下一个AI领域的高薪方向:强化学习与智能决策研究班2023年春季招生启事

世界繁花盛开 我们不必在同一个地方反复死磕
强化学习是最近5年来人工智能最令人激动的研究领域。如下图Google的搜索指数可以看到,强化学习的搜索指数最近一些年明显呈现增长趋势,而NLP(自然语言处理)和CV(计算机视觉)则相对呈现下降趋势。
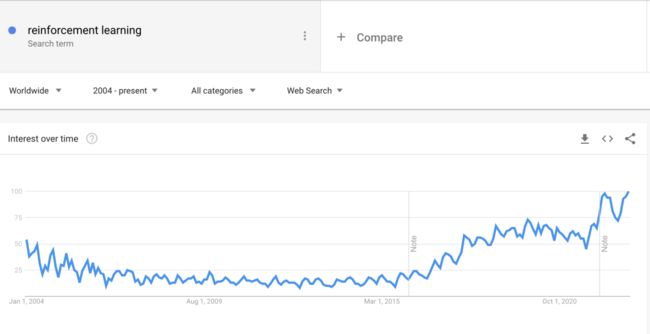
● 图1. Google全球搜索指数显示强化学习最近几年增长显著,数据截至2022年12月25日
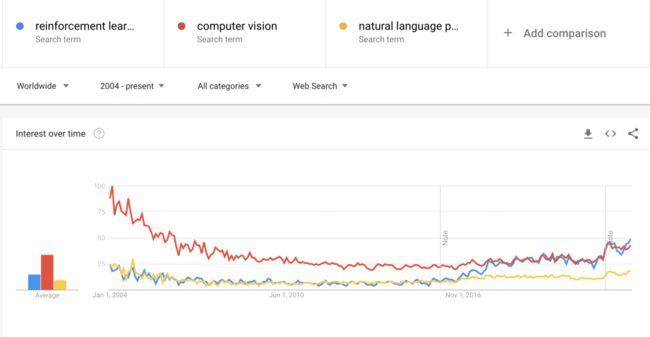
● 图2. Google全球搜索指数,AI主流领域趋势对比,数据截至2022年12月25日(蓝色为强化学习,红色为计算机视觉,黄色为NLP)
从2016年开始,AlphaGo走进了我们的视野,展现了强化学习(Reinforcement Learning)的威力,随后的日子里,AlphaStar在星际争霸战胜职业选手,AlphaFold解决蛋白质合成,ChatGPT展现出的强大内容合成能力,背后都离不开强化学习。
● 图3. AlphaStar星际争霸战胜职业选手
● 图4. AlphaFold探索、解析蛋白质结构
而在求职领域,强化学习目前更是广大公司急需的岗位,薪资更高,对于从业者的经验要求也更友好。例如,相比CV领域或者NLP领域动辄要求3年以上经验,由于强化学习是相对更新的领域,所以对于新入行的学习者接受度更高。

● 图5. 强化学习目前需求量大,薪资相对更高,最主要是对新人更加接纳(数据来自拉钩求职,数据截至2022年12.25日)
有别于深度学习,由于强化学习的研究领域非常广泛,不同的派别使用的方法也非常不同,这就给大家造成了非常庞大的学习负担,为此,我们特推出《强化学习与智能决策—一种现代方法》研修班,目的就是帮助大家拨开迷雾,让大家高效的穿越RL的知识森林。
我们的学习线路会是目前最主流的基于Policy Gradient的Offline-Learning,这就给大家减少了非常多的学习负担,并且能够更加专注。而且,我们全程是为了提升大家实际案例的解决能力,代码量大,非常务实。我们的目标是为大家带来严肃、前沿而又务实的强化学习内容!

● 自学强化学习往往面临资料过于繁复,无从下手,效率低下的问题
研修班特点
Key Features
● 最具竞争力的课程性价比,大幅度降低学习负担
● 世界杯赛制,让AI模型带你出战-冠亚季军可获得高额奖学金
● 梳理知识脉络,在庞大而复杂的强化学习体系中,更快地掌握能力
● 前世界名企数据科学家在线原理推导与在线编程
● 高频密集的在线问答与代码批阅让能力掌握在实处
● 双语教学助力学习者与前沿接轨
AI世界杯足球奖金
Award for AI Word Cup
为了提高大家的学习热情,我们将模拟世界杯赛制,在最终的结业项目中,每位同学的AI模型代表自己进行比赛,我们将模拟世界杯赛程,选出32强并且一直打到冠亚季军。
1 - 3名分别获得如下奖金:
● 冠军:9800元
● 亚军:6800元
● 季军:4800元
● 该图像为最终结业项目运行实例 -多智能体强化学习足球竞赛

● 模拟世界杯赛制,AI带你出战
该研修班面向人群
Target Learners
● 希望掌握或者从事强化学习相关工作的程序员、算法工程师、研究生
● 希望解决与智能决策类似相关问题的研究员、工程师、量化研究员
● 希望申请该领域研究生、博士生的相关学习者

