李沐精读论文:DETR End to End Object Detection with Transformers
论文: End-to-End Object Detection with Transformers
代码:官方代码
Deformable DETR:论文 代码
视频:DETR 论文精读【论文精读】_哔哩哔哩_bilibili
本文参考:
山上的小酒馆的博客-CSDN博客
端到端目标检测DETR
DETR(DEtection TRansformer)是2020年5月发布在Arxiv上的一篇论文,可以说是近年来目标检测领域的一个里程碑式的工作。从论文题目就可以看出,DETR其最大创新点有两个:end-to-end(端到端)和 引入Transformer。
目标检测任务,一直都是比图片分类复杂很多,因为需要预测出图片中物体的位置和类别。以往的主流的目标检测方法都不是端到端的目标检测,不论proposal based的方法(R-CNN系列),anchor based 的方法(YOLO系列),还是non anchor based方法(利用角点/中心点定位),都会生成大大小小很多的预测框,需要nms(非极大值抑制)等后处理的方法去除冗余的bbox(bounding box)。正是因为需要很多的人工干预、先验知识(Anchor)还有NMS,所以整个检测框架非常复杂,难调参难优化,并且部署困难(不是所有硬件都支持NMS,普通的库不一定支持NMS需要的算子)。所以说,一个端到端的目标检测是大家一直以来梦寐以求的。
DERT很好的解决了上述问题,利用Transformer全局建模的能力,把目标检测看成集合预测的问题,不需要proposal和anchors。而且由于Transformer全局建模的能力,DETR不会输出太多冗余的边界框,输出直接对应最后bbox,不需要nms进行后处理,大大简化了模型的训练和部署。
摘要
DETR有两个创新点
- 一是新的目标函数,通过二分图匹配的方式,强制模型对每个物体生只生成一个预测框
- 二是使用Transformer的编码器解码器架构
- 使用可学习的object query替代了生成anchor的机制。DETR可以将learned object query和全局图像信息结合起来,通过不停的做注意力操作,从而使得模型直接输出最后的预测框。
- 并行预测框。因为图像中目标没有依赖关系,并行输出使得速度更快。
DETR最主要的优点就是非常简单;性能也不错,在COCO数据集可以在精度、内存、速度上和Faster RCNN基线网络打平。另外,DETR可以非常简单的拓展到其他任务上。
1.引言
end-to-end
目标检测说白了就是一个集合预测问题,然而现在都是用间接的方式,如proposal的方式(Faster R-CNN、Mask R-CNN、Cascade R-CNN),anchors方式(YOLO、Focal loss),还有no anchor based 的方法(用物体中心点的Center Net、FCOS)。这些方法会生成冗余框,就会使用nms,性能很大受制于nms操作。
DETR利用Transformer这种全局建模的能力,直接把目标检测视为集合预测问题(即给定一张图像,预测图像中感兴趣物体的集合),把之前不可学习的东西(anchor、NMS)变成可学的东西,删掉了这些依赖先验知识的部分,从而得到了一个简单有效的端到端的网络。所以DETR不需要费尽心思的设计anchor,不需要NMS后处理,也就没有那么多超参需要调,也不需要复杂的算子。

DETR训练过程
- 使用CNN网络提取图片特征
- 学习全局特征:图片特征拉成一维,输入Transformer Encoder 中进行全局建模,进一步通过自注意力学习全局特征
- Transformer Encoder中的自注意力机制,使得图片中的每个点(特征)与图片中所有其他特征做交互,这样模型就能大致知道哪块区域是一个物体,哪块区域又是另一个物体,从而能够尽量保证每个物体只出一个预测框。所以说这种全局特征非常有利于移除冗余的框。
