微软研究院:如何在机器学习的框架里实现隐私保护?
编者按:数据时代,人们从技术中获取便利的同时,也面临着隐私泄露的风险。微软倡导负责任的人工智能,因此机器学习中的隐私保护问题至关重要。本文介绍了目前机器学习中隐私保护领域的最新研究进展,讨论了机密计算、模型隐私和联邦学习等不同层面的隐私保护方法。
在大数据和人工智能的时代,人们能够更方便高效地获取信息。然而在获得便利的同时,我们的行为无时无刻不在被记录、被学习、被使用。如果在应用中不注重隐私保护,就很难阻止个人信息被用于非法目的。近年来,越来越多的人开始重视数据隐私,在选择使用客户端软件(App)时更加关注隐私条款。有研究表明,对于隐私的保护可以提高用户的使用率[1]。
此外,在法律层面,欧盟《通用数据保护条例》(GDPR)规范了企业收集、管理、删除客户和个人数据,中国也在保护隐私方面完善了法律法规。我们时常能看到某公司因为用户数据隐私不合规被处罚的新闻。
图1:GDPR 罚款漫画(引自 coredna.com)
然而,没有数据,机器学习就如无米之炊。随着研究的发展,机器学习的模型变得越来越强,需要的训练数据也大大增加,比如,业界有些训练模型需要使用上百 G 的数据来训练数十亿的参数。而在很多专业领域如医疗、金融防欺诈等,数据则因为隐私或者利益被分割成孤岛,使得机器学习面临着有效数据不足的问题。因此,如果不能对数据隐私提供保证,那么信息流动和机器学习也无法实现。
数据保护和机器学习似乎有着天然的矛盾, 因此,用户和服务提供商都面临的一个挑战是如何在机器学习的框架里实现隐私保护,取得隐私和效益的平衡。
隐私一词在不同场景下指代的意义会有较大差别,在机器学习中亦是如此。接下来我们将分三节分别介绍不同层面的隐私保护(如图2)。具体来说,第一部分陈述机密计算,讨论如何实现机器学习中计算的机密性;第二部分陈述模型的隐私,差分隐私以及机器遗忘,讨论如何减少机器学习模型对数据的泄露;第三部分陈述分布式机器学习的隐私,即联邦学习,讨论在数据隔离分布式存储,如何利用机密计算和模型隐私的技术有效地进行隐私保护的机器学习。
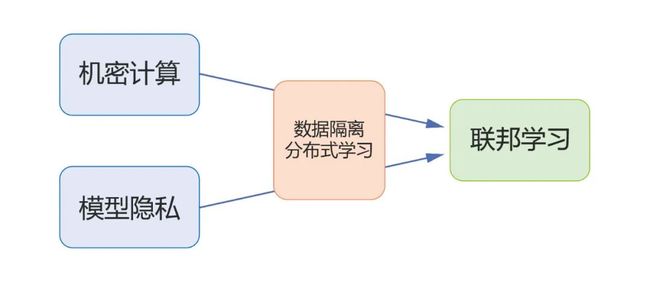
图2:本文结构示意图

第一章 机密计算
(Confidential computing)
机密计算(confidential computing)是指数据的传输和计算过程是机密的(confidential)。当前实现机密计算的方法有可信执行环境(Trusted Executive Environment, TEE),同态加密(Homomorphic Encryption, HE)和多方安全计算(Multi-party Secure Computation, MPC)。
可信执行环境(TEE)是处理器或虚拟系统上一个安全区域,可以保证在其中加载的数据和代码的机密性和完整性。简言之,TEE 可以被认为是认证用户在云端的一块飞地(enclave, 包括计算和存储资源),虽然物理上在云端,但逻辑上只受认证用户管辖。数据和可信程序在云端加密存储,只有在加载到 TEE 后才会解密,计算,计算结果再加密存储到云端。云端只负责提供可信的计算环境,对其中的计算无法干预。关于 TEE,硬件或者逻辑漏洞以及可扩展性是现在研究的重点。