扫码联系高老师助理
开启强化学习之旅
计划时长与上课方式
Timeline & Teaching
● 2023年1.14日-5.10日,为期20周,合计180课时
● 每周3课时直播研讨课,6课时在线答疑课
● 研讨课:基于腾讯会议,在线进行原理推理,代码原理展示
● 答疑课:主讲老师基于腾讯会议+code with me协同代码工具进行远程调试
授课老师介绍
Mentor
高民权,前IBM数据科学家。从事人工智能相关研究、企业落地多年。曾经作为技术负责人参与落地多个大中华区人工智能产业项目。其落地项目与研究领域包括:人工智能理论原理,计算语言,自然语言处理,社会网络计算,医学识别,新能源智能预测,硬件生产自动化等多个方向。从2021年开始重点从事强化学习相关研究工作,研究兴趣多智能体强化学习,表征学习与强化学习的结合,强化学习的稳定性与可解释性。2022 NeurIPS强化学习方向审稿人。
为期20周,每周时间安排
Agenda
● 周日至周五:每周6 - 12小时代码项目练习,课程组提供服务器及基础环境
● 周二:12:00 – 13:30 基于腾讯会议的导师在线答疑和在线debug
● 周三:12:00 – 13:30 基于腾讯会议的导师在线答疑和在线debug
● 周四:12:00 – 13:30 基于腾讯会议的导师在线答疑和在线debug
● 周五:12:00 – 13:30 基于腾讯会议的导师在线答疑和在线debug
● 周六:09:30 – 12:40 在线理论+实操课程,为两次1.5小时课程,中途休息10-15分钟
课程详细内容
Syllabus
本课程以项目驱动,我们最终交给大家的能力是能够高效运行成功复杂案例的能力。我们主要会带给大家4个项目加1个结业大项目。
● 项目I:基于蒙特卡洛方法的Mujoco机器人控制
● 该图片与课程项目一致
*注:该课程授课语言为汉语,但PPT,参考文章,资料,代码及作业均为英文。
Week-1: First-Step on RL, Monte-Carlo Methods, Gym 环境介绍,智能出租车问题解决
Week-2: Markov Decision Process, The Reinforcement Learning Framework and Paradigm
Week-3: Temporal-Difference Learning
Week-4: RL in infinite Space, Discrete on Observation
此阶段参考文献 | References,课程中会为大家讲解论文关键原理:
1. Richard S. Sutton and Andrew G. Barto, Reinforcement Learning – An Introduction, 2nd
2. Greg Brockman et al., OpenAI Gym, 2016
● 项目II:基于DeepQLearning的通过复杂游戏AI
● 该图片与课程项目一致
Week-5: Q-Learning and Q-Value Iteration
Week-6: From Q-Learning to DeepQ-Learning, Q-NeuralNetwork
Week-7: Experience Replay, Fixed-Target, DoubleQ-Learning, Dueling DeepQ-Learning
Week-8: QLearning Practice on Game and Robotics
此阶段参考文献 | References,课程中会为大家讲解论文关键原理:
1. Volodymyr Mnih1 et al., Human-level control through deep reinforcement learning, 2015
2.Hado van Hasselt el ai., Deep Reinforcement Learning with Double Q-learning, 2015
3.Ziyu Wang et al., Dueling Network Architectures for Deep Reinforcement Learning, 2016
● 项目III&IV:基于PolicyGradient的高频交易模型或高维度复杂机器人控制