- 生成预测框。配合learned object query,用Transformer解码器生成N个预测框set of box prediction(默认取N=100,也就是一张图固定生成100个预测框)。
- 匹配预测框与GT框(真实框)。计算二分图匹配损失(bipartite matching loss),在匹配上的框里做目标检测的loss。
- 通过二分图匹配算法来选出与每个物体最匹配的预测框。比如上图中有两个物体,那么最后只有两个框和它们是最匹配的,归为前景;剩下98个都被标记为背景(no object)。最后和之前的目标检测算法一样,计算这两个框的分类损失和回归损失。
推理时,前三步是一样的。通过decoder生成N个预测框后,设置一个置信度阈值进行过滤,得到最终的预测框。比如设阈值=0.7,表示只输出置信度大于0.7的预测框,剩下都当做背景框。
优点
- 简单性:不仅框架简单,可以进行端到端的检测,而且只要硬件支持CNN和Transformer就一定可以支持DETR。
- 在COCO数据集上的性能,和一个训练好的Faster R-CNN baseline是差不多的,无论从内存、速度还是精度来说。
- 迁移性好:DETR框架可以很容易的拓展到其它任务上,比如在全景分割上的效果就很好(加个分割头就行)。
局限性
- DETR对大物体检测效果特别好,但是对小物体的检测效果不好(见实验4.1)。
前者归功于transformer可以进行全局建模,这样无论多大的物体都可以检测,而不像anchor based方法检测大物体时会受限于anchor的尺寸。后者是因为作者只是使用了一个简单的结构,很多目标检测的针对性设计还没有使用,比如多尺度特征、针对性的检测头。
- 训练太慢。
为了达到好的效果,作者在COCO上训练了500epoch,而一般模型训练几十个epoch就行了。
改进
DETR精度只有44 AP,比当时SOTA模型差了近10个点,但是想法特别好,解决了目标检测里面的很多痛点,所以影响还是很大的。而且其本身只是一个简单的模型,还有很多可以改进的。比如半年后提出的Deformable-DETR, 融入了多尺度特征,成功解决小物体检测效果不好的问题,还解决了训练慢的问题。
另外DETR不仅是一个目标检测方法,还是一个拓展性很强的框架。其设计理论,就是适用于更多复杂的任务,使其更加的简单,甚至使用一个框架解决所有问题。后续确实有一系列基于它的改进工作,比如Omni-DETR, up-DETR, PnP-DETR, SMAC-DETR, DAB-DETR, SAM-DETR, DN-DETR, OW-DETR, OV-DETR等等,将DETR应用在了目标追踪、视频领域的姿态预测、语义分割等多个视觉任务上。
2.相关工作
这一块介绍了三部分:
- 介绍之前的集合预测工作
- 如何使用Parallel Decoding让transformer并行预测
- 目标检测研究现状
现在研究都是基于初始预测进行检测,two stage 的方法基于proposal,signal stage的方法基于anchors(物体中心点)。
以前也有集合预测这一类的方法,可以做到每个物体只得到一个预测框,而不需要NMS。但是这些方法性能低,要不就是为了提高性能加了很多人工干预,显得复杂。
以前也有用encoder-decoder做检测,但都是17年以前的工作,用的是RNN的结构,效果和性能都不好(RNN自回归,效率慢)。
所以对比以前的工作发现,能让DETR工作的好最主要的原因就是使用了Transformer。比如上面两点,都是backbone学的特征不够好,模型效果性能都不好,才需要使用很多人工干预。 所以说DETR的成功,还是Transformer的成功。
3.DETR方法
3.1基于集合预测的目标函数
二分图匹配
detr模型最后输出是一个固定集合,无论图片是什么,最后都会n个输出(本文n=100)
问题:detr每次都会出100个输出,但是实际上一个图片的GT bounding box可能只有几个,怎么知道哪个预测框对应哪个 GT 框?
