机器学习之逻辑回归算法笔记
逻辑回归是一种用于解决分类问题的机器学习方法。它是一种基于概率思想的预测分析技术。分类算法 Logistic 回归用于预测分类因变量的似然性。逻辑回归中的因变量是二进制变量,数据编码为 1(是、真、正常、成功等)或 0(否、假、异常、失败等)。
Logistic 回归的目标是发现特征与特定结果的可能性之间的联系。例如,当根据学习的小时数预测学生是否通过考试时,响应变量有两个值:通过和失败。
Logistic 回归模型类似于线性回归模型,不同之处在于 Logistic 回归使用更复杂的成本函数,称为“Sigmoid 函数”或“逻辑函数”而不是线性函数。关于线性回归要记住的一件事是它只适用于连续数据。
逻辑回归被认为是一种回归模型。该模型创建了一个回归模型来预测给定数据条目属于标记为“1”的类别的可能性。逻辑回归使用 sigmoid 函数对数据进行建模,就像线性回归假设数据服从线性分布一样。
Logit 函数到 Sigmoid 函数 - Logistic 回归:
逻辑回归可以表示为,
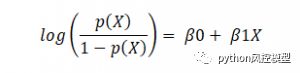
其中 p(x)/(1-p(x)) 称为赔率,左侧称为 logit 或 log-odds 函数。几率是成功几率与失败几率的比值。因此,在逻辑回归中,输入的线性组合被转换为 log(odds),输出为 1。
以下是上述函数的反函数
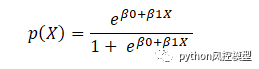
这是 Sigmoid 函数,它产生 S 形曲线。它总是返回一个介于 0 和 1 之间的概率值。Sigmoid 函数用于将期望值转换为概率。该函数将任何实数转换为 0 到 1 之间的数字。我们利用 sigmoid 将预测转换为机器学习中的概率。
大体上可以分为,
1. 二元逻辑回归——两个或二元结果,如是或否
2. 多项 Logistic 回归 - 三个或更多结果,如一等、二等和三等或无学位
3.序数逻辑回归——三个或更多类似于多项逻辑回归,但这里的顺序是超市中的顾客评分从 1 到 5
Logistic 回归正常工作的要求
该模型适用于所有数据集,但是,如果您需要良好的性能,则需要考虑一些假设,
1.二元逻辑回归中的因变量必须是二元的。
2. 只应包括相关的变量。
3. 自变量必须彼此无关。也就是说,模型中的多重共线性应该很小或没有。
4. 对数几率与自变量成正比。
5.逻辑回归需要大样本量。
线性回归使用最小二乘误差作为损失函数,这会产生一个凸网络,然后我们可以通过将顶点识别为全局最小值来优化它。然而,对于逻辑回归,它不再是可能的。由于假设已被修改,因此在原始模型输出上使用 sigmoid 函数计算最小二乘误差将导致具有局部最小值的非凸图。
什么是成本函数?机器学习中使用成本函数来估计模型的性能有多差。简单地说,成本函数是衡量模型在估计 X 和 y 之间的联系方面有多不准确的度量。这通常表示为预期值和实际值之间的差异或分离。机器学习模型的目标是发现参数、权重或最小化成本函数的结构。