图3:TEE 实现方案
同态加密,是一种加密方法,可以在密文上计算而不需要密钥,而且计算结果是机密的,需要使用密钥才能解密成明文。一般地,同态加密算法仅实现了同态加法和同态乘法,因此需要把计算归约成一个数域上的加法和乘法电路。例如为了实现在神经网络上的同态加密计算,需要对网络做一些改动使得其只包含加法乘法和多项式运算操作:把 ReLU 换成多项式激活函数,运算使用定点数等,来自微软研究院的 SEAL 项目[2]是目前比较流行的相关开源项目。但同态加密的实际应用还面临很大困难,由于它只能进行加法和乘法操作,相比于明文运算增加了相当大的计算开销,所以现在的技术大约只能扩展到 MNIST 和 CIFAR 的推断部分[3]。
多方安全计算是参与方以各自隐私数据为输入共同计算一个函数值。在整个过程中,各参与方除了计算结果,对他方的隐私数据没有额外的认知。多方安全计算能够同时确保输入的机密性和计算的正确性,其思想本质是输入数据是计算结果的一种冗余表示,有(无穷)多种输入样例对应相同的计算结果,因此引入随机数来掩盖这种冗余性从而实现机密计算。多方安全计算需要设计协议来实现加法和乘法操作,但它的瓶颈在于通信复杂度的提升[4],如广泛应用的 Beaver 协议对于每个乘法操作需要一轮通信开销。当前开源项目 Facebook CrypTen [5]和 Openminded PySyft [6] 用 Python 实现了多方安全计算的协议,可以进行如数据分离,数据模型分离等场景下的模型训练和推断。当前的研究热点是如何设计协议,降低通信开销,以及如何连接应用场景和技术实现。

表1:机密计算技术特征
表1总结了三种机密计算技术的特征。机器学习研究者尝试着把这些机密计算的技术和机器学习的过程结合实现对计算过程隐私的保护,以及使用它们来降低模型差分隐私所需要的噪音[7]。
第二章 模型的隐私
(Model privacy)
机密计算可以做到在训练过程中保护数据的隐私。那么训练后的模型会造成隐私训练数据的泄露吗?答案是可能的,因为机器学习的模型都会在一定程度上过拟合(泛化鸿沟),模型自身会记住(部分)训练数据,从而导致发布模型会造成隐私训练数据的泄露。一个例子是模型反向工程(model inversion, 从模型推断训练数据)[8] ,如图4就是攻击者只用姓名和人脸识别系统的黑盒(blackbox)访问恢复出的训练集中的数据。另一个例子是成员推断(membership inference),它推断某个样本是不是在训练集中,较高的成员推断成功率显示模型对训练数据的隐私有泄露[9]。