解决方法:二分图匹配
假设现在有 3 个工人和 4 个任务,由于每个工人的特长不一样,他们完成不同任务的时间(成本)也是不一样的,那如何分配任务能够使总的成本最低呢?匈牙利算法是解决该问题能够以较低的复杂度得到唯一的最优解。
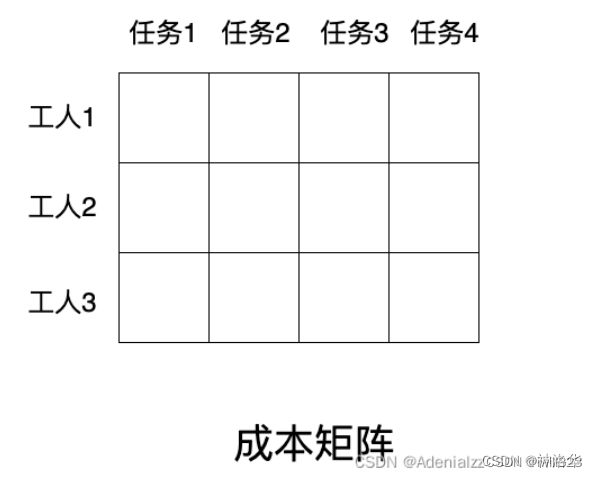
在 scipy 库中,已经封装好了匈牙利算法,只需要将成本矩阵(cost matrix)输入进去就能够得到最优的排列。在 DETR 的官方代码中,也是调用的这个函数进行匹配(from scipy.optimize import linear_sum_assignment)。输入为cost matrix,输出为最优的方案。
实际上,我们目前面对的 “从 N 个预测框中选出 M 个与 GT 对应的框” 的问题也可以视作二分图匹配的问题。而这里所谓的 “成本”,就是每个框与 GT 框之间的损失。
计算损失
cost matrix的损失由分类损失和边框损失组成。即:

遍历所有的预测框,都和GT 框去算这两个loss。其实找最优匹配的方式与之前把预测和proposal或anchors匹配的方式类似,但是这里约束更强,要的是 “一对一” 的对应关系,即强制要对每个物体只出一个框,因而不需要 NMS 的后处理。
This procedure of finding matching plays the same role as the heuristic assignment rules used to match proposal or anchors to ground truth objects in modern detectors. The main difference is that we need to find one-to-one matching for direct set prediction without duplicates
在确定了生成的100个框中哪几个与 GT 框对应之后,再按照常规的目标检测方式去计算损失函数:
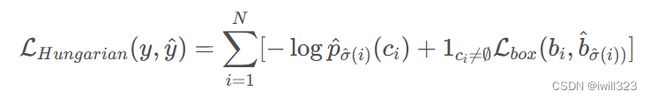
对于损失函数,DETR 还有两点小改动:
一是去掉分类损失中的log。对于分类损失(第一项),通常目标检测方法计算损失时是需要加 log 的,但是 DETR 中为了保证两项损失的数值区间接近,便于优化,选择了去掉 log ;
二是回归损失为L1 loss+GIOU。对于边框回归损失(后一项),通常方法只计算一个 L1 损失(预测框和真实框坐标的L1 损失),但是 DETR 中用 Transformer 提取的全局特征对大物体比较友好,经常出一些大框,而大框的 L1 损失会很大,不利于优化,因此作者这里还添加了一个 跟框大小无关的Generalized IoU 损失
所以整个步骤就是:
- 遍历所有的预测框和GT Box,计算其loss。
- 将loss构建为cost matrix,然后用scipy的linear_sum_assignment求出最优解,即找到每个GT Box最匹配的那个预测框。
- 计算最优的预测框和GT Box的损失
- 做梯度回传
3.2DETR模型架构

图像输入尺寸3×800×1066
- backbone 部分就是用 CNN (ResNet-50)去提取图像特征,得到 2048×25×34 大小的特征图(长和宽变为1/32),然后经过一个 1x1 Conv 降低一下通道数,得到特征尺寸为 256×25×34
- 将 CNN 特征加上一个同尺寸的位置编码(固定,尺寸为256×25×34 ),拉直为 850×256 ,送入 Transformer Encoder,输出850×256 的特征;
- 将得到的全局图像特征送入 Transformer Decoder,另一个输入的是 learned object query,尺寸是 100×256 ,256 对应特征尺寸,100 是要出框的个数 。在解码时,learned object query和全局图像特征不停地做across attention,最终得到的特征尺寸的为100×256
- 这里的object query相当于之前的anchor/proposal,是一个硬性条件,告诉模型最后只得到100个输出。
- learned object query是可学习的positional embedding,与模型参数一起根据梯度进行更新
- 100个输出通过检测头(目标检测中常用的全连接层FFN),输出100个预测框(xcenter,ycenter,w,h)和对应的类别。
The final prediction is computed by a 3-layer perceptron with ReLU activation function and hidden dimension d, and a linear projection layer. The FFN predicts the normalized center coordinates, height and width of the box w.r.t. the input image, and the linear layer predicts the class label using a softmax function.