正则化
让我们也快速讨论正则化以减少成本函数以将参数与训练数据匹配。L1 (Lasso) 和 L2 (Lasso) 是两种最常见的正则化类型 (Ridge)。正则化不是简单地最大化上述成本函数,而是对系数的大小施加限制以避免过度拟合。L1 和 L2 使用不同的方法来定义系数的上限,允许 L1 通过将系数设置为 0 来进行特征选择,以减少相关性较低的特征并减少多重共线性,而 L2 惩罚非常大的系数,但不会将任何系数设置为 0。还有调节约束权重 λ 的参数,以确保系数不会受到过于严厉的惩罚,从而导致欠拟合。
研究为什么 L1 和 L2 由于“平方”和“绝对”值而具有不同的容量,以及 λ 如何影响正则化和原始拟合项的权重,这是一个有趣的话题。我们不会在这里介绍所有内容,但值得您花时间和精力来了解。以下步骤演示了如何将原始成本函数转换为正则化成本函数。
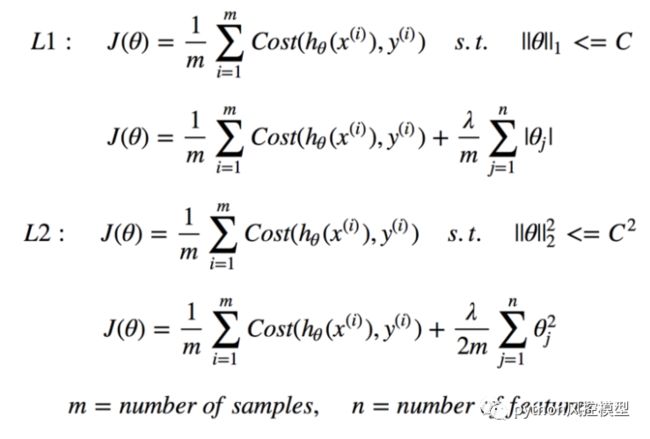
Logistic 回归与神经网络联系
我们都知道神经网络是深度学习的基础。最好的部分是逻辑回归与神经网络密切相关。网络中的每个神经元都可以被认为是一个逻辑回归;它包含输入、权重和偏差,在应用任何非线性函数之前,您需要对所有这些进行点积。此外,神经网络的最后一层是一个基本的线性模型(大部分时间)。这可以通过如下图所示的可视化来理解,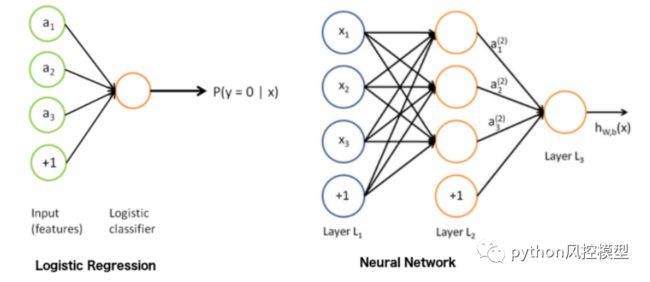
深入研究“输出层”,您会注意到它是一个基本的线性(或逻辑)回归:我们有输入(隐藏层 2)、权重、点积,最后是非线性功能,取决于任务。考虑神经网络的一种有用方法是将它们分为两部分:表示和分类/回归。第一部分(左侧)旨在开发一个体面的数据表示,这将有助于第二部分(右侧)进行线性分类/回归。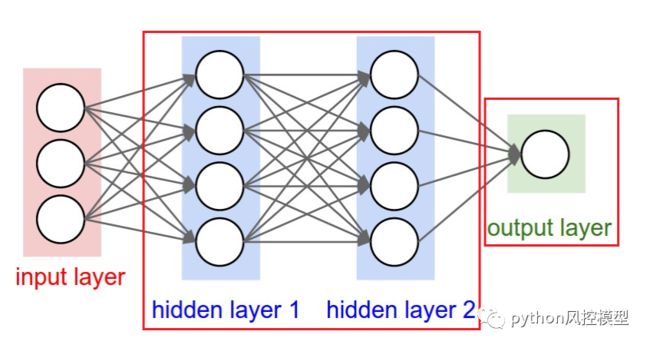
Logistic 回归的优点
1. 逻辑回归不太可能过度拟合,尽管它可能发生在高维数据集中。在这些情况下,可以使用正则化(L1 和 L2)技术来最小化过拟合。
2.当数据集线性可分时效果很好,对很多基础数据集都有很好的准确率。
3. 应用、理解和培训更直接。
4. 关于每个特征的相关性的推断是基于预期的参数(训练的权重)。协会的方向,积极的或消极的,也被指定。因此,可以使用逻辑回归来确定特征之间的联系。
5. 与决策树或支持向量机不同,该技术允许轻松更改模型以合并新数据。随机梯度下降可用于更新数据。
6. 在具有足够训练实例的低维数据集中不太容易过拟合。
7. 当数据集包含线性可分特征时,Logistic Regression 表现出非常高效。
8. 它与神经网络非常相似。神经网络表示可以被认为是堆叠在一起的小型逻辑回归分类器的集合。
9. 由于其简单的概率解释,逻辑回归方法的训练时间比大多数复杂算法(例如人工神经网络)的训练时间要小得多。
