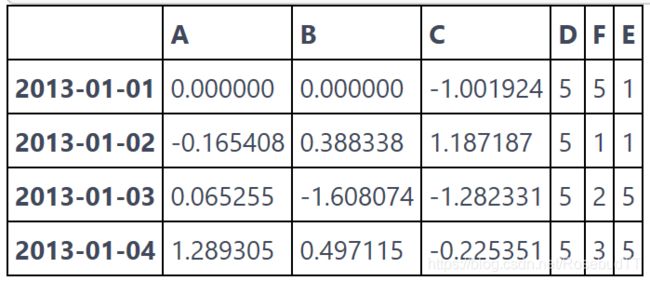
4.对数据进行布尔填充:
pd.isnull(df1)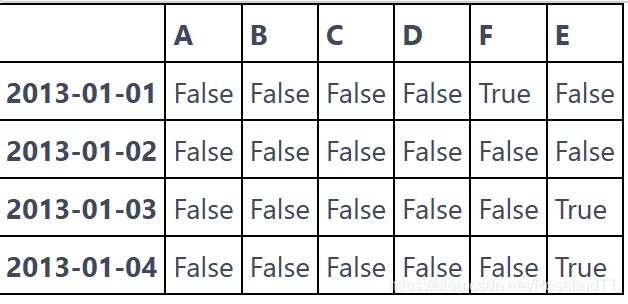
五.计算与合并
df.mean() #每一列的均值
df.mean(1) #每一行的均值多个对象之间的操作,如果维度不对,pandas 会自动调用 broadcasting 机制
apply 操作,与 R 中的 apply 操作类似,接收一个函数,默认是对将函数作用到每一列上
s = pd.Series(np.random.randint(0, 7, size=10))
print s
print s.value_counts()
h = s.hist()

合并:可以使用 pd.concat 函数将多个 pandas 对象进行连接
pieces = [df[:2], df[4:5], df[7:]]
pd.concat(pieces)merge 可以实现数据库中的 join 操作:
left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]})
right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]})

pd.merge(left, right, on='key')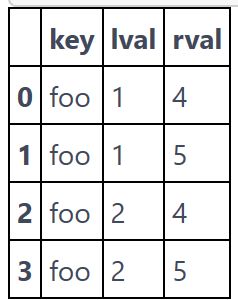
改变形状,产生一个多 index 的 DataFrame:
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])

时间序列
Pandas 在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见
rng = pd.date_range('3/6/2012 00:00', periods=5, freq='D')
ts = pd.Series(np.random.randn(len(rng)), rng)
#标准时间表示
ts_utc = ts.tz_localize('UTC')
#改变时区表示
ts_utc.tz_convert('US/Eastern')
六.Categoricals
pandas 可以在 DataFrame 中支持 Categorical 类型的数据
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
1.将原始的 grade 转换为 Categorical 数据类型:
df["grade"] = df["raw_grade"].astype("category")2. 将 Categorical 类型数据重命名为更有意义的名称:
df["grade"].cat.categories = ["very good", "good", "very bad"]3.对类别进行重新排序,增加缺失的类别:
df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"])4.排序是按照 Categorical 的顺序进行的而不是按照字典顺序进行:
df.sort_values(by="grade")5.对 Categorical 列进行排序时存在空的类别:
df.groupby("grade").size()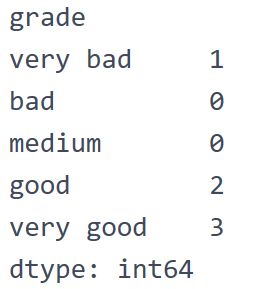
七.文件读写
csv
#写入文件
df.to_csv('foo.csv')
#从文件中读取
pd.read_csv('foo.csv').head()hdf5
#写入文件
df.to_hdf("foo.h5", "df")
#从文件中读取
pd.read_hdf('foo.h5','df').head()excel
#写入文件
df.to_excel('foo.xlsx', sheet_name='Sheet1')
#从文件读取
pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA']).head()清理生成的临时文件:
import glob
import os
for f in glob.glob("foo*"):
os.remove(f)