● 该图片与课程项目一致
*注:该课程授课语言为汉语,但PPT,参考文章,资料,代码及作业均为英文。
Week-9: Policy Gradient, Implementation PG on PyTorch
Week-10: Proximal Policy Optimization(PPO), Trust Region Policy Optimization (TRPO)
Week-11: Actor-Critic Methods, GAE
Week-12: Continuous Controlling, Robotics Controlling
Week-13: Utility ML-Engine
此阶段参考文献 | References,课程中会为大家讲解论文关键原理:
1. Richard S. Sutton, et al., Policy Gradient Methods for Reinforcement Learning with Function Approximation
2. Sham Kakade, A Natural Policy Gradient
3. Volodymyr Mnih, et al., Asynchronous Methods for Deep Reinforcement Learning, 2016
4. John Schulman et al., Trust Region Policy Optimization, 2017
5. John Schulman et al., Proximal Policy Optimization Algorithms, 2017
6. John Schulman et al., HIGH-DIMENSIONAL CONTINUOUS CONTROL USING GENERALIZED ADVANTAGE ESTIMATION, 2018
7.Tuomas Haarnoja et al., Soft Actor-Critic Algorithms and Applications 2019
8.Timothy P. Lillicrap et al., CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING, 2019
● 结业项目:GoogleFootballPlayer足球多智能体竞赛
● 该图片与课程项目一致
*注:该课程授课语言为汉语,但PPT,参考文章,资料,代码及作业均为英文。
Week-14: GoogleFootball Player环境的配置,接口与案例分析
Week-15: The Lesson from AlphaGo and AlphaZero, Self-Play Learning
Week-16: Multi-Agent Learning, Markov Games, Cooperation, Competitive
Week-17: 迷你版AlphaZero小项目实战
Week-18: Central Training Decentric Execution, HAPPO, HATRPO
Week-19: 模型设计,调试,性能评估
Week-20: 赛区划分,32强选拔赛,32进16,16进8,8进4选拔赛
Week-21: 4强冠亚季军排名,颁奖仪式
此阶段参考文献 | References,课程中会为大家讲解论文关键原理:
1. David Silver, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, 2017
2. Karol Kurach et al., Google Research Football: A Novel Reinforcement Learning Environment, 2019
3. Jakub Grudzien Kuba et al., Trust Region Policy Optimisation in Multi-Agent Reinforcement Learning
4. Muning Wen et al., Multi-Agent Reinforcement Learning is a Sequence Modeling Problem, 2022
5次前沿研讨课
Advanced Topics
1. 大型预训练模型在RL中的应用,DecisionTransformer
研讨内容:Transformer在自然语言,计算机视觉等领域都取得了显著的影响。最近,研究者们尝试将Transformer等预训练模型机制融入到强化学习问题中,该研讨课程我们将为大家带来DecisionTransformer以及其他大规模训练模型在强化学习中的进展。
2. ChatGPT与HumanFeedback Refinforcement Learning
研讨内容:ChatGPT在2022年产生了巨大的影响,成为了人类有史以来100万注册用户最快的网络应用。ChatGPT的背后,不仅仅使用了大规模预训练模型,其HumanFeedback Reinforcement Learning机制同样产生了非常大的作用,并且给我们提供了一个创作型AI的良好范例,此次研讨课程我们将为大家带来ChatGPT与其背后的原理和机制。
3. Imitation Learning与机器人控制
研讨内容:机器人在真实环境下是无法像在虚拟环境中产生巨量的观察数据的,那么如何能够让真实的机器人快速学习复杂任务?Imitation Learning(模仿学习)是现在研究者们非常关注的领域,通过像人类学习一些特定的初试知识,通过知识的迁移和泛化,能够让机器人在复杂任务学习中更快的学习。此次研讨课程我们将会为大家带来Imitation Learning 的机制和最近进展。
4. Explainable and Trustable Reinforcement Learning
研讨内容:由于强化学习是用来解决决策问题(decision-making),所以,如果该问题属于比较重要,例如机器人、生产制造、金融投资等,若此时出现错误,基于目前的深度强化学习方法,我们是无法对其找到合理的原因,并且比较难避免再次发生相似问题。研究者们目前正在着手研究如何让强化学习模型更加可信赖,更加可解释,讲起用于更加严肃、严苛和重要的场景。本次研讨会我们将会为大家带来Explainable & Trustable RL的最新进展。
5. ICLR 2023及2023春强化学习进展选讲
研讨内容:我们将会以2023年ICLR论文公布为契机,为大家带来从2022年中旬到2023年春季这将近一年时间强化学习方面的最新进展。
学费
Tuition
● 班型1:RL在线研讨班
6000 RMB 或 850$
包含:
-
20周直播课程
20周直播在线答疑+debug
全部代码、课件、录播资料、参考资料权限
● 班型2:RL综合指导班
8000 RMB 或者 1100$
包含:
-
20周直播课程
20周直播在线答疑+debug
全部代码、课件、录播资料、参考资料权限
在线服务器
代码批阅
5次前沿研讨课程
注:往期学员可凭借往期学习记录减免1200元学费,老学员优惠后价格分别为4800元与6800元。
不满意退款保障权益
Insurance
● 1.15日-1.25日:发起退款后,3天内退还100%学费
● 1.25日- 2.02日:发起退款后,3天内退还75%学费
● 2.03日-2.10日:发起退款后,3天内退还50%学费
● 2.10日-2.17日:发起退款后,3天内退还25%学费
● 超过2.17日,退费期结束
学习背景要求
Requirements
此课程为高阶课程,所以我们对学习者较高要求,具体为:
1. 本科毕业2年以上工作经历或研究生学历;
2. 面临工作需求的在校研究生;
3. 计算机、软件工程、数学、物理、金融、生物等相关专业;
4. 能够使用Python解决常见问题;
5. 入学测试题正确率需高于70%(因课程内容前沿知识较多,入学测试为全英文)。
入学流程
Procedure
● 第一步:扫描下方二维码,添加研讨班小助理
● 第二步:通过腾讯问卷进行入学测试、信息填写
● 第三步:通过入学测试后,课程组向同学发送此次课程协议、具体学生权益以及付款方式
● 第四步:付费成功
● 第五步:添加导师联系方式,并且加入学习组
● 第六步:配置学习环境
● 第七步:正式开始上课

扫码联系高老师助理
开启强化学习之旅
这个世界繁花盛开,我们没有必要在同一个地方反复死磕。
朝着更新的方向迈进,那里充满更多机遇。
希望我们能再次相遇,开启新的明天。
更多问题
Connect & QA
若对课程有其他问题,请联系课程组。