10. 多项 Logistic 回归是一种方法的名称,该方法可以使用 softmax 分类器轻松扩展到多类分类。
逻辑回归的缺点
1. 如果观察数少于特征数,则不应使用 Logistic 回归;否则,可能会导致过拟合。
2. 因为它创建了线性边界,所以在处理复杂或非线性数据时我们不会获得更好的结果。
3. 只对预测离散函数有用。因此,Logistic 回归因变量仅限于离散数集。
4.逻辑回归要求自变量之间存在平均或不存在多重共线性。
5. 逻辑回归需要一个大数据集和足够的训练样本来识别所有类别。
6. 由于此方法对异常值敏感,数据集中存在与预期范围不同的数据值可能会导致错误结果。
7. 仅应利用重要和相关的特征来构建模型;否则,模型的概率预测可能不准确,其预测值可能会受到影响。
8. 复杂的连接很难用逻辑回归表示。这种技术很容易被更强大和更复杂的算法(如神经网络)所超越。
9. 由于逻辑回归具有线性决策面,因此无法解决非线性问题。在现实世界中,线性可分的数据并不常见。因此,必须对非线性特征进行转换,这可以通过增加特征的数量来完成,以便数据可以在更高维度上线性分离。
10. 基于自变量,统计分析模型旨在预测准确的概率结果。在高维数据集上,这可能会导致模型在训练集上过度拟合,夸大训练集预测的准确性,从而阻止模型准确预测测试集上的结果。当模型在少量具有许多特征的训练数据上进行训练时,这是最常见的。应该在高维数据集上探索正则化策略,以最大限度地减少过度拟合(但这会使模型变得复杂)。如果正则化参数过高,模型可能在训练数据上欠拟合。
分类问题不用线性回归的原因:
对于分类问题,y 取值为0 或者1。
如果使用线性回归,那么线性回归模型的输出值可能远大于1,或者远小于0。
导致代价函数很大。
逻辑回归模型(S 形函数):
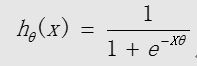
中间变量:
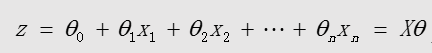
sigmoid函数的输出值永远在0 到1 之间:
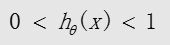
sigmoid函数的输出值永远在0 到1 之间:
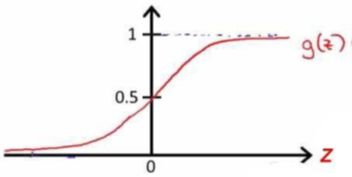
逻辑回归模型的概率解释:
对于给定的输入变量x,根据选择的参数θ,计算输出变量y=1 的可能性(estimated probability)即:
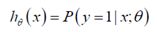
例如:如果对于给定的x,通过已经确定的参数计算得出hθ(x)=0.7,则表示有70%的几率y 为正向类,相应地y 为负向类的几率为1-0.7=0.3
逻辑回归的代价函数(交叉熵):
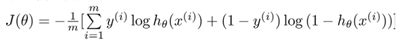
该代价函数J(θ)是一个凸函数,有全局最优值;
因为代价函数是凸函数,无论在哪里初始化,最终达到这个凸函数的最小值点。