图4:从人脸识别模型通过黑盒攻击恢复出训练集中的数据,其中左图为攻击推断结果,右图为真实图像[8]
差分隐私(Differential Privacy, DP) 可以衡量和控制模型对训练数据的泄露。它从统计意义上刻画了单个数据样本对模型的影响。一个随机算法 M 符合 (ϵ,δ)-DP 意味着对于任何两个相邻的数据集 S, S' 和任意事件 E 满足
P(M(S)∈E))≤e^ϵ P(M(S' )∈E)+δ. (1)
实现算法差分隐私的一种通用做法是加噪音。加噪音会带来模型的性能损失,差分隐私机器学习(differential private machine learning) 就是研究如何更节省地加噪音,如何在给定隐私损失的要求下,加最少的噪音取得最好的性能。微软和中山大学在这方面的论文介绍了相关的研究工作[10]。研究人员发现加入的噪音和优化算法会相互影响:噪音会让优化算法避开最差曲率方向,优化算法的收缩性可以弱化之前步骤加的噪音。他们在分析中利用这种相互影响,推导出了一个新的基于期望曲率的理论性能界,可以显式地看出梯度扰动比另外两种扰动方式(目标扰动和输出扰动)的优势,并且给出了另外两种扰动无法利用这种相互影响的原因。据此,梯度扰动是一种实现差分隐私机器学习的有效算法。
从2006年差分隐私被提出以来,隐私的度量也一直是这个领域很基础的一个问题,期间提出的概念包括 ϵ-DP、(ϵ,δ)-DP、Renyi-DP、(Truncated) Concentrated DP 等。隐私度量,顾名思义是要度量一个算法的隐私损失。(ϵ,δ)-DP 可以按照公式计算出一次统计查询对应的隐私损失 (ϵ,δ)。通常一个复杂算法可以看成多次统计查询的复合(composition)和采样(sampling) ,因此分析一个复杂算法的隐私损失需要计算复合和采样两种操作的隐私损失。2019年[11]提出的高斯差分隐私(gaussian differential privacy)对采样和复合都给出了一个紧估计,在隐私损失的统计上比之前的 moments accountant 技术更精准,从而在相同隐私预算下要加的噪音更小,取得的性能更好。
最近,另一个模型隐私的研究热点是模型遗忘(machine unlearning)。如果把实现差分隐私看成主动设计算法使得输出模型满足隐私要求,那么模型遗忘是一种被动解决模型隐私的方法。它旨在机器学习模型中实现用户的“被遗忘权利(the right to be forgotten)”。模型遗忘最直观的做法是在删除指定数据后的训练集上重新训练(retraining)这种做法的计算代价非常大,因此模型遗忘工作的主要目标是降低计算代价,一类方法是对训练好的模型进行后处理,使得模型遗忘算法的结果跟重新训练得到的模型是统计意义上近似不可区分的[12,13];另外一类方法是设计新的训练方法,降低重新训练的代价,这类方法通常将数据分成不同块, 每块数据单独训练一个子模型, 并汇总子模型的结果,这样删除一个数据点只需要重新训练一个子模型[14,15]。
第三章 联邦学习
(Federated learning)
联邦学习(federated learning)的愿景是在不共享数据的情形下进行多方联合机器学习,本质上是一种数据访问受限的分布式机器学习框架。
相比于经典的分布式机器学习,联邦学习的第一层受限是数据隔离——数据在各个终端不共享,不均衡,交互通信要尽量少。微软和 CMU 合作的论文介绍了这方面的工作[16]。研究人员分析了在数据隔离的限制下一类分布式方差缩减算法(Variance Reduced Methods, i.e.,SVRG,SARAPH,MIG)的理论性能。在最自然的分布式设置下(终端节点运算内循环,参数服务器运算外循环)取得线性收敛性(强凸目标函数),并且算法的时间复杂度对条件数的依赖取得目前理论上的最好结果。分布式方差缩减算法相比于分布式梯度下降,显著降低了通信开销并利于保护隐私。在分析中,研究人员引入了 restricted smoothness 衡量本地目标函数和全局目标函数之差的平滑性,结果显示 restricted smoothness 决定了算法的收敛性。并且当数据不平衡,restricted smoothness 较差时,引入差异正则项,保证算法可以收敛。表2列举了各个分布式算法的通信和计算复杂度比较(*标识文中的算法),可以看出文中的分析对最自然的分布式方差缩减算法给出了最优的结果。

表 2:分布式算法通信和计算复杂度比较
联邦学习的第二层受限是隐私保护。直觉上,只共享参数更新而不共享原始数据可以在一定程度上保护原始数据的隐私。不过,论文[17]指出在深度模型中共享单个样本的梯度可以泄露原始数据。他们提出梯度匹配(gradient matching)算法,利用给定输入在模型上的梯度可以相当准确地恢复出原始数据的输入和标签。图5展示了梯度匹配在 MNIST、SVHN、CIFAR、LFW 数据集上恢复输入的例子。虽然在复合多个样本点的梯度时,梯度匹配算法会失效,但这篇文章仍然展示了梯度对原始数据的暴露。通常,联邦学习的算法会使用前面介绍的机密计算的工具(同态加密或多方安全计算)来实现可证明的隐私保护[18,19],只是这些机密计算的方法会带来很大额外的计算和通信开销。