- 使用二分图匹配方式输出最终的预测框,然后计算预测框和真实框的损失,梯度回传,更新网络。
除此之外还有部分细节:
- Transformer-encode/decoder都有6层
- 除第一层外,每层Transformer encoder里都会先计算object query的self-attention,主要是为了移除冗余框。这些query交互之后,大概就知道每个query会出哪种框,互相之间不会再重复(见实验)。
- decoder加了auxiliary loss,即6层decoder,每层的100×256输出,都送入FFN得到输出,然后去计算loss,这样模型收敛更快。每层FFN共享参数
We add prediction FFNs and Hungarian loss after each decoder layer. All predictions FFNs share their parameters. We use an additional shared layer-norm to normalize the input to the prediction FFNs from different decoder layers.
代码
为了说明端到端的 DETR 框架的简洁性,作者在论文末尾给出了 DETR 模型定义、推理的代码,总共不到 50 行。当然这个版本缺少了一些细节,但也完全能够展现出 DETR 的流程了。该版本直接用来训练,最终也能达到 40 的 AP,比DERT基线模型差两个AP。
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2]) # We take only convolutional layers from ResNet-50 model
self.conv = nn.Conv2d(2048, hidden_dim, 1) # 1×1卷积层将2048维特征降到256维
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers) # 输出100×256
self.linear_class = nn.Linear(hidden_dim, num_classes + 1) # 类别FFN
self.linear_bbox = nn.Linear(hidden_dim, 4) # 回归FFN
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # object query
# 下面两个是位置编码
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1) # 位置编码
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)预测类别为什么要+1:
Since we predict a fixed-size set of N bounding boxes, where N is usually much larger than the actual number of objects of interest in an image, an additional special class label ∅ is used to represent that no object is detected within a slot. This class plays a similar role to the “background” class in the standard object detection approaches.
4.实验部分
性能对比
下面的表格给出了 DETR 与基线 Faster RCNN 的定量性能对比。
最上面一部分的 Faster RCNN 的性能结果是 Detection2 的实现,之所以将 Faster RCNN 分成两部分,是因为 DETR 中使用了近年来很多新的训练 trick,如 GIoU loss、更强的数据增强策略、更长的训练时间,因此作者团队添加这些策略重新训练了 Faster RCNN,以作公平的对比。

- 近年来的新的训练策略对于目标检测模型的提升非常明显。
对比表格的第一、第二部分,重新训练的模型以+表示,只是用了更优的训练策略,基本能稳定涨两个点。
- 模型比 Faster RCNN 精度高一点,主要大物体检测出色
表格的后三列分别是小、中、大物体的检测性能,可以观察到 DETR 在大物体的检测上更出色(提升6个AP),但是对于小物体的检测甚至远不如 Faster RCNN(降低了4个AP左右)。
- 作者认为,得益于Transformer 结构的全局建模能力,且没有预置的固定 anchor 的限制,因此预测框想多大就多大,对大物体比较友好。