图5:攻击者从共享的梯度中恢复出原始数据,从上到下分别是 MNIST、CIFAR100、SVHN、LFW [17]
相比于同态加密完全在密文域学习和运算,是否存在一种数据弱加密方法,使得模型可以直接在其上训练、推断同时还能拥有一定的隐私保证呢?最近的工作 InstaHide[20],就利用 mixup[21] 和随机反转对原始图片弱加密。弱加密后的图片视觉上看不出原始图片的信息,但深度神经网络仍然可以直接在其上训练推断,取得了相当好的性能表现。此外,该工作还展示了这种弱加密算法可以抵抗多种攻击方法。不过值得指出的是这种弱加密还没有计算复杂性的理论,不能保证一定可以防住攻击。
隐私保护与人们的生活息息相关,在实践和理论上也是挑战和机遇并存。我们期待与更多同仁一起努力,推动隐私保护领域的发展。
参考资料:
[1] Hannah Alsdurf, et al. Covi white paper. arXiv276preprint arXiv:2005.08502, 2020
[2] https://github.com/Microsoft/SEAL
[3] Gilad-Bachrach, Ran, et al. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. ICML 2016.
[4] Wagh, Sameer, et al. SecureNN: 3-party secure computation for neural network training. Proceedings on Privacy Enhancing Technologies 2019.
[5] https://github.com/facebookresearch/CrypTen
[6] https://github.com/OpenMined/PySyft
[7] Jayaraman, Bargav, et al. Distributed learning without distress: Privacy-preserving empirical risk minimization. NeurIPS 2018
[8] Michael Backes, et al. Membership privacy in microRNA-based studies. CCS 2016.
[9] Yu, Da, et al. Gradient Perturbation is Underrated for Differentially Private Convex Optimization. IJCAI 2020.
[10] Dong, Jinshuo, Aaron Roth, and Weijie J. Su. Gaussian differential privacy. arXiv preprint arXiv:1905.02383 (2019).
[11] Guo, Chuan, et al. Certified Data Removal from Machine Learning Models, ICML 2020
[12] Golatkar, Aditya, et al. Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks, CVPR 2020
[13] Ginart, Antonio, et al. Making AI Forget You: Data Deletion in Machine Learning, NeurIPS 2019
[14] Bourtoule, Lucas, et al. Machine Unlearning, Security & Privacy 2020
[15] Fredrikson, Matt, et al. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures, CCS 2015
[16] Cen, Shicong, et al. Convergence of distributed stochastic variance reduced methods without sampling extra data. IEEE Transactions on Signal Processing (2020).
[17] Zhu, Ligeng, et al. Deep Leakage from Gradients, NeurIPS 2019
[18] Hardy, Stephen, et al. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv preprint arXiv:1711.10677 (2017).
[19] Yang, Qiang, et al. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST) 10.2 (2019): 1-19.
[20] Huang, Yangsibo, et al. InstaHide: Instance-hiding Schemes for Private Distributed Learning, ICML 2020.
[21] Zhang, Hongyi, et al. Mixup: Beyond Empirical Risk Minimization, ICLR 2018.
「 更多干货,更多收获 」
推荐系统有什么危害?ClickHouse在字节跳动广告DMP&CDP的应用
微信推荐系统应用实践2020腾讯人工智能白皮书.pdf(附下载链接)推荐系统解构.pdf(附40页PPT下载链接)全网最全数字化资料包【白岩松大学演讲】:为什么读书?强烈建议静下心来认真看完
关注我们
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注
|

您的「在看」,我的动力????