- DETR 在小物体上表现不佳,是因为本文中 DETR 的模型还是一个比较简单的模型,没有做很多针对目标检测的优化设计,比如针对小物体、多尺度的 FPN 设计。
- 参数量、计算量和推理速度之间并没有必然的关系。
#params、GFLOPS、FPS 分别表示了模型了参数量、计算量和推理速度。DETR模型参数量、GFLOPS更小,但是推理更慢。可能是由于硬件对于不同结构的优化程度有差异。目前来看, CNN 在同样网络规模甚至更大网络规模下,推理速度比 Transformer 更快。
encoder/decoder层数消融试验
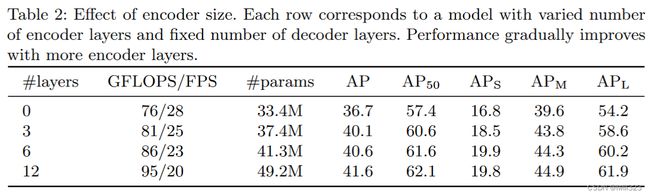
结果是层数越多效果越好,但是考虑到计算量,作者最后选择6层。其实3层也差不多
可视化
编码器自注意力图可视化
下图展示了对于一组参考点(图中红点)的 Encoder 注意力热力图的可视化,即计算参考点与图像中所有其他点自注意力值的大小。
可以观察到,Transformer Encoder 基本已经能够非常清晰地区分开各个物体了,甚至热力图已经有一点实例分割的 mask 图的意思了。在有一定遮挡的情况下(左侧两头牛),也能够清楚地分开哪个是哪个。
这种效果正是 Transformer Encoder 的全局建模能力所带来的,每个位置能够感知到图像中所有的其他位置,因此能够区分出图像中的不同物体,在这个基础上对一个物体只出一个预测框,就会简单很多,效果也更好。

解码器注意力图可视化
通过前面的可视化,我们已经看到,Encoder 学习了一个全局的特征,基本已经能够区分开图中不同的物体。但是对于目标检测来说,还需要精确的物体的边界框坐标,这部分就由 Decoder 来做。
下图在 Decoder 特征中对不同的物体做了注意力的可视化,比如左图中的两头大象分别由蓝色和橙色表示。可以观察到,Decoder 网络中对于每个物体的注意力都集中在物体的边界位置,如大象的鼻子、尾巴、象腿等处,另外DETR依然能够区分出每个斑马的轮廓并学到各个目标的条纹。作者认为这是 Decoder 在区分不同物体边界的极值点(extremities),encoder学一个全局的特征,让物体之间尽可能分得开,Decoder关注不同物体边界的具体位置,最终精准地预测出不同物体的边框位置。
object query可视化

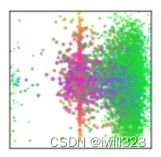
上图展示了 COCO2017 验证集中所有的预测框关于 learned object query 的可视化。者将100个object query中20个拿出来,每个正方形代表一个object query,每个点表示的是一个预测框的归一化中心坐标。每个object query相当于一个问问题的人,绿色的点表示小框、红色的点表示大的横向的框、蓝色的点表示大的纵向的框。
可以看到,每个 learned object query 其实是学习了一种 “查询” 物体的模式。比如下面第一个 query,就是负责查询图中左下角有没有一个小物体,中间有没有一个大的横向的物体;第二个 query 负责查询右边有没有小物体,经过100个不同object query查询完成后,目标也就检测完成了。从这个可视化实验可以看出,其实 learned object query 做的事情与 anchor 是类似的,就是去看某个位置有没有某种物体,只不过anchor 需要先验地手动设置,而query是与网络一起端到端学习的。
上图还可以看到,每张图中心都有红色的竖线,表示每个query都会检测图片中心是否有横向的大物体。这是因为COCO数据集图片中心往往都有一个大的物体,query则学到了这个模式,或者说分布。

5.结论
- DETR 用 learned object query 取代了 anchor 的设置,用二分图匹配的方式取代了 NMS 后处理,将之前不可学习的步骤都替换为可以学习的内容,从而实现了一个端到端的目标检测网络。
- 借助 Transformer 的全局特征交互能力,使得直接对每个物体“一对一”地输出一个可靠的预测结果成为了可能。
- 在COCO数据集上与Faster R-CNN基线模型打成平手,并且在全景分割任务上取得更好的结果。
- DETR在大物体上效果非常好
- 最主要的优势是简单,可以有很大的潜能应用在别的任务上。
- 缺点:推理时间有点长、由于使用了Transformer不好优化、小物体上性能也差一些。后来,Deformable DETR解决了推理时间和小物体检测差的不足。
虽然 DETR 本身检测性能并不突出,但是由于它切实解决了目标检测领域的一些痛点,提出了一个新的端到端的检测框架,随后就有一系列跟进工作把它的性能提了上来。
后续工作:omni-DETR;up-DETR;PnP-DETR;SMAC-DETR;Deformer-DETR;DAB-DETR;SAM-DETR;DN-DETR;OW-DETR;OV